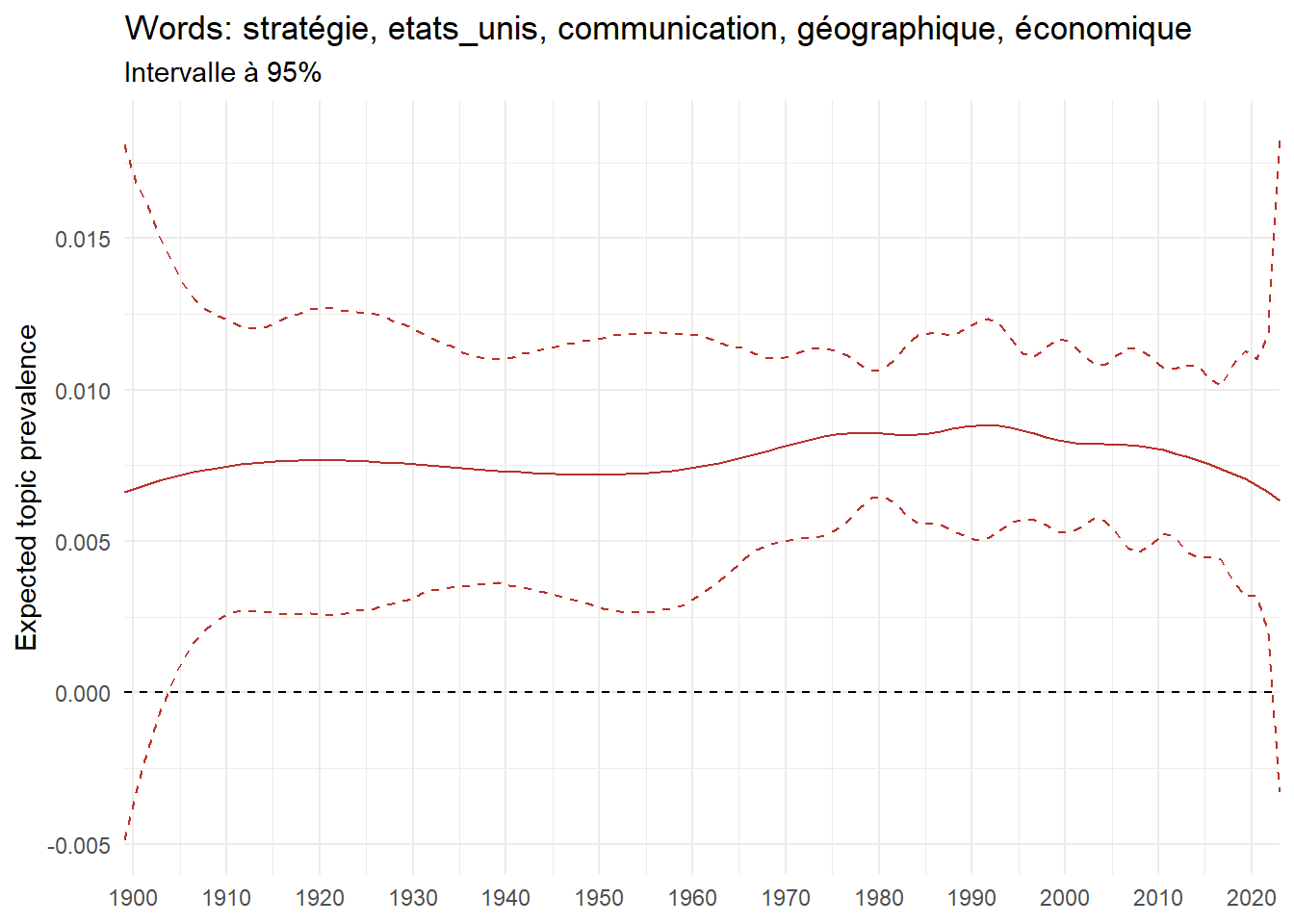
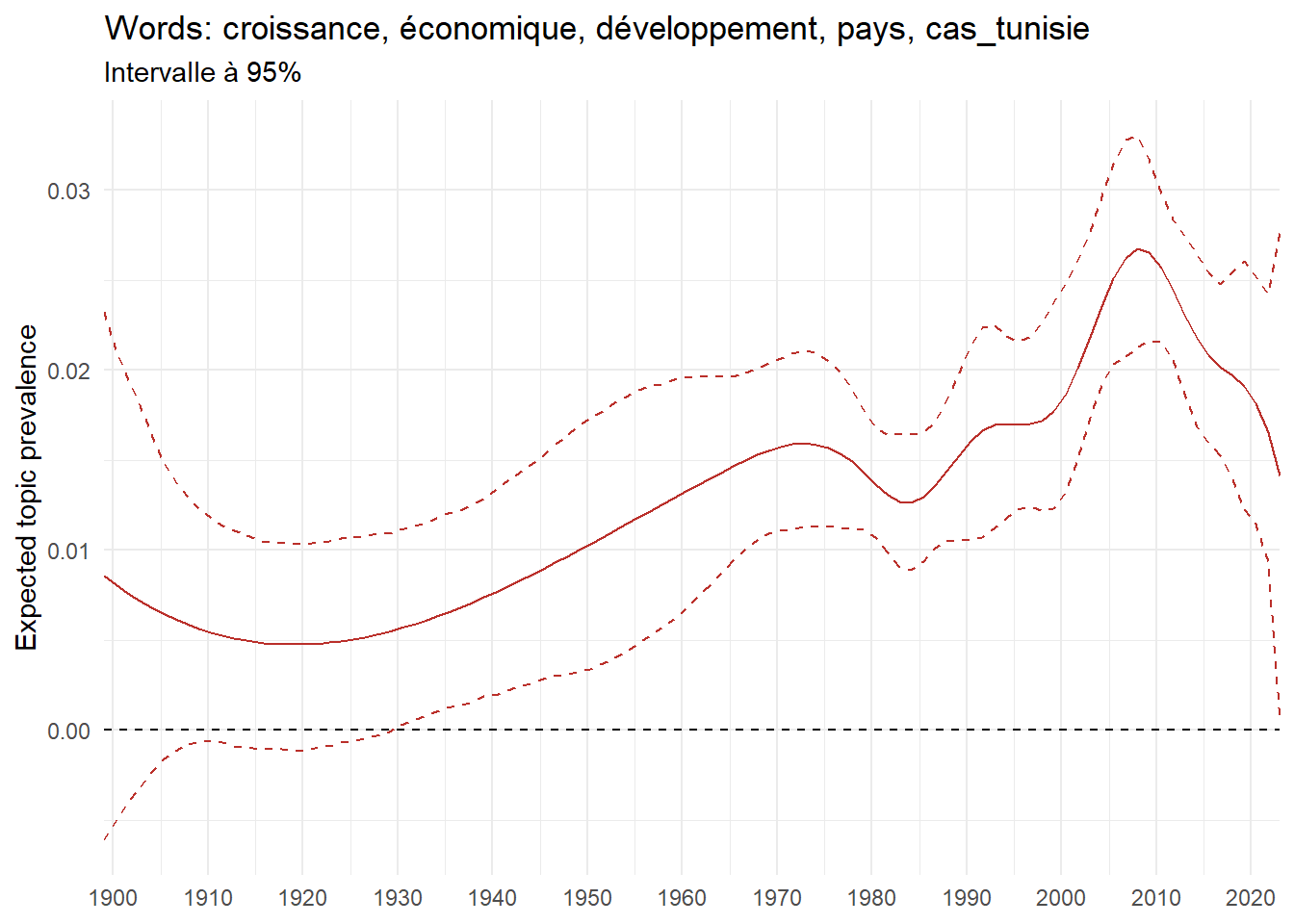
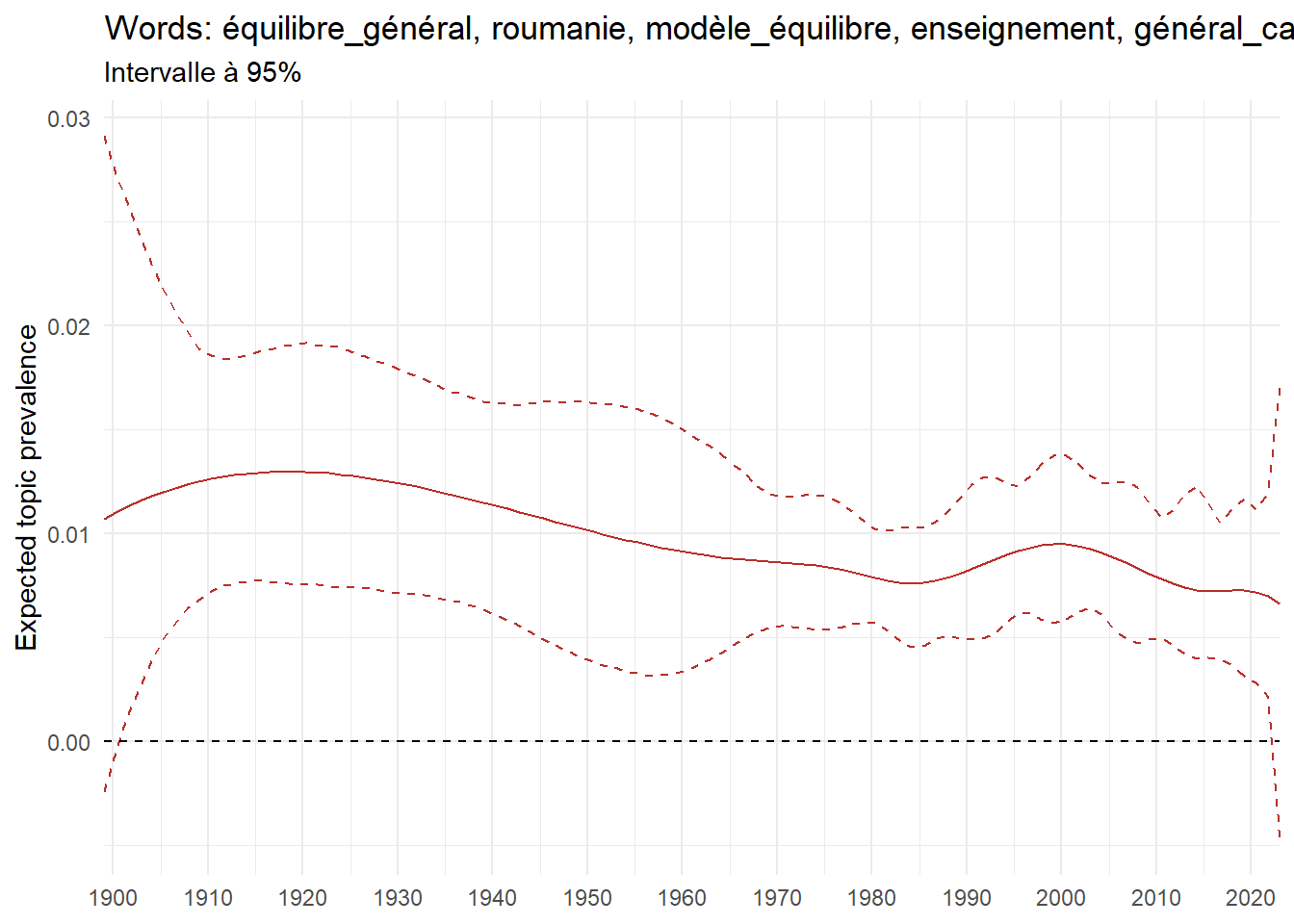
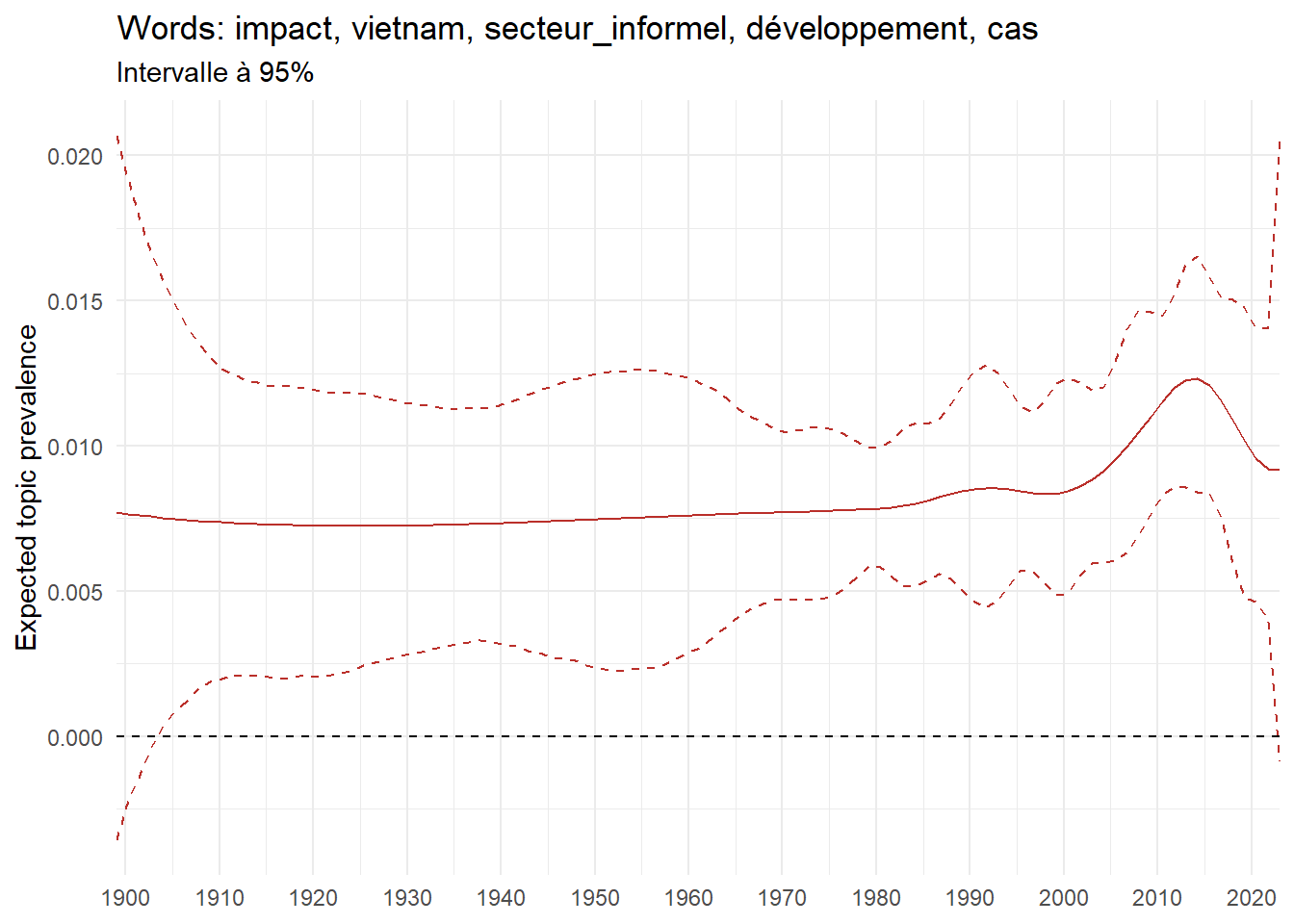
Exploring trendy topics in French Ph.D. (1900-2023)
French data
Authors
Affiliations
Thomas Delcey
Université de Bourgogne
Aurelien Goutsmedt
UC Louvain; ICHEC
Published
September 15, 2025
In this first blog article, we explore the evolution of topics of French theses over the 20th and early 21st centuries.
Exploring data
Note that the French sources used to create our database contained duplicate theses. It is necessary to address these duplicates appropriately before conducting any analysis. Duplicates can be easily identified using the duplicates column in the thesis_metadata table. In the example script below, we identify duplicate entries and retain the record with the most recent year_defence, assuming that the most recent version of the thesis is the most relevant.1
Show the code
thesis_metadata <-readRDS(here(FR_cleaned_data_path, "thesis_metadata.rds"))# PRE-CLEANING # manage duplicateduplicates <- thesis_metadata %>%filter(!is.na(duplicates)) %>%group_by(duplicates) %>%# when the line has a duplicate, group and keep the older valueslice_min(year_defence, n =1, with_ties =FALSE)thesis_metadata_no_duplicate <- thesis_metadata %>%filter(is.na(duplicates)) %>%bind_rows(duplicates)
The primary textual data providing information on thesis topics are the titles (title_fr and title_en) and the abstracts (abstract_fr and abstract_en). The first question to consider is the choice of language. Historically, French PhD theses were predominantly written in French. Over time, however, they were increasingly translated into English or even primarily written in English.
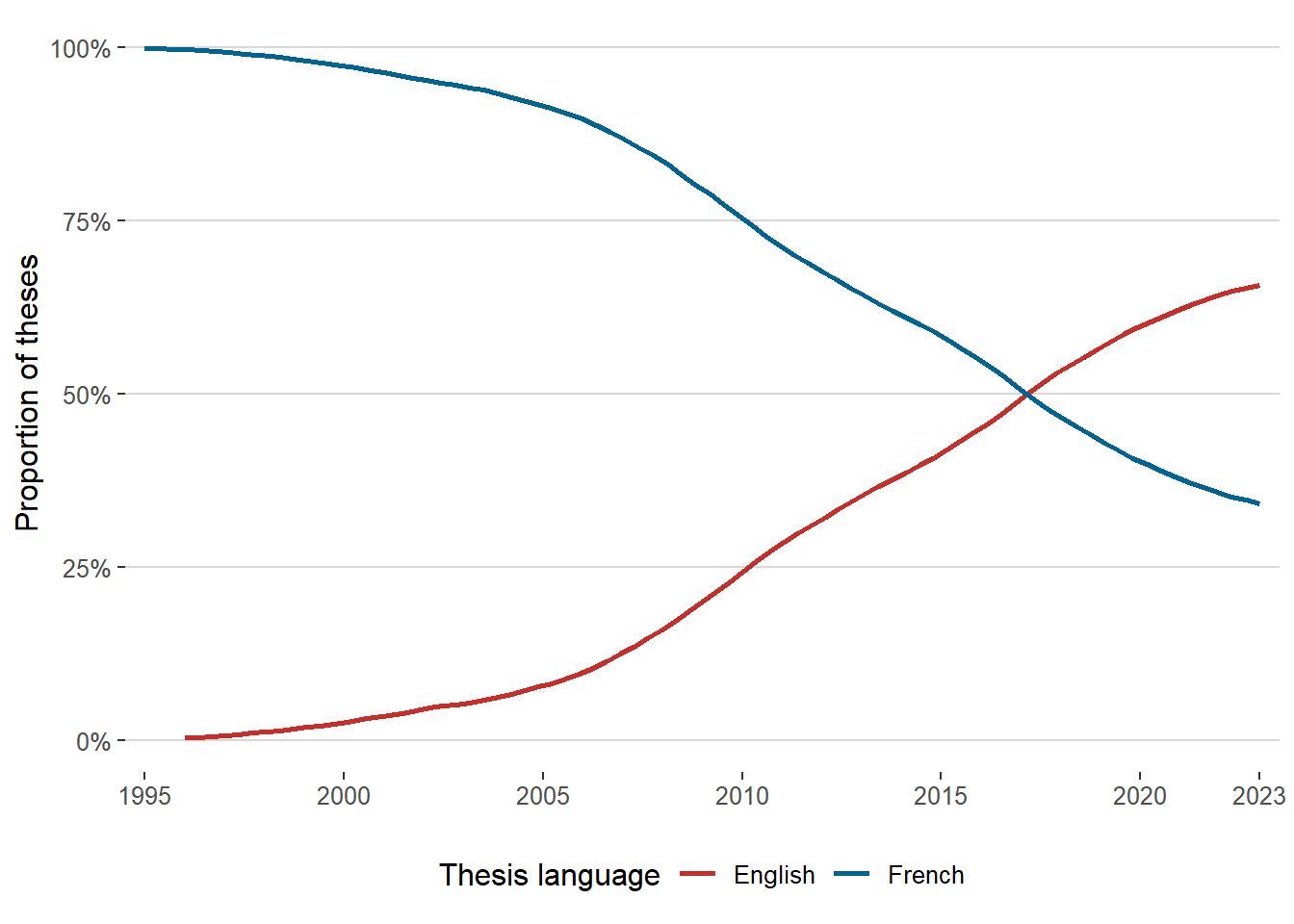
To determine the main language of a thesis, one can refer to the language variable. This variable is sourced directly from Sudoc and Theses.fr, and it reflects the primary language of the thesis. As shown in Figure 1, English has become the predominant language for French PhD students, but this shift has occurred only recently. Additionally, theses in English are often accompanied by a French translation of the title and abstract. Therefore, to analyze the evolution of topics over an extended period, the French textual data are more relevant.
Show the code
data_summary <- thesis_metadata_no_duplicate %>%# if language is not fr or en, becomes "other"mutate(language =ifelse(str_detect(language, "fr|en"), language, "other"),language =ifelse(!is.na(language), language, "other")) %>%# calculate share of each languages by year add_count(year_defence, name ="freq_thesis") %>%count(language, year_defence, freq_thesis, name ="freq_language") %>%mutate(share = freq_language/freq_thesis) %>%filter(year_defence >1994) # plot plot <- data_summary %>%filter(language !="other") %>%ggplot(aes(x = year_defence, y = share, color = language)) +geom_smooth(method ="loess", se =FALSE, span =0.5) +scale_color_wsj(labels =c("English", "French")) +scale_y_continuous(labels =percent_format()) +scale_x_continuous(breaks =c(seq(1995, 2020, 5), 2023), expand =c(0,0.5)) +theme_hc() +labs(x =NULL,y ="Proportion of theses",color ="Thesis language")print(plot)
Figure 1: In which language are the theses written?
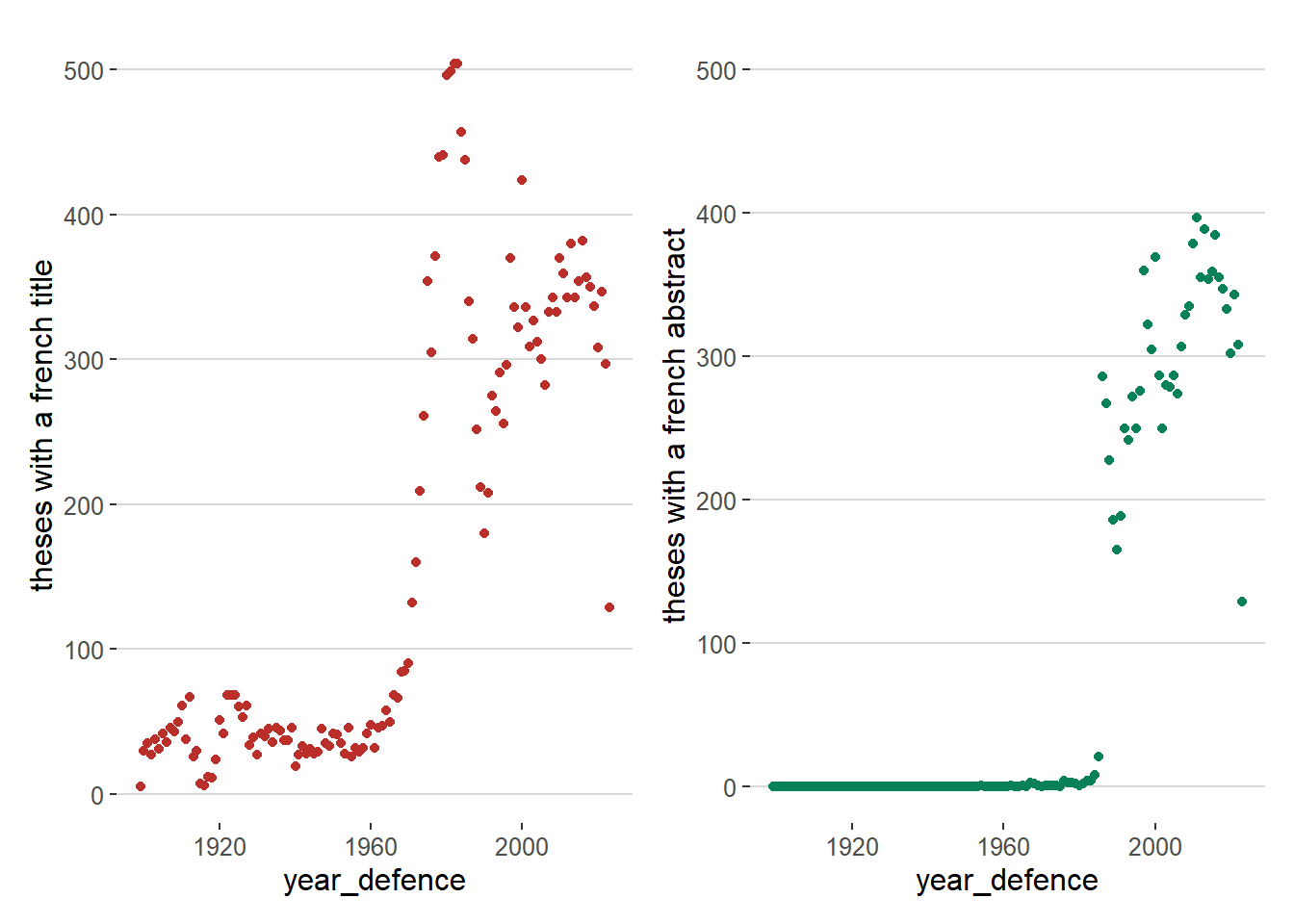
While abstracts are undoubtedly a richer source of textual data, they are less rarely available. As shown in Figure 2, writing an abstract only became common practice starting from the 1970s. In this blog article, we will thus exploit only the title_fr column to understand the evolution of topics from 1900.
Show the code
# abstract availabledata_summary <- thesis_metadata_no_duplicate %>%mutate(title_available =ifelse(!is.na(title_fr), 1, 0),ab_available =ifelse(!is.na(abstract_fr), 1, 0)) %>%# add_count(title_available, year_defence, name = "n_title") %>%# add_count(ab_available, year_defence, name = "n_ab") %>%mutate(n_ab =sum(ab_available),n_title =sum(title_available),.by ="year_defence")# distribution p1 <- data_summary %>%# filter(ab_available == 1) %>%ggplot() +geom_point(aes(x = year_defence, y = n_ab), color = ggthemes_data$wsj$palettes$red_green$value[1]) +labs(color ="",y ="theses with a french abstract") +theme_hc() +scale_y_continuous(limits =c(0, max(data_summary$n_title)))p2 <- data_summary %>%# filter(title_available == 1) %>%ggplot() +geom_point(aes(x = year_defence, y = n_title), color = ggthemes_data$wsj$palettes$red_green$value[2]) +labs(color ="",y ="theses with a french title") +theme_hc()p2 + p1
Figure 2: Availability of titles or abstracts
Running the structural topic model
To identify “trendy topics” in our data, we use the structural topic model, a probabilistic topic model implemented in R through the stm package.
Probabilistic topic models are a class of machine learning models designed to classify textual data into topics. In such models:
Documents are topic mixtures: Each document is represented as a mixture of \(K\) topics. For each document, the model estimates the probability that the document contains a given topic \(k\). This is referred to as topic prevalence, denoted as \(\theta_{1:D}\) where \(\theta_{d}\) represents the probability distribution over topics for document \(d\).
Topics are word mixtures: Each topic is represented as a mixture of words from the corpus vocabulary, which is the list of unique words used in the entire corpus. For each topic, the model estimates the probability that a particular word belongs to that topic. This is referred to as topic content, denoted as \(\beta_{1:K}\) where \(\beta_{k}\) represents the probability distribution over the vocabulary for topic \(k\).
These probabilities are estimated using a generative process. Intuitively, a topic model initializes the topic prevalence and topic content, uses them to generate a simulated corpus of documents, and then compares this simulated corpus to the observed one to adjust the topic prevalence and content. The input to a topic model is the document frequency matrix (DFM), also referred to as the document-term matrix. In this matrix, rows represent documents, columns represent unique words in the vocabulary, and cell values indicate the frequency of each word in a given document. The model evaluates how well the current \(\theta_{1:D}\) and \(\beta_{1:K}\) fit the corpus distribution and iteratively updates these parameters to improve the fit. For a comprehensive presentation of the generative and training process, see Blei (2012).
The stm package (Roberts et al. 2013) implemented a topic model whose main feature is to offer a framework to explore the relationship between the metadata of the documents and the prevalence of topics. The metadata helps in training a topic model and in estimating the topic prevalence over documents. Regression analysis allows to measure precisely the controlled effect of each metadata on topics prevalence.
To train our topic model, we must first prepare the data by constructing the document frequency matrix (DFM), which serves as the primary input for the stm package. This process begins with tokenization—the identification of individual words in title_fr. Tokenization typically also includes transforming the data by removing irrelevant words, such as stopwords, to improve the quality of the analysis and computational efficiency.
In the script below, we include bigrams, which are pairs of words, when they frequently co-occur. For example, in acorpus containing economic documents, the words “interest” and “rates” might be combined into the term “interest_rates” as they often go together.
We finally run a structural topic model for \(K = 100\).2
Show the code
# ----------------------------------# STEP 1: DATA PREPARATION# ----------------------------------# Select relevant variables from the dataset# Retain only rows with non-missing titles and defense years.data <- thesis_metadata_no_duplicate %>%select(thesis_id, title_fr, abstract_fr, year_defence) %>%filter(!is.na(title_fr), !is.na(year_defence))# ----------------------------------# STEP 2: TOKENIZATION AND PARSING# ----------------------------------# Initialize the spaCy model for French# Ensure spaCy is installed and the French language model is downloaded.# spacy_install(force = TRUE)# spacy_download_langmodel("fr_core_news_lg", force = TRUE)spacy_initialize("fr_core_news_lg")# Parse titles using spaCy# Perform pre-cleaning on French titles.parsed <- data %>%mutate(title_fr =str_to_lower(title_fr),title_fr =str_replace_all(title_fr, "", " ") %>%str_replace_all(., "", " "),title_fr =str_replace_all(title_fr, "-", " "),title_fr =str_remove_all(title_fr, "thèse soutenue le .*"),title_fr =str_remove_all(title_fr, "thèse pour le doctorat"),title_fr =str_squish(title_fr) ) %>%pull(title_fr) %>% spacyr::spacy_parse(multithread =TRUE)# Map thesis IDs to the parsed tokensid <- data %>%distinct(thesis_id) %>%ungroup() %>%mutate(doc_id =paste0("text", 1:n()))parsed <- parsed %>%left_join(id, join_by(doc_id)) %>%select(-doc_id)# ----------------------------------# STEP 3: TOKEN FILTERING AND CLEANING# ----------------------------------# Load stop words for filteringstop_words <-bind_rows(get_stopwords(language ="fr", source ="stopwords-iso"),get_stopwords(language ="fr", source ="snowball"),get_stopwords(language ="en", source ="snowball")) %>%distinct(word) %>%pull(word)# Filter and clean tokens, tracking document removalsparsed_filtered <- parsed %>%# Count original idsmutate(original_count =n_distinct(thesis_id)) %>%# Filter empty tokens and track removed idsfilter(!pos %in%c("PUNCT", "SYM", "SPACE")) %>%mutate(after_filter1 =n_distinct(thesis_id)) %>% { message("Doc removed after filter: ", unique(.$original_count) -unique(.$after_filter1)); . } %>%filter(!token %in%c("-", "δ", "α", "σ", "γ", "東一")) %>%mutate(after_filter2 =n_distinct(thesis_id)) %>% { message("Doc removed after filter: ", unique(.$after_filter2) -unique(.$after_filter1)); . } %>%# remove any digit token (including those with letters after digits such as 12eme)filter(!str_detect(token, "^\\d+.*$")) %>%mutate(after_filter3 =n_distinct(thesis_id)) %>% { message("Doc removed after filter: ", unique(.$after_filter3) -unique(.$after_filter2)); . } %>%# Remove pronouns and special charactersmutate(token =str_remove_all(token, "^[ld]'"),token =str_remove_all(token, "[[:punct:]]")) %>%# Filter single letters and stopwordsfilter(str_detect(token, "[[:letter:]]{2}")) %>%mutate(after_filter4 =n_distinct(thesis_id)) %>% { message("Doc removed after filter: ", unique(.$after_filter3) -unique(.$after_filter4)); . } %>%filter(!token %in% stop_words) %>%mutate(after_filter5 =n_distinct(thesis_id)) %>% { message("Doc removed after filter: ", unique(.$after_filter5) -unique(.$after_filter4)); . } %>%# Create bigramsgroup_by(thesis_id, sentence_id) %>%mutate(bigram =ifelse(token_id <lead(token_id), str_c(token, lead(token), sep ="_"), NA)) %>%ungroup()# ----------------------------------# STEP 4: BIGRAM CREATION AND FILTERING# ----------------------------------# Create and filter bigrams based on frequency and PMIbigrams <- parsed_filtered %>%select(thesis_id, sentence_id, token_id, bigram) %>%filter(!is.na(bigram)) %>%mutate(window_id =1:n()) %>%add_count(bigram) %>%filter(n >10) %>%separate(bigram, c("word_1", "word_2"), sep ="_") %>%filter(if_all(starts_with("word"), ~! . %in% stop_words))bigram_pmi_values <- bigrams %>%pivot_longer(cols =starts_with("word"), names_to ="rank", values_to ="word") %>%mutate(word =paste0(rank, "_", word)) %>%select(window_id, word, rank) %>% widyr::pairwise_pmi(word, window_id) %>%arrange(item1, pmi) %>%filter(str_detect(item1, "word_1")) %>%mutate(across(starts_with("item"), ~str_remove(., "word_(1|2)_"))) %>%rename(word_1 = item1,word_2 = item2,pmi_bigram = pmi) %>%group_by(word_1) %>%mutate(rank_pmi_bigram =1:n())bigrams_to_keep <- bigrams %>%left_join(bigram_pmi_values) %>%filter(pmi_bigram >3) %>%mutate(bigram =paste0(word_1, "_", word_2)) %>%distinct(bigram) %>%mutate(keep_bigram =TRUE)parsed_final <- parsed_filtered %>%left_join(bigrams_to_keep) %>%mutate(token =if_else(keep_bigram, bigram, token, missing = token),token =if_else(lag(keep_bigram), lag(bigram), token, missing = token),token_id =if_else(lag(keep_bigram), token_id -1, token_id, missing = token_id)) %>%distinct(thesis_id, sentence_id, token_id, token)term_list <- parsed_final %>%rename(term = token)# ----------------------------------# STEP 5: STM INPUT PREPARATION# ----------------------------------# Prepare metadata for STMmetadata <- term_list %>%distinct(thesis_id) %>%left_join(data, by ="thesis_id") %>%mutate(year_defence =as.numeric(year_defence)) %>%distinct(thesis_id, title_fr, year_defence) %>%# filter lines with na covariates filter(!is.na(title_fr),!is.na(year_defence))# Convert term list to STM-ready formatcorpus_in_dfm <- term_list %>%# remove observations deleted by the metadata filter filter(thesis_id %in% metadata$thesis_id) %>%add_count(term, thesis_id) %>%cast_dfm(thesis_id, term, n)corpus_in_stm <- quanteda::convert(corpus_in_dfm, to ="stm", docvars = metadata)# ----------------------------------# STEP 6: RUNNING THE STM# ----------------------------------# Define the STM formula with a spline functionformula_str <-paste("~ s(year_defence)")formula_obj <-as.formula(formula_str)# Run the STM with specified parametersstm <-stm(documents = corpus_in_stm$documents,vocab = corpus_in_stm$vocab,prevalence = formula_obj,data = corpus_in_stm$meta,K =100, # given that there is 20 000 documents, K = 100 is a good start init.type ="Spectral",verbose =TRUE,seed =123 )
Analysis
For each thesis, the topic model assigns a prevalence score to each topic, indicating the probability that a specific topic is present in the thesis. Averaging these probabilities across all theses yields the average prevalence, which can provide insights into the main topics appearing in theses titles. Figure 3 shows the top 20 average prevalence; for each topic we assign the most probable words from the topic content (the \(\beta_{1:K}\) distributions). For instance, among the most prevalent topics, many are related to development economics.
Figure 3: Topics with highest average prevalence
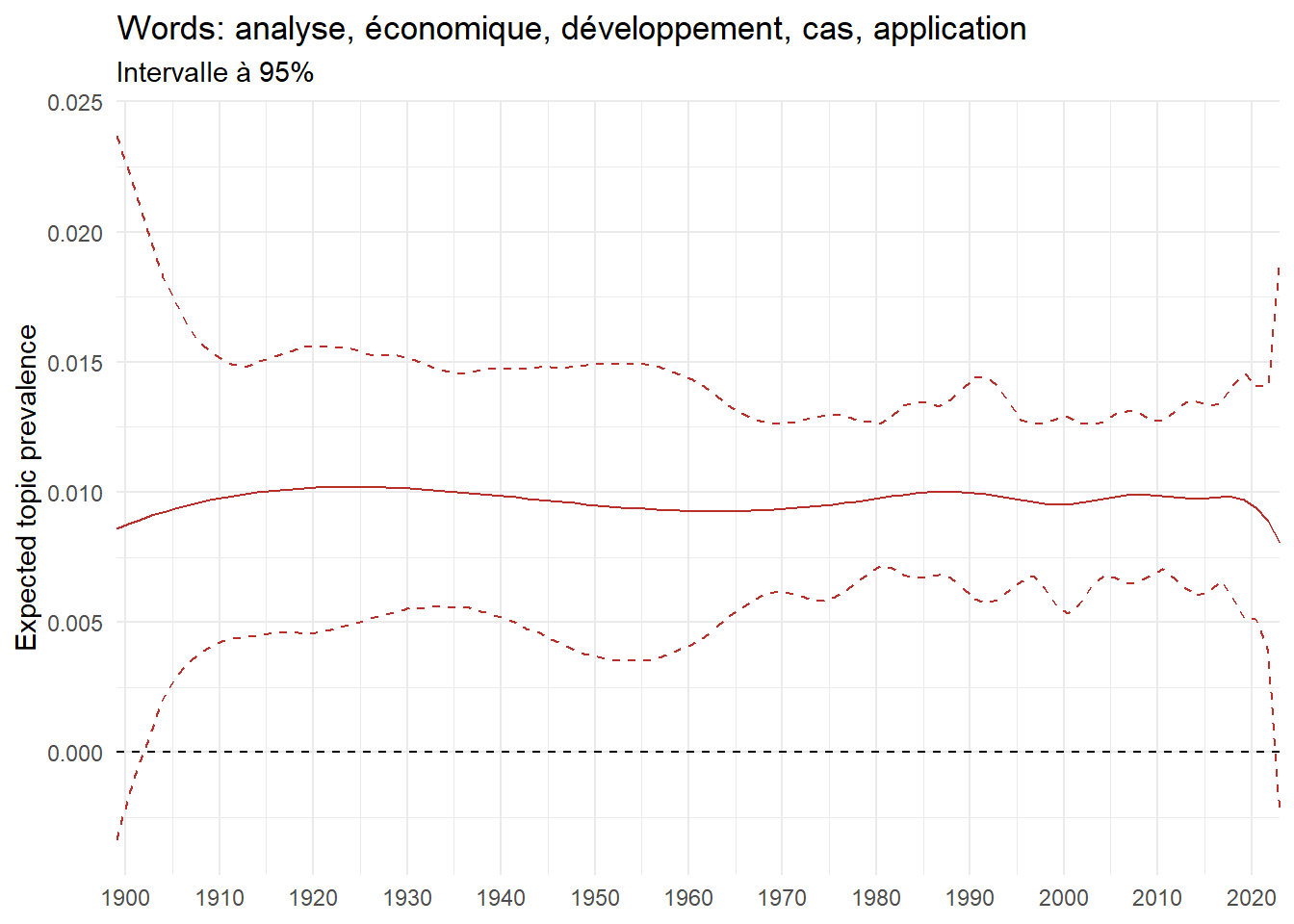
The average prevalence provides important insights into key topics but is insufficient for analyzing how this prevalence evolves over time. A straightforward way to capture the evolution of topics over time is simply to calculate the average prevalence by year (year_defence). A more sophisticated approach leverages the features of the stm framework to predict the prevalence of each topic based on year_defence. In this case, the goal is not merely to describe the average prevalence in a given year but to estimate the effect of a specific year on topic prevalence. This can be expressed using the following regression model:
\[ \theta_{d,k} = \beta_0 + \beta_1 * year_d + \epsilon_{d,k} \] This regression approach allows for statistical inference by quantifying the strength and significance of the relationship between the year (year_defence) and topic prevalence. This enables us to formally test whether changes in prevalence over time are statistically meaningful, rather than merely observing trends in the data. Figure 4 compares the result of both analyses.
Show the code
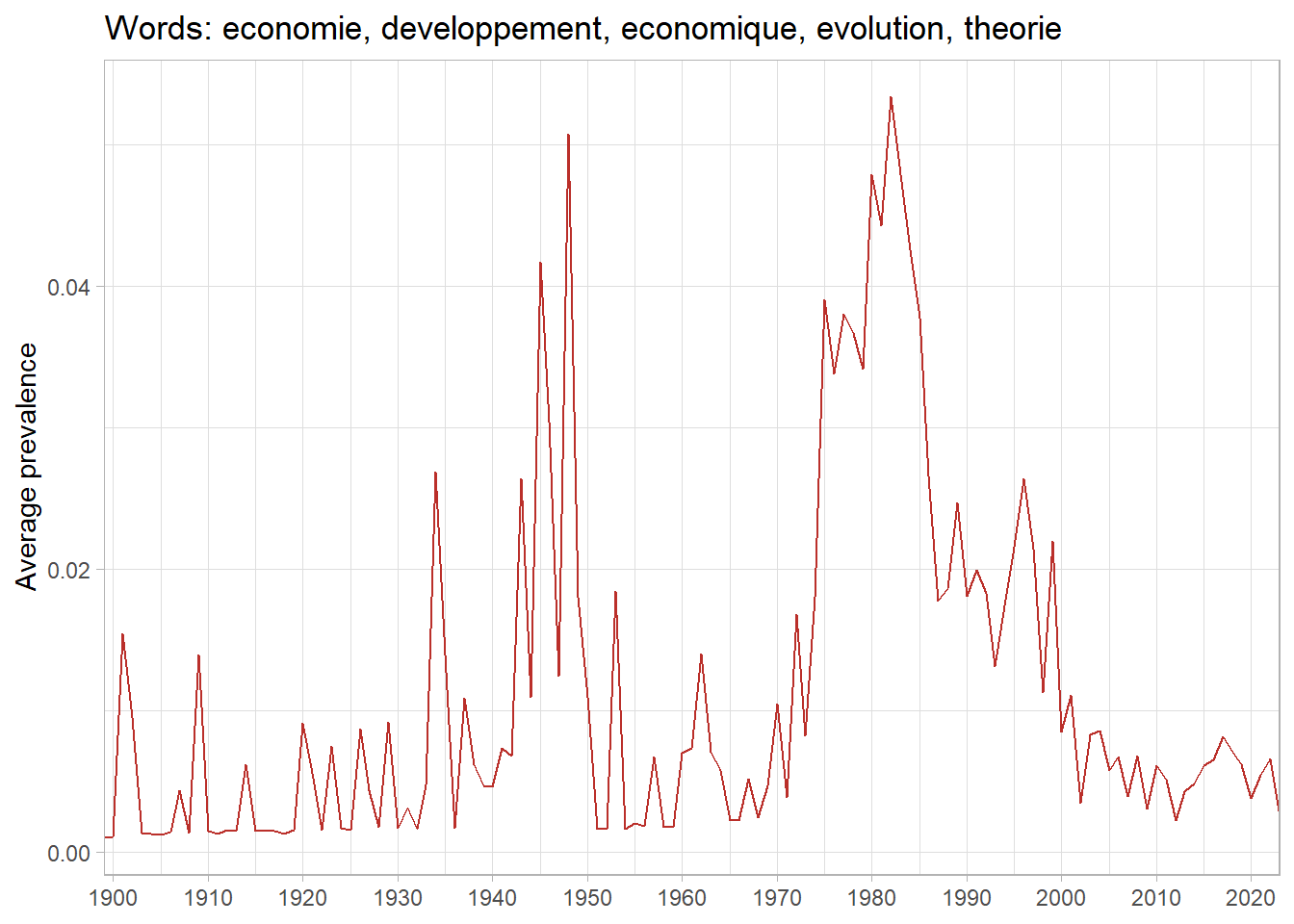
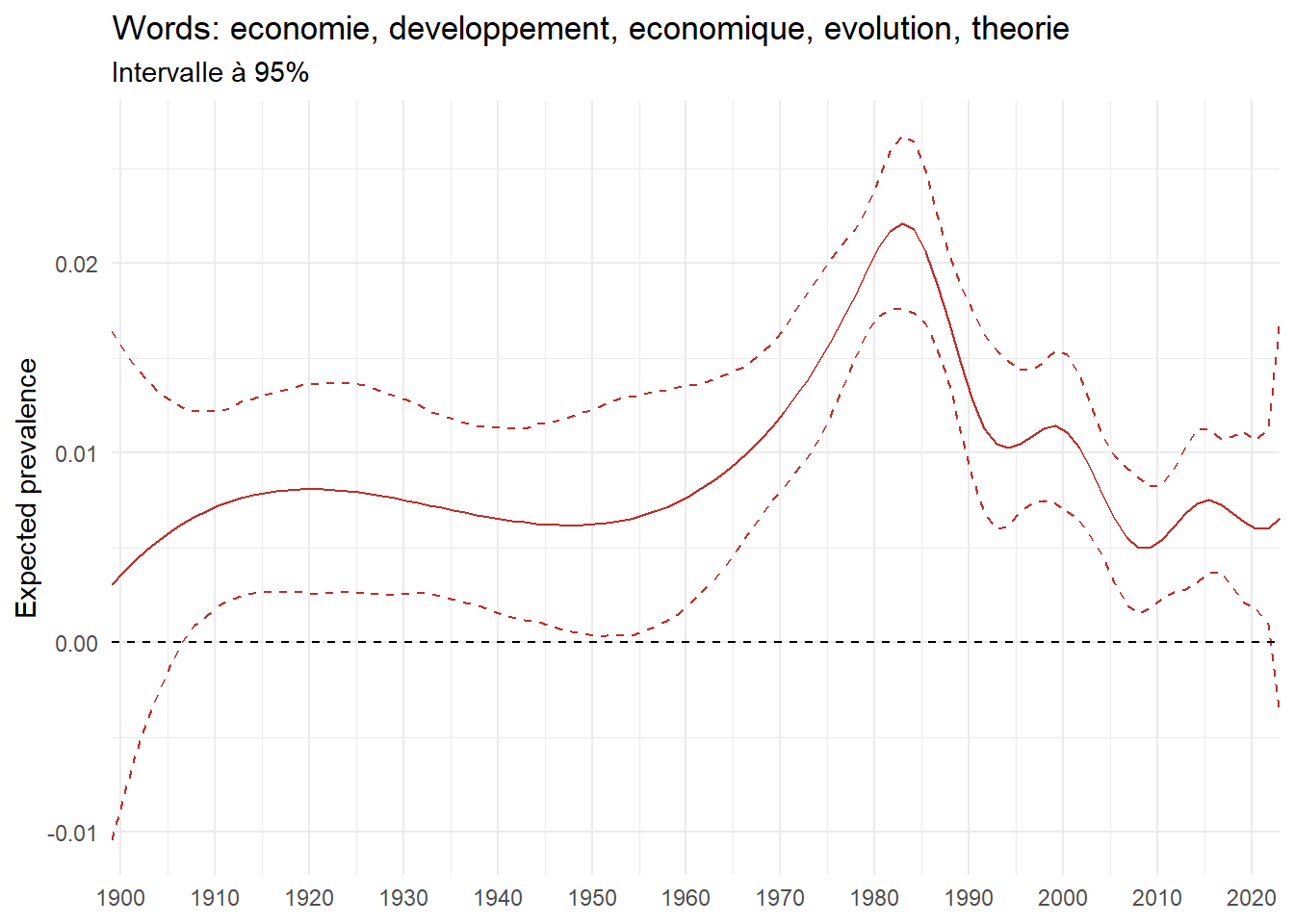
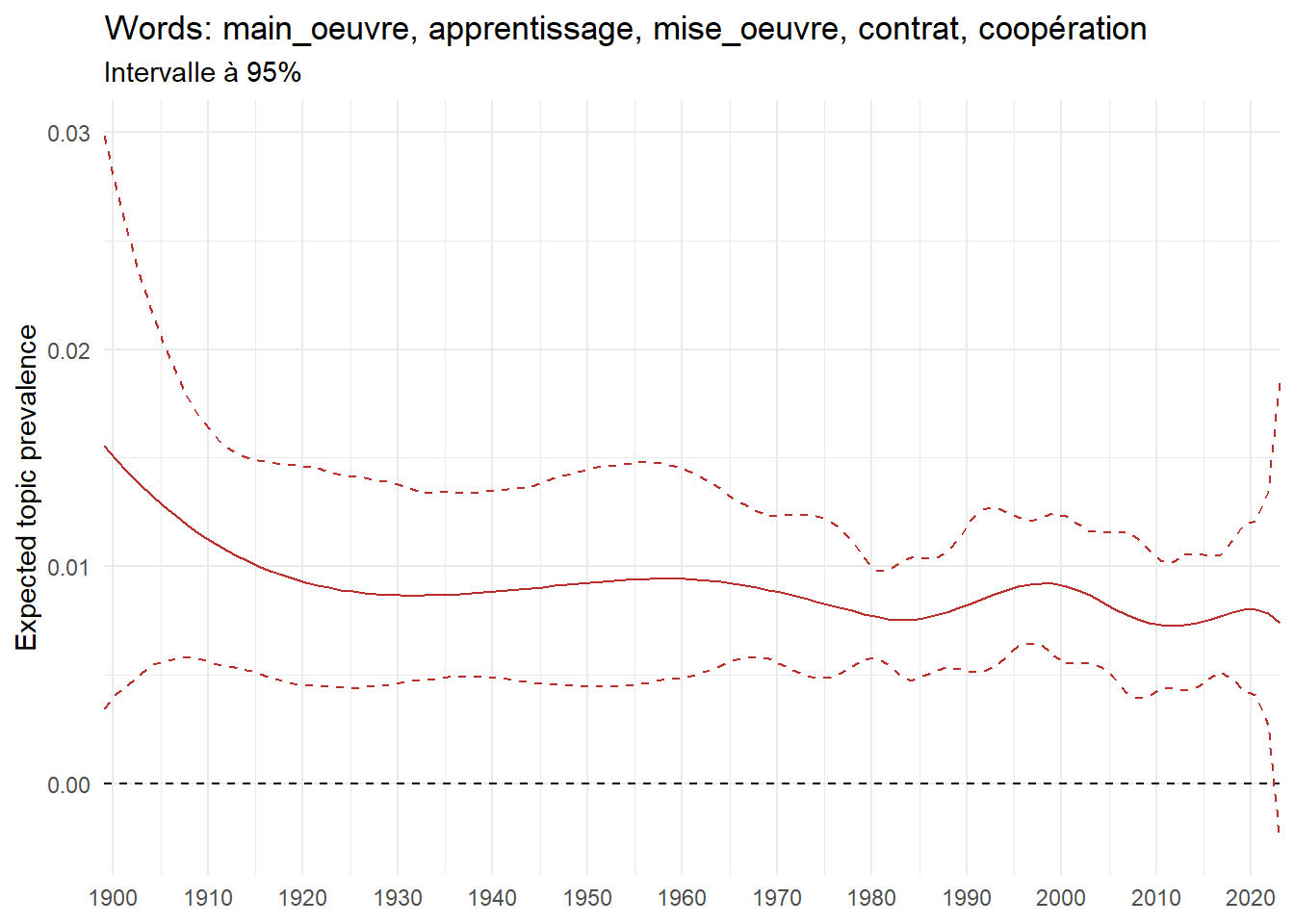
metadata <- corpus_in_stm$meta %>% as_tibble %>%mutate(year_defence =as.numeric(year_defence),document =row_number()) %>%select(year_defence, document)# tidy call gamma the prevalence matrix, stm calls it thetatheta <- broom::tidy(stm, matrix ="gamma") %>%# broom called stm theta matrix gammaleft_join(top_terms_prob, by ="topic") %>%left_join(metadata, by ="document")# calulate average mean by year for topic 63 theta_mean_63 <- theta %>%filter(topic ==63) %>%group_by(topic, topic_label_prob, year_defence) %>%reframe(theta_mean =mean(gamma))#plot plot1 <- theta_mean_63 %>%ggplot(aes(x = year_defence, y = theta_mean)) +geom_line(color = ggthemes_data$wsj$palettes$red_green$value[2]) +labs(y ="Average prevalence", x =NULL,title =paste("Words:", unique(theta_mean_63$topic_label_prob))) +scale_x_continuous(expand =c(0,0), breaks =seq(1900, 2020, 10)) +theme_light()ee_date_63 <- tidystm::extract.estimateEffect( estimate_effect,"year_defence", stm,method ="continuous",# uncomment if you had an interaction effect# moderator = "gender_expanded",# moderator.value = c("male", "female") ) %>%left_join(top_terms_prob, by ="topic") %>%filter(topic ==63) plot2 <- ee_date_63 %>%ggplot(aes(x = covariate.value)) +geom_line(aes(y = estimate), color = ggthemes_data$wsj$palettes$red_green$value[2]) +geom_line(aes(y = ci.lower), linetype ="dashed", color = ggthemes_data$wsj$palettes$red_green$value[2]) +geom_line(aes(y = ci.upper), linetype ="dashed", color = ggthemes_data$wsj$palettes$red_green$value[2]) +geom_hline(yintercept =0,linetype ="dashed",color ="black") +scale_x_continuous(expand =c(0,0), breaks =seq(1900, 2020, 10)) +labs(title =paste("Words:", unique(ee_date_63$topic_label)),subtitle ="Intervalle à 95%",x =NULL,y ="Expected prevalence" ) +theme_minimal() +theme(strip.text =element_text(size =3))print(plot1)print(plot2)
(a) Average prevalence
(b) Predicted prevalence
Figure 4: Prevalence over time
Note also that by applying a spline function to year_defence, this method is still able to capture the non-linear behavior of prevalence over time with greater precision. Check Note 1 if you are interested in the methodology behind spline effect.
Note 1: The b-spline function
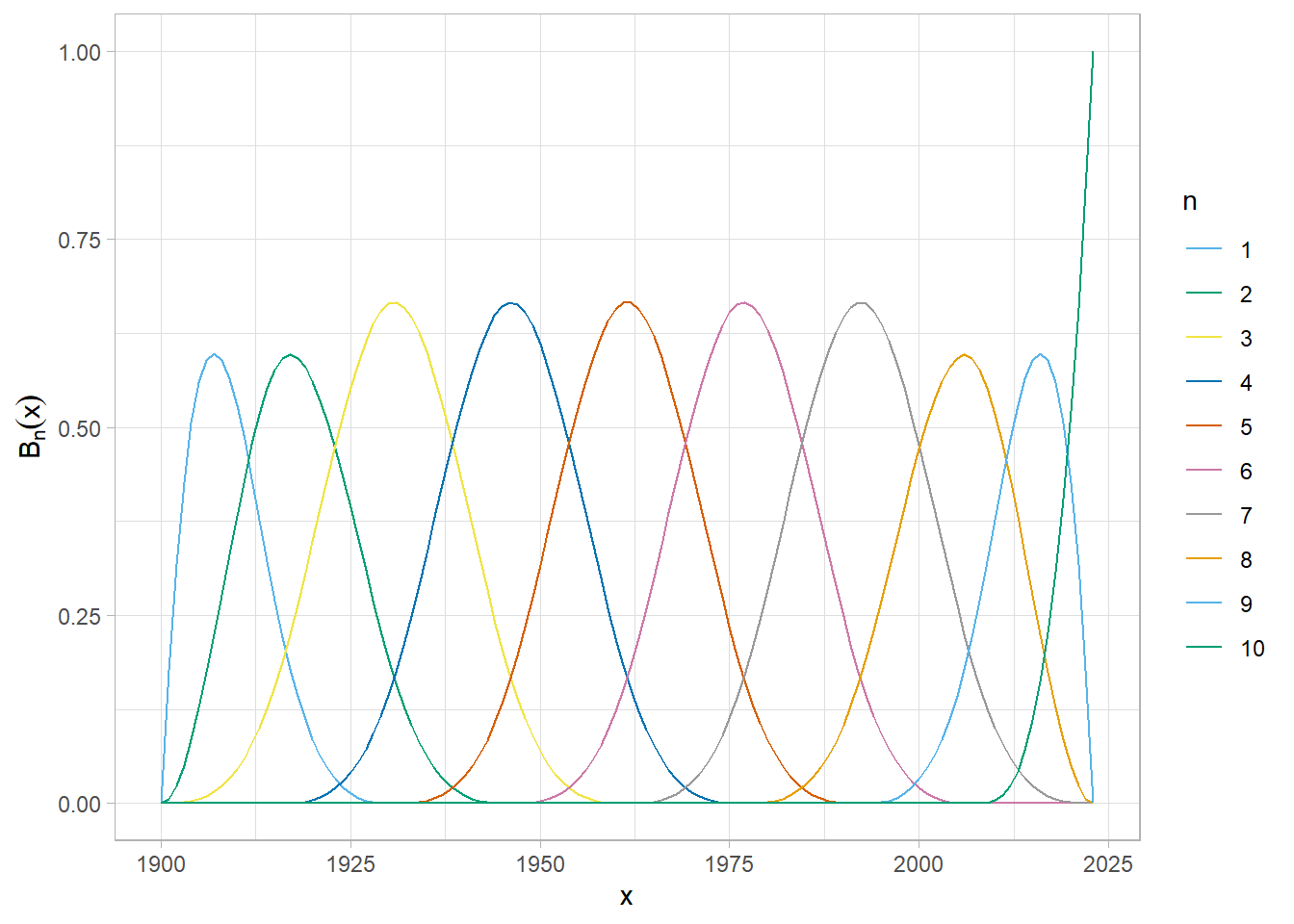
In a linear model, the estimator \(\beta_1\) for a time variable, such as years, measures the marginal effect of an additional year on the expected prevalence of the topic. This linearity does not allow for the identification of non-linear effects, such as a high prevalence during the 1990s followed by a decline. To address this, we apply a b-spline function to the year to capture potential non-linear effects. Formally, our estimator for the variable \(year_d\) becomes a linear combination of \(n\) estimators and polynomial functions \(B(x)\), also known in this context as basis functions.
\[\beta_1 * year_d = \sum_1^n \alpha_1 \times B_{1}(year_d) + ... + \alpha_{n}\times B_{n}(year_d)\] This B-spline transformation is performed in R using the function stm::s(df = 10), a wrapper for the splines::bs() function.
Figure 5: Les fonctions de base d’une transformation b-spline pour n = 10
The drawback of such an approach is that the estimators \(\alpha_1 ... \alpha_n\) are not interpretable. Each coefficient represents the weight of a polynomial function \(B_n\) in the total prevalence. Rather than focusing on the regression table, it is more insightful to directly calculate the model’s expected prevalence.
The regression model is estimated using the stm::estimateEffect() function. While the regression could alternatively be performed using standard statistical packages in R, such as stats::lm(), estimateEffect offers an important advantage. Unlike a simple lm(theta ~ covariates), estimateEffect accounts for the uncertainty in the topic prevalence that arises from the stm() estimation. In essence, instead of directly predicting the estimated prevalence, \(\theta_{d,k}\), it predicts a set of simulated prevalences, incorporating the uncertainty from the structural topic model estimation process. The core methodology is implemented in the internal function stm::thetaPosterior() internal function, available here. We can then compute the expected topic prevalence for each topic and for each value of year_defence.
Show the code
# run a regression predicting prevalence with the year of defence# create a covariate table and ensure proper it is coded with the proper format metadata <- corpus_in_stm$meta %>% as_tibble %>%mutate(year_defence =as.numeric(year_defence))# create regression formula formula_str <-paste("~ s(year_defence)")formula_obj <-as.formula(formula_str)# run regression estimate_effect <-estimateEffect(formula_obj, stm,metadata = metadata,uncertainty ="Global",nsims =25)# calculate the expected prevalence for values in year_defence # simulate 25 prevalence using eta matrix and predict expected prevalence for 100 year_defence values in the range 1900:2023# see details in the internal stm::plotContinuous function ee_year <- tidystm::extract.estimateEffect( estimate_effect,"year_defence", stm,method ="continuous") %>%# add topic label left_join(top_terms_prob, by ="topic")
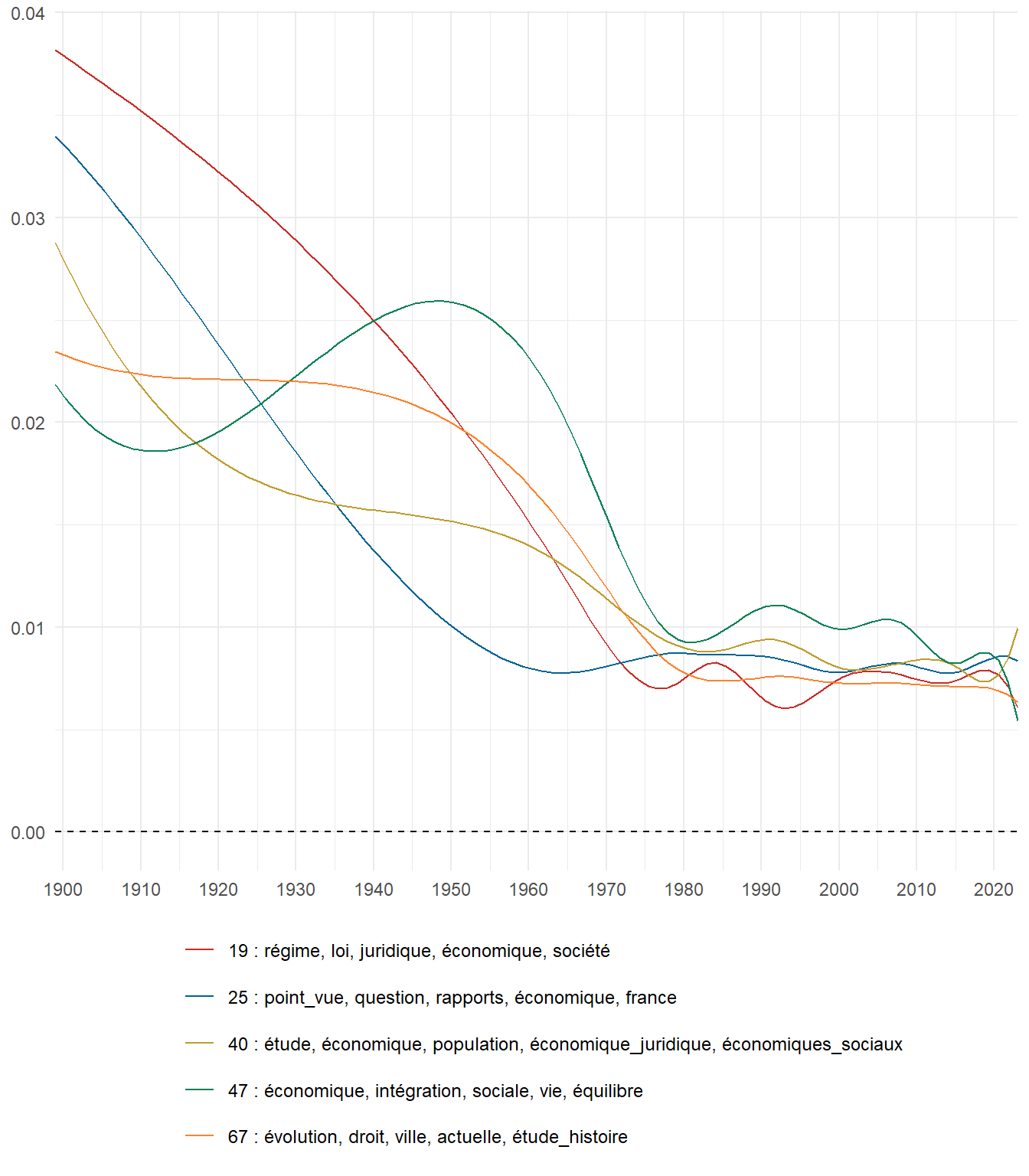
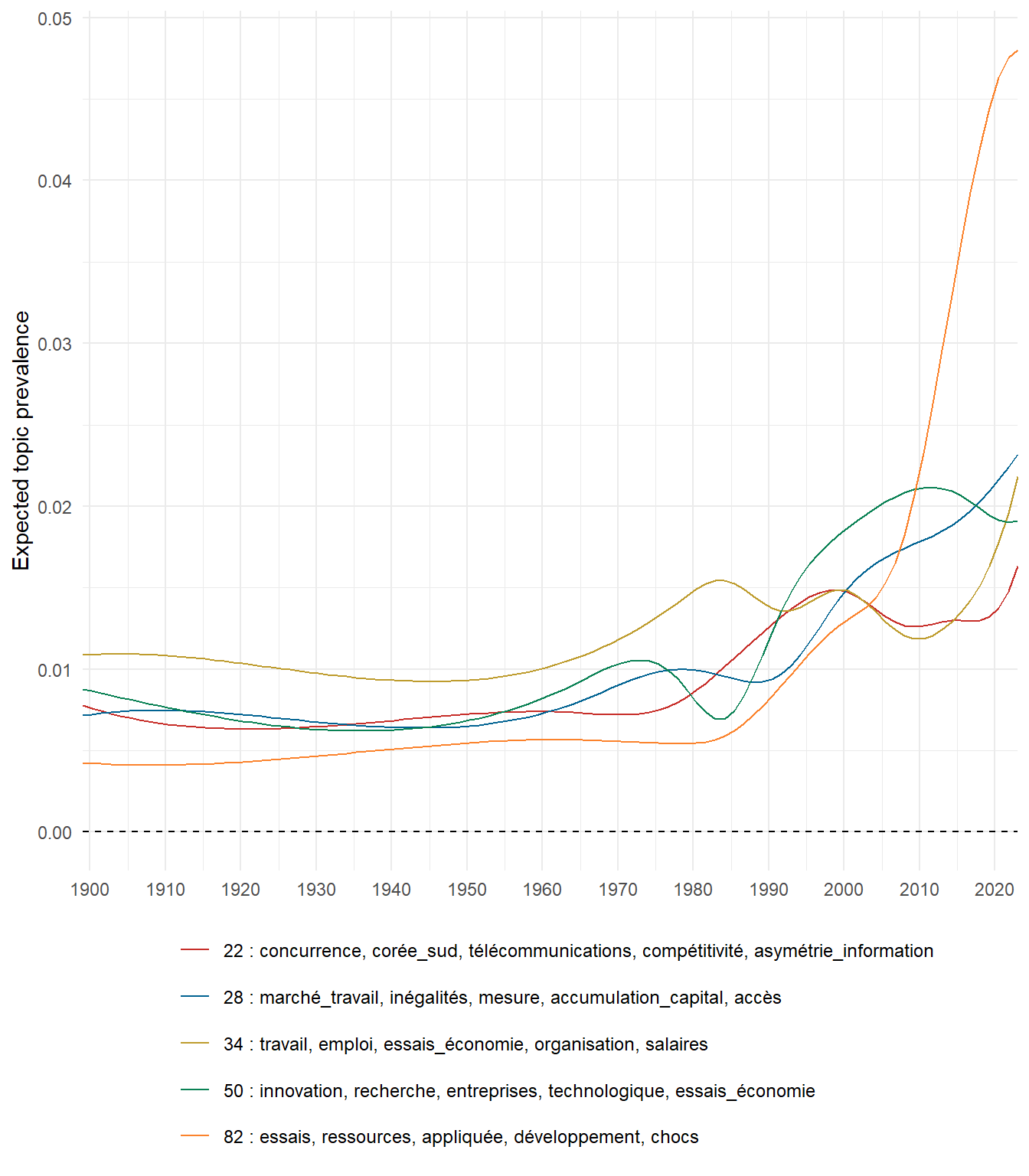
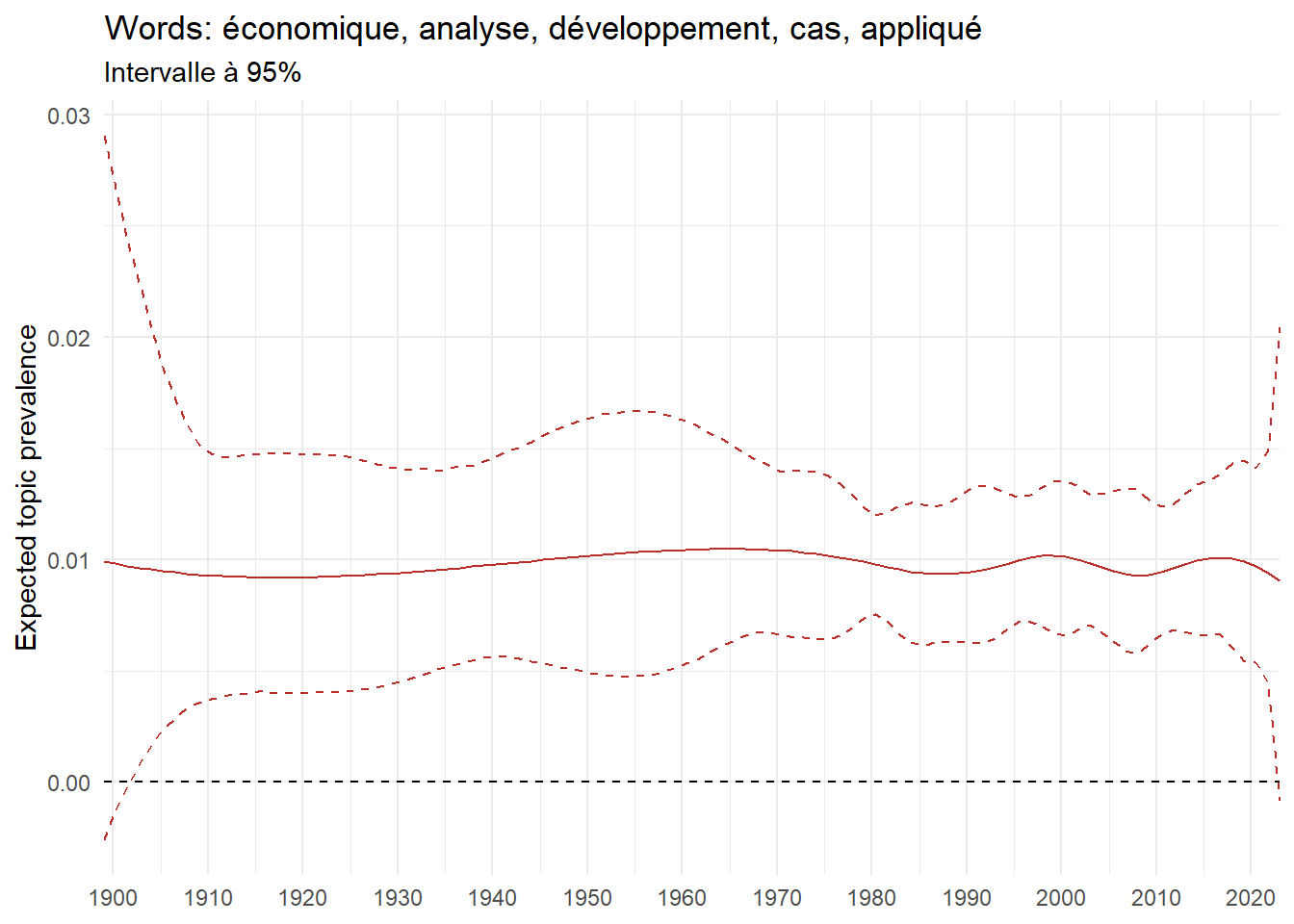
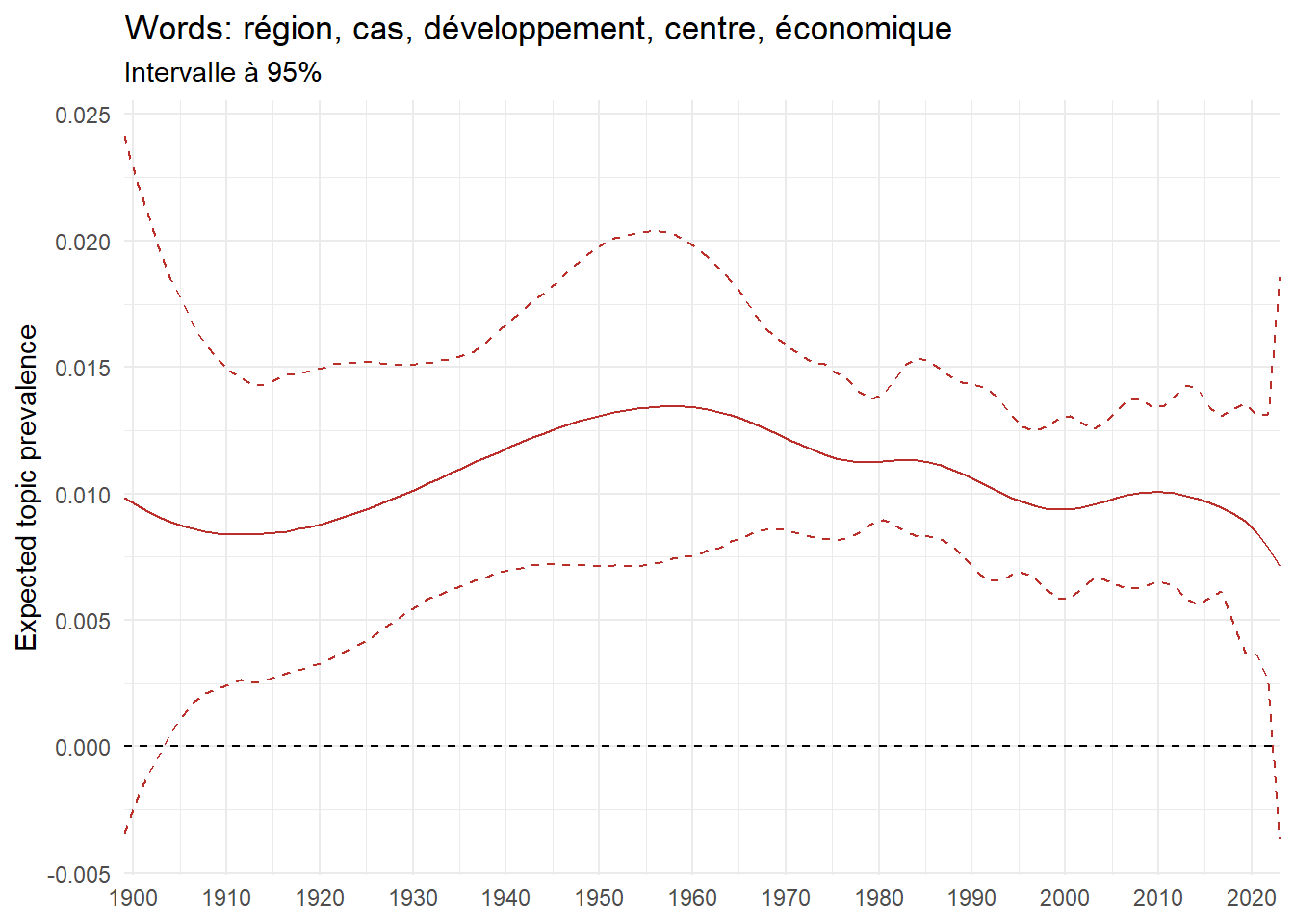
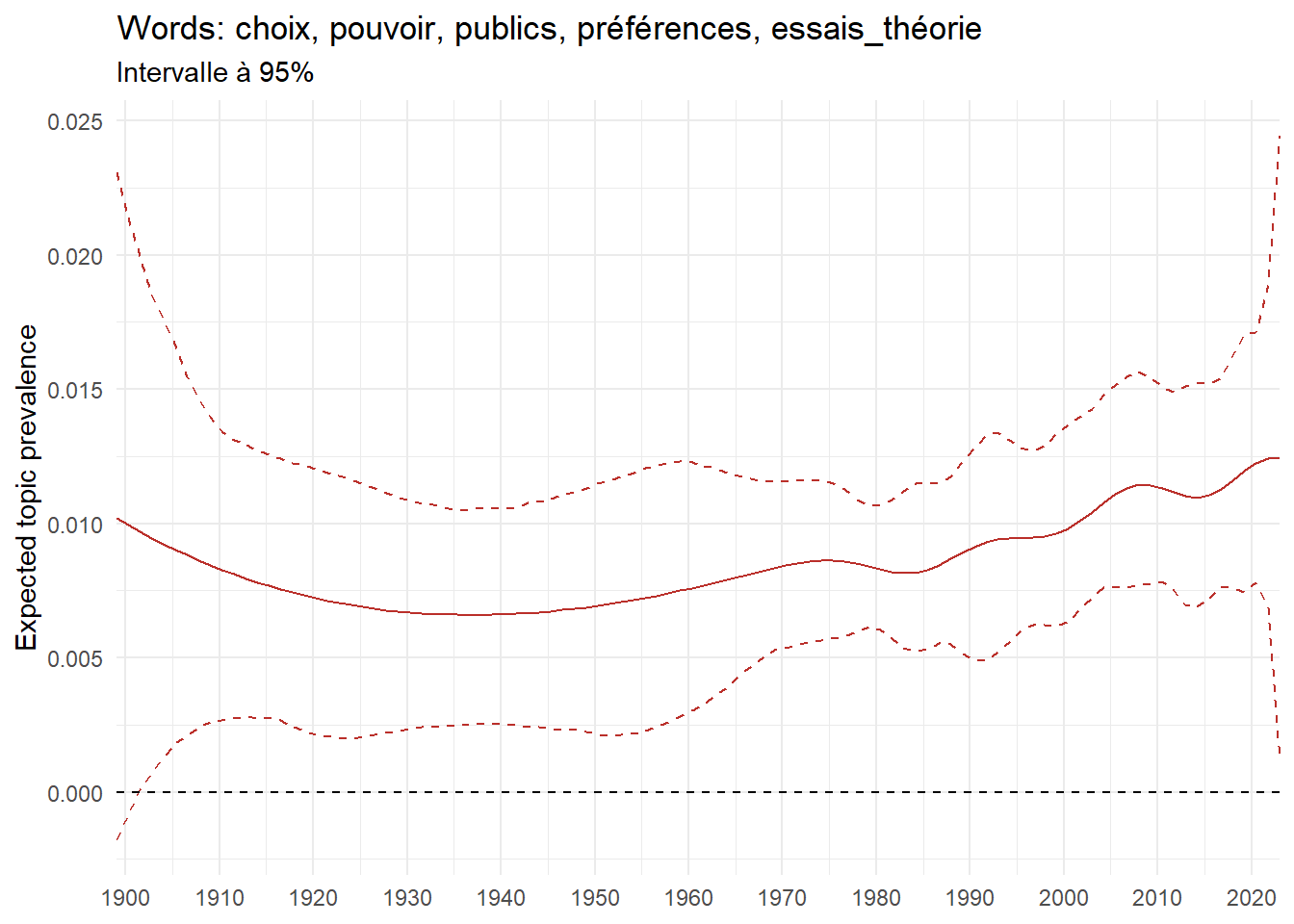
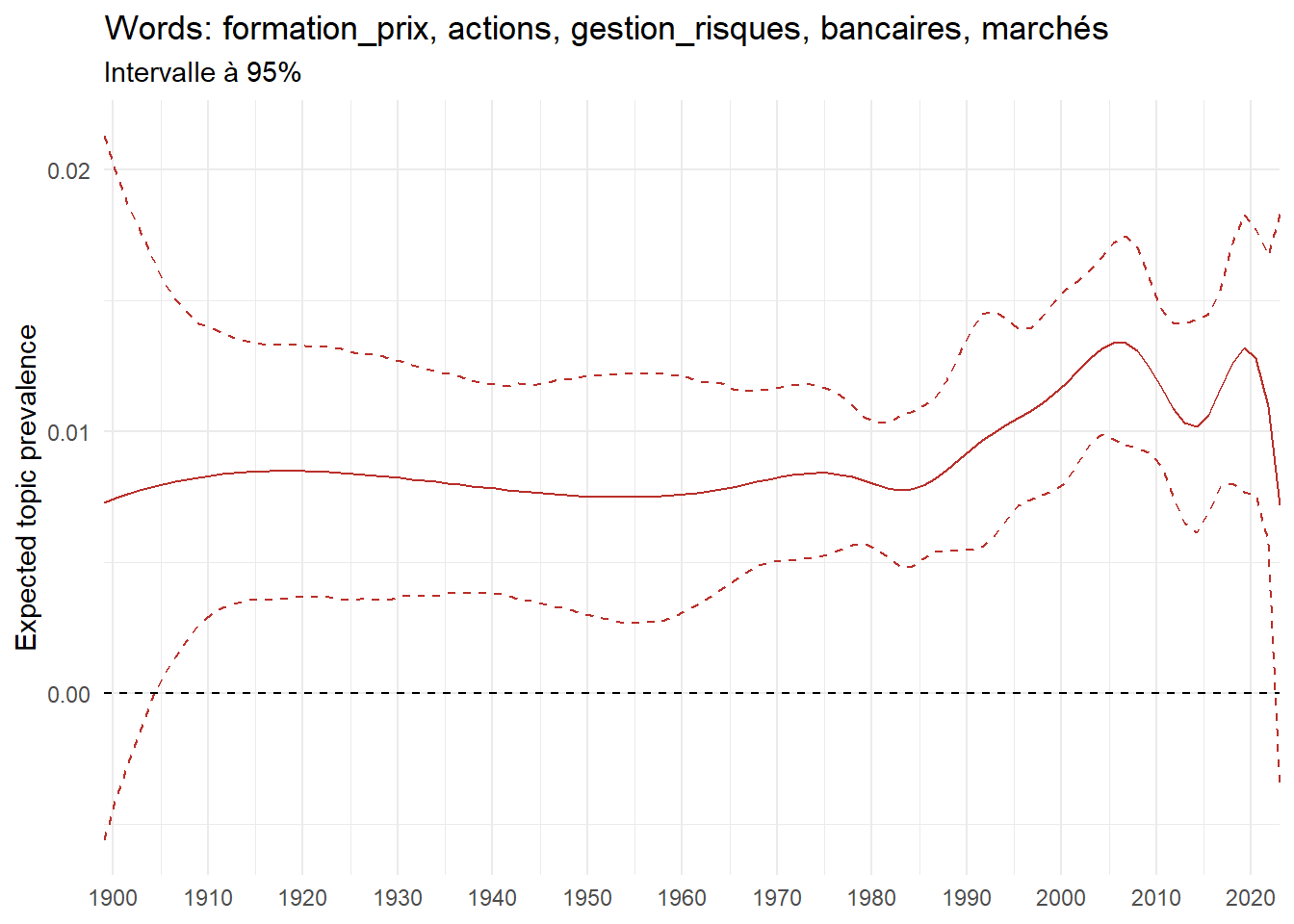
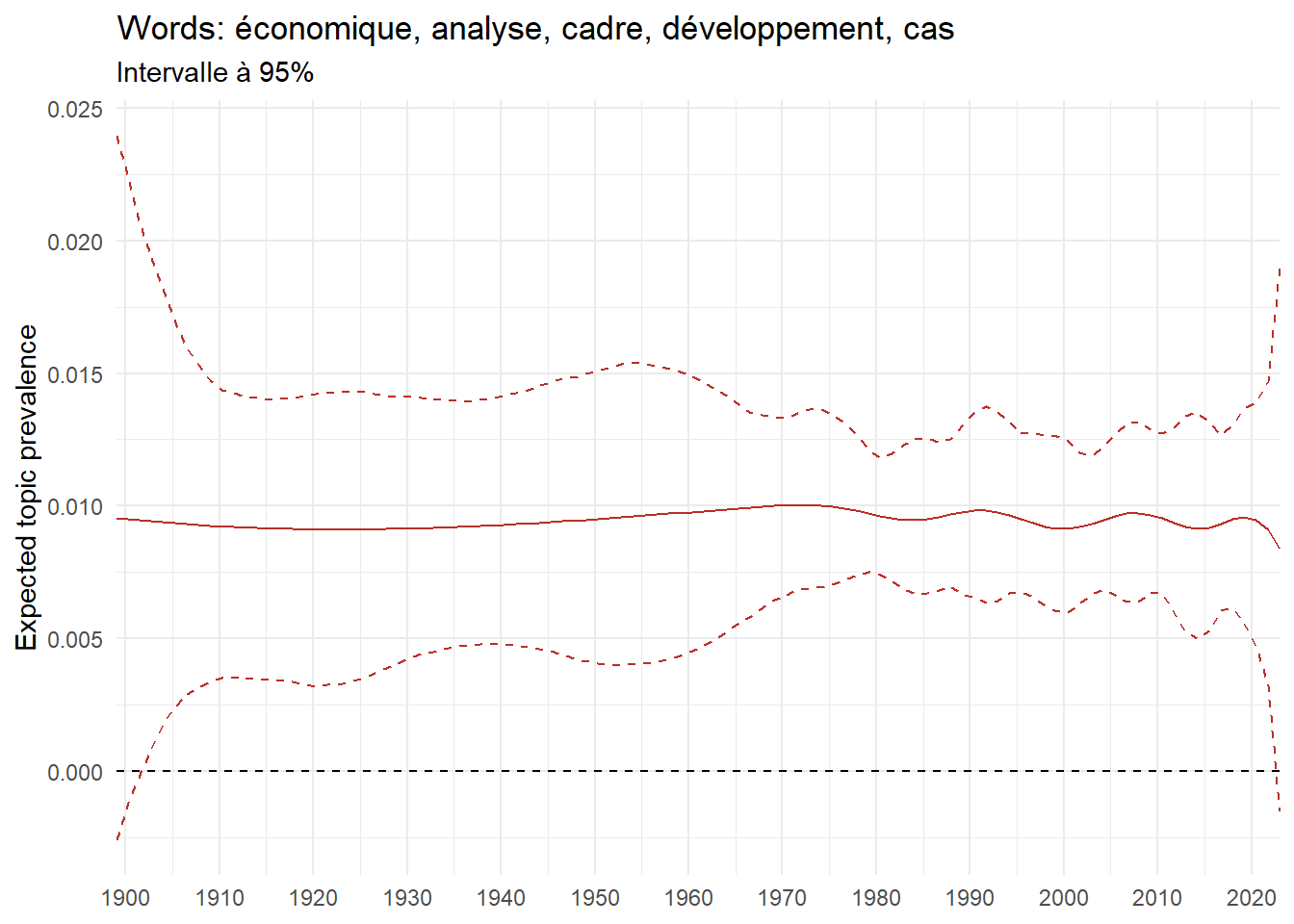
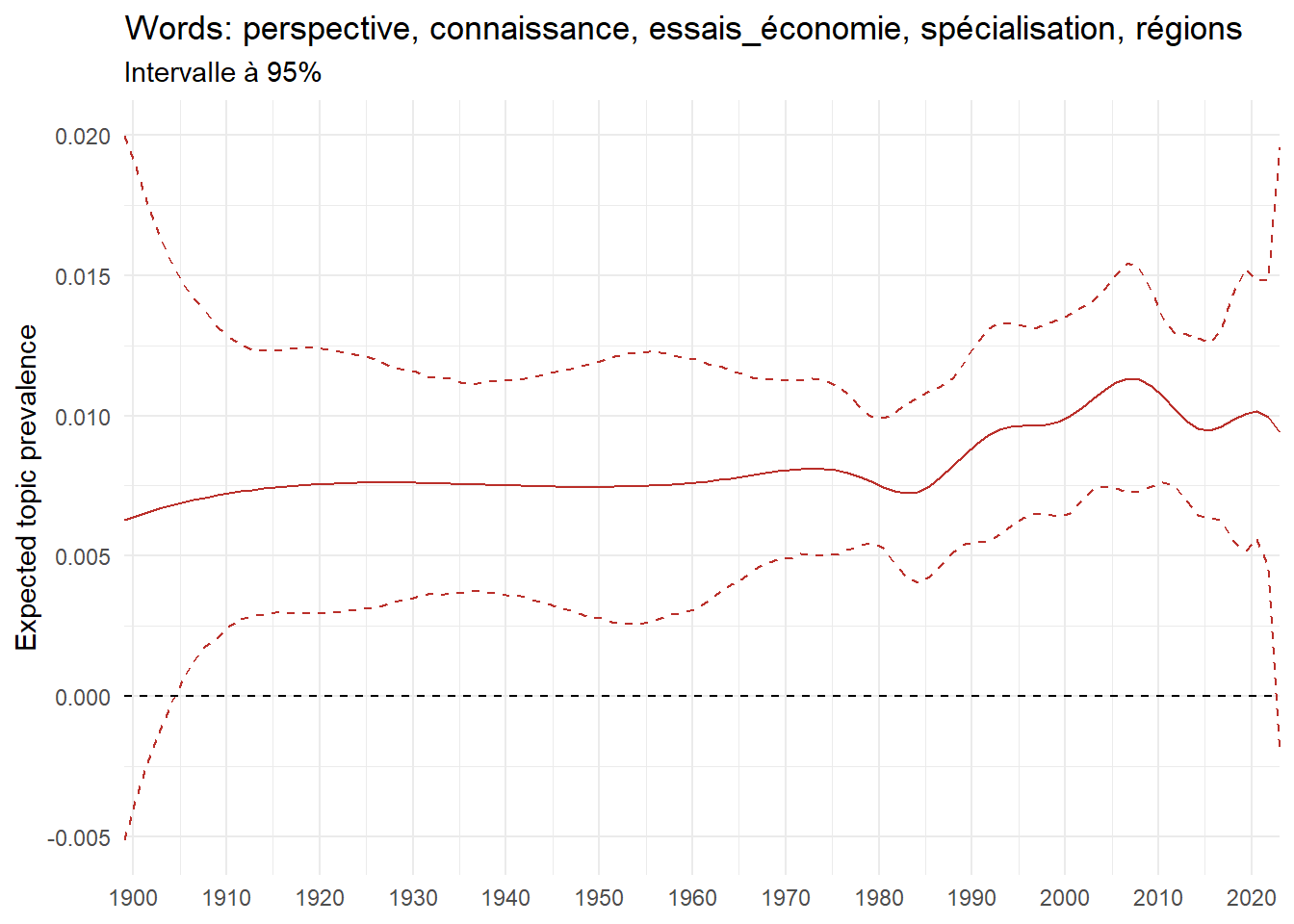
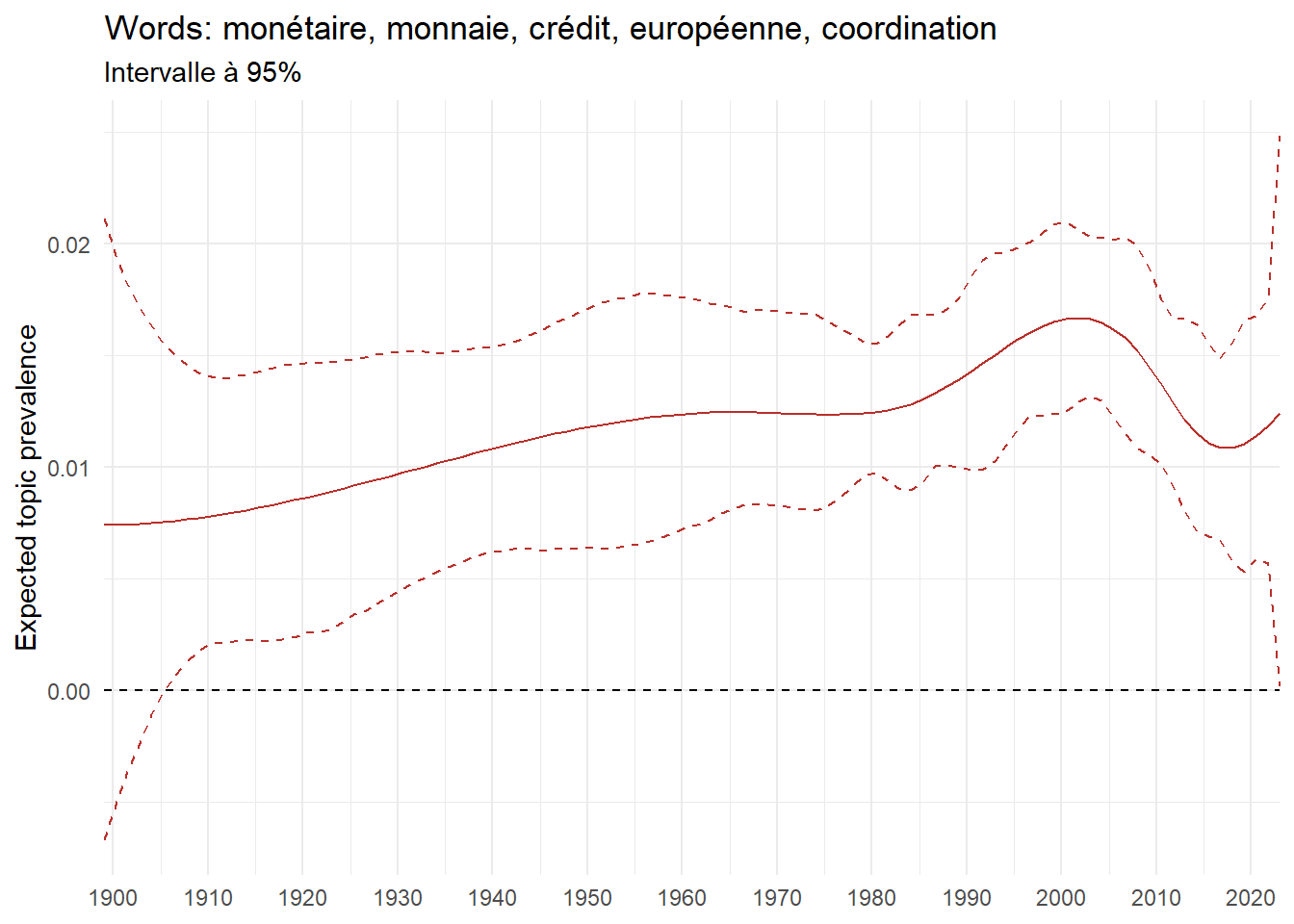
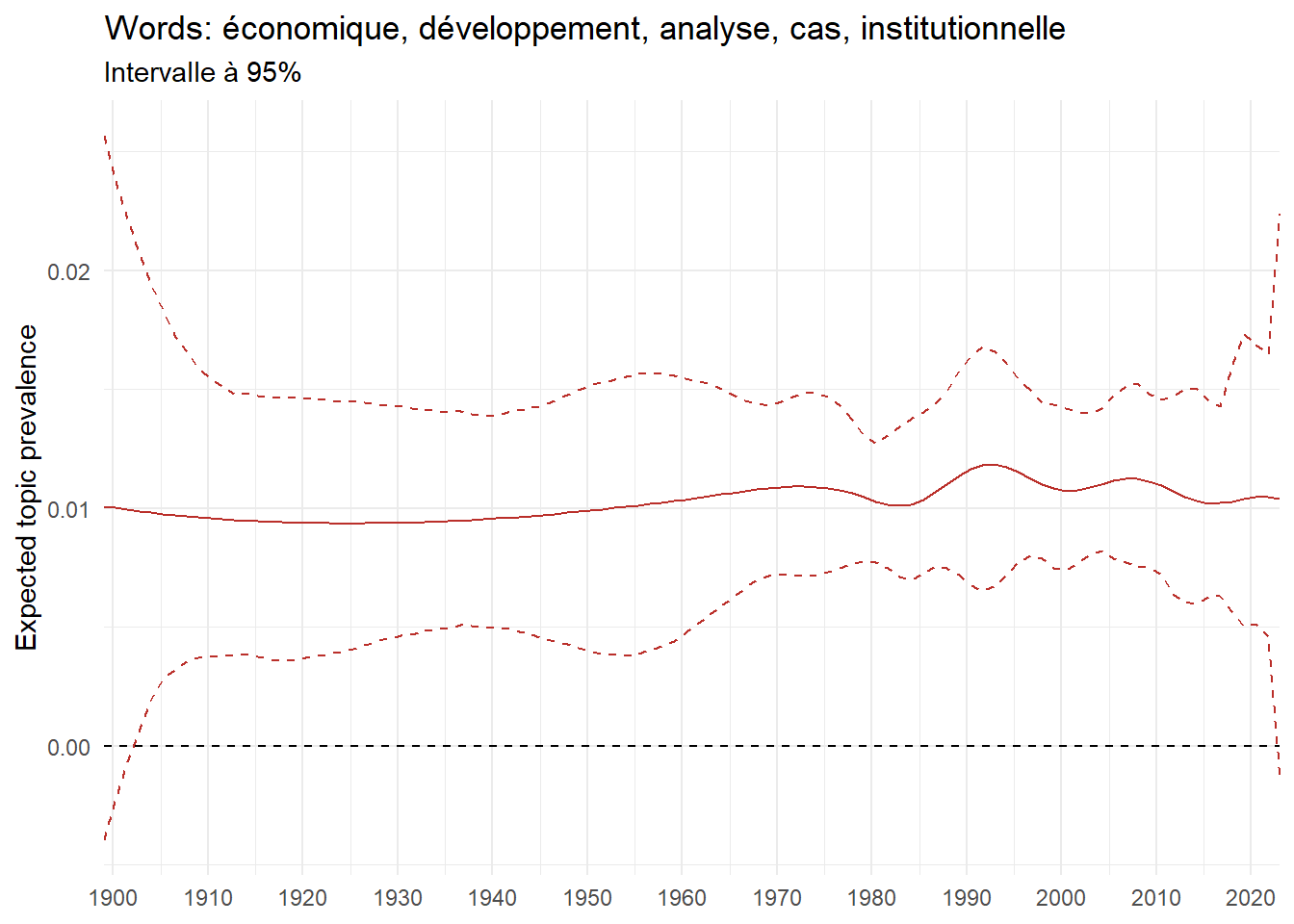
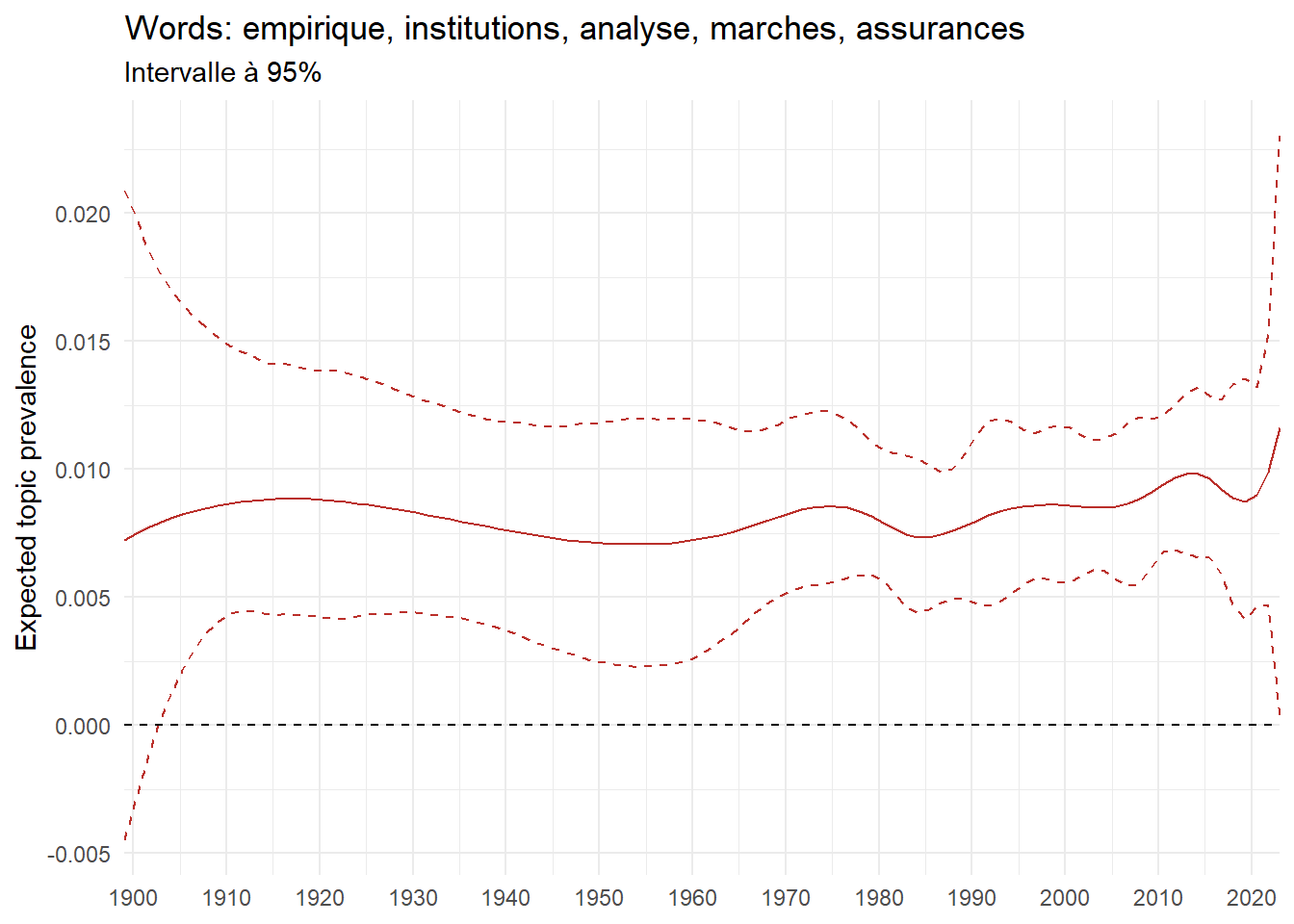
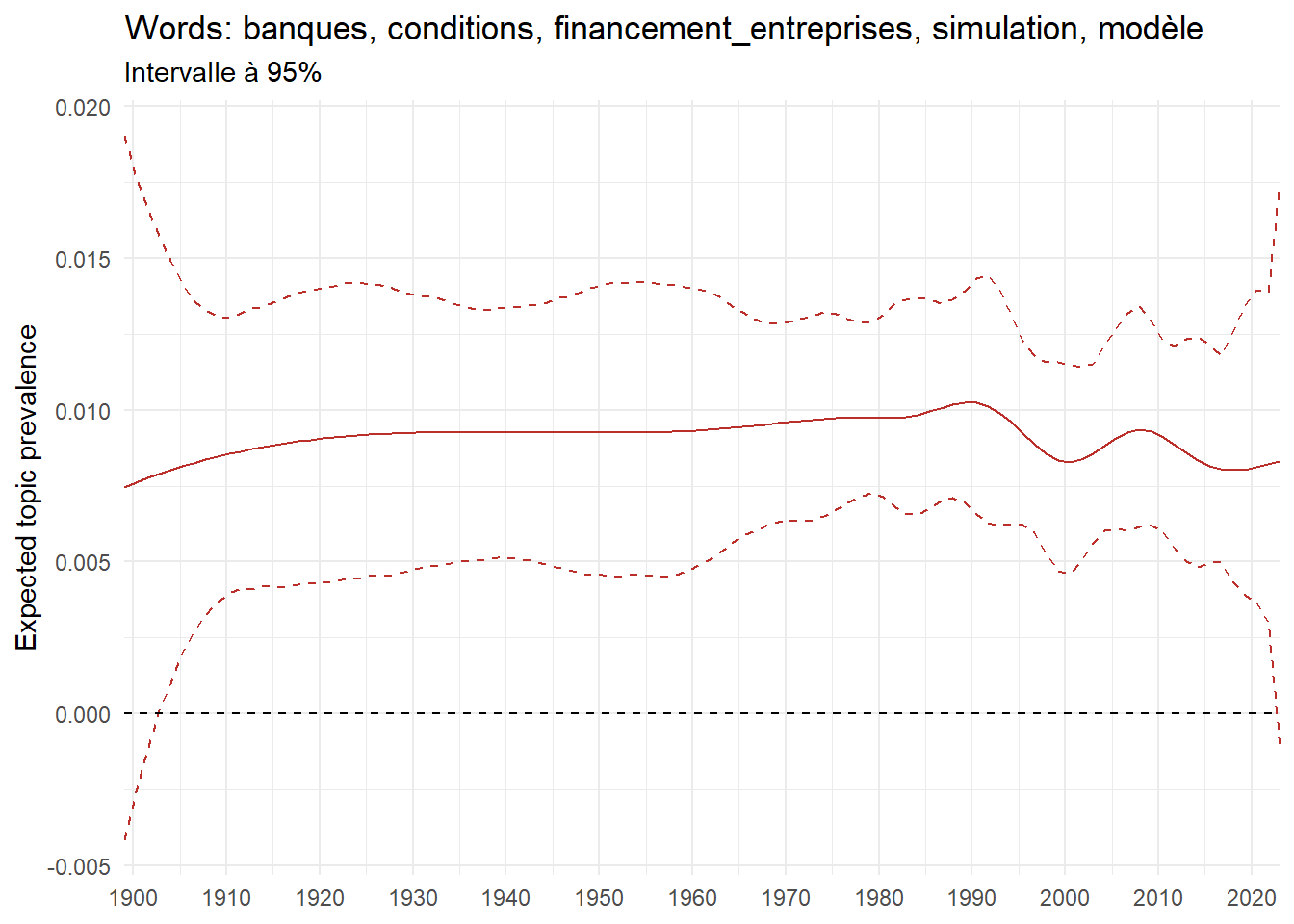
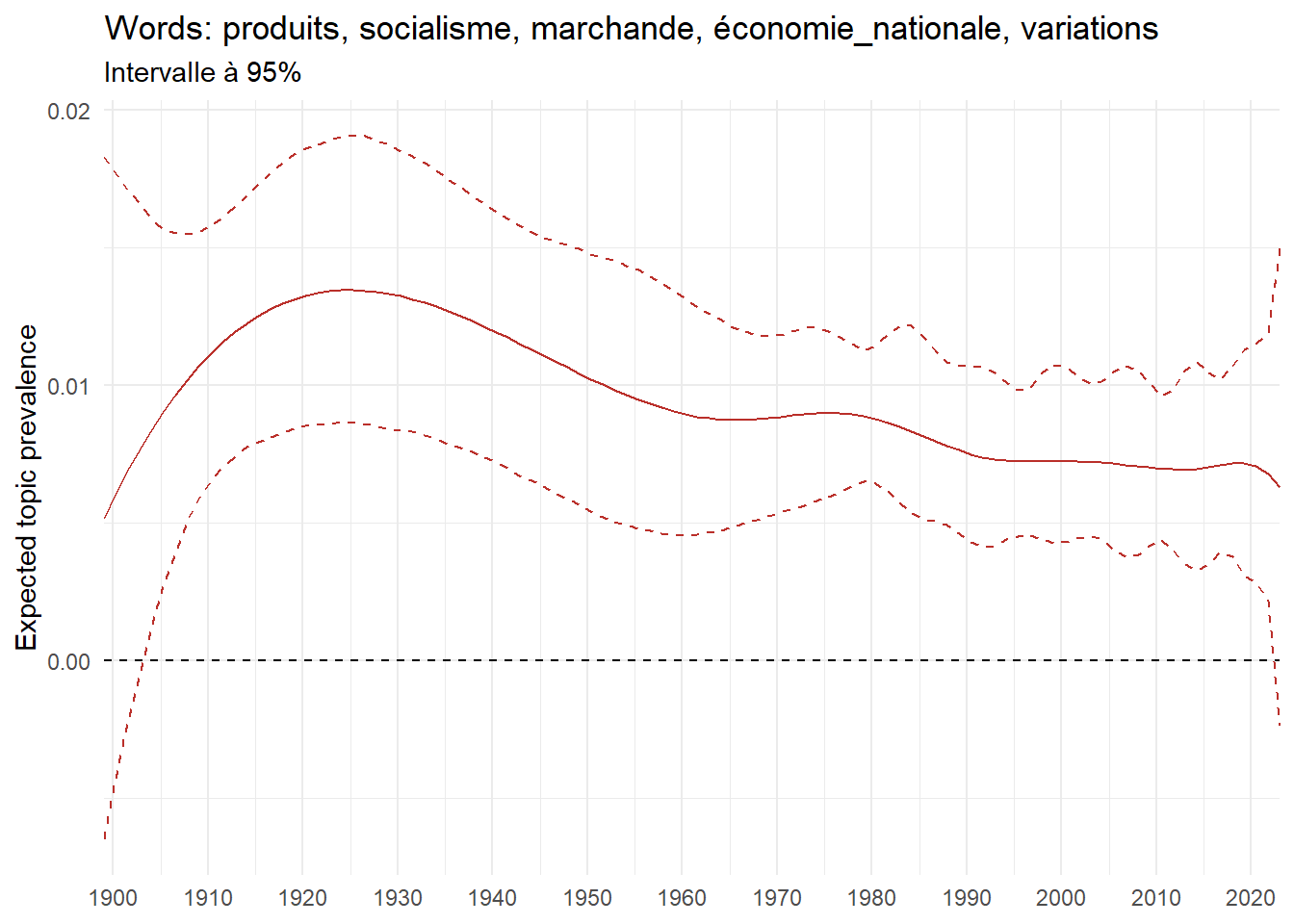
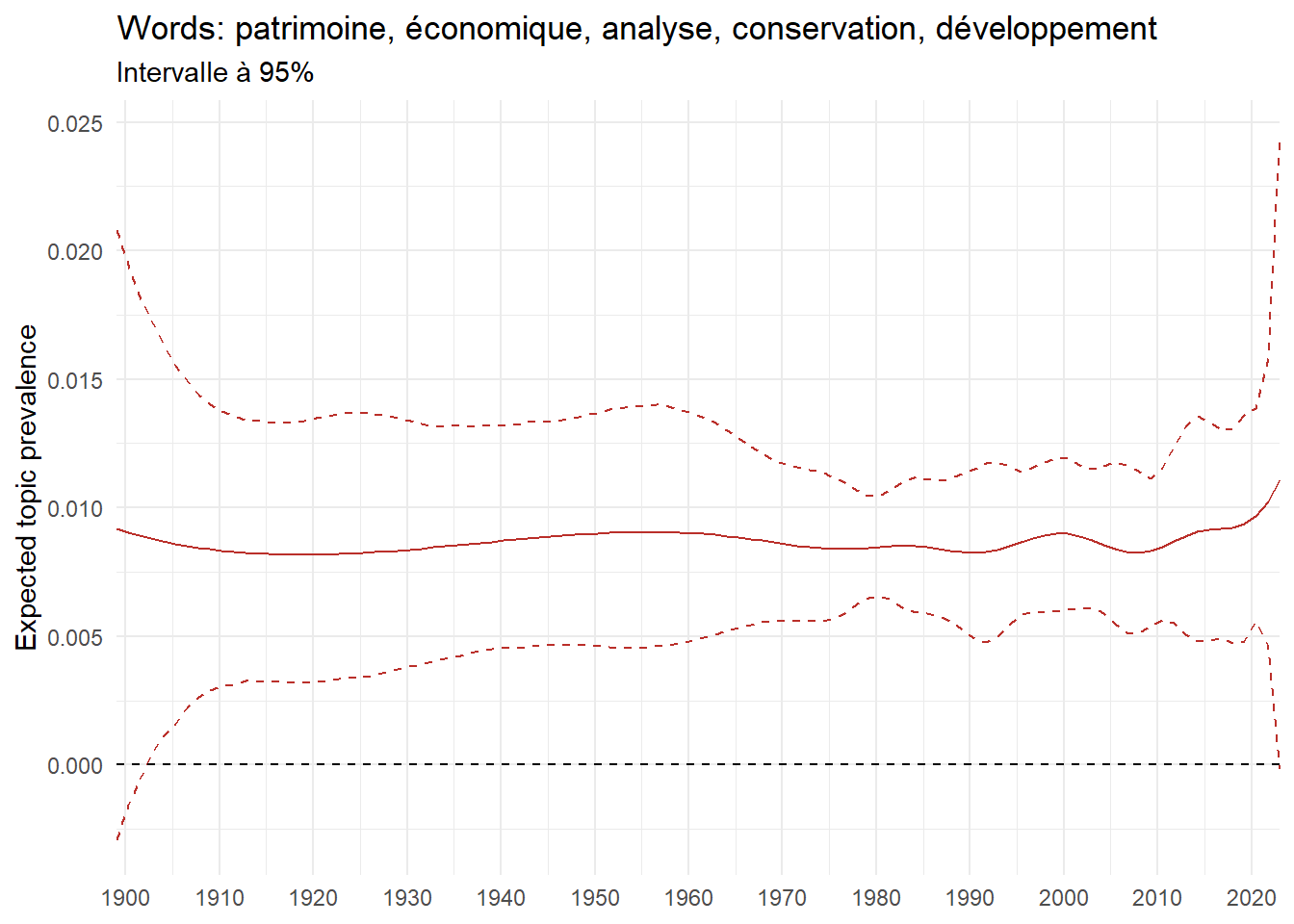
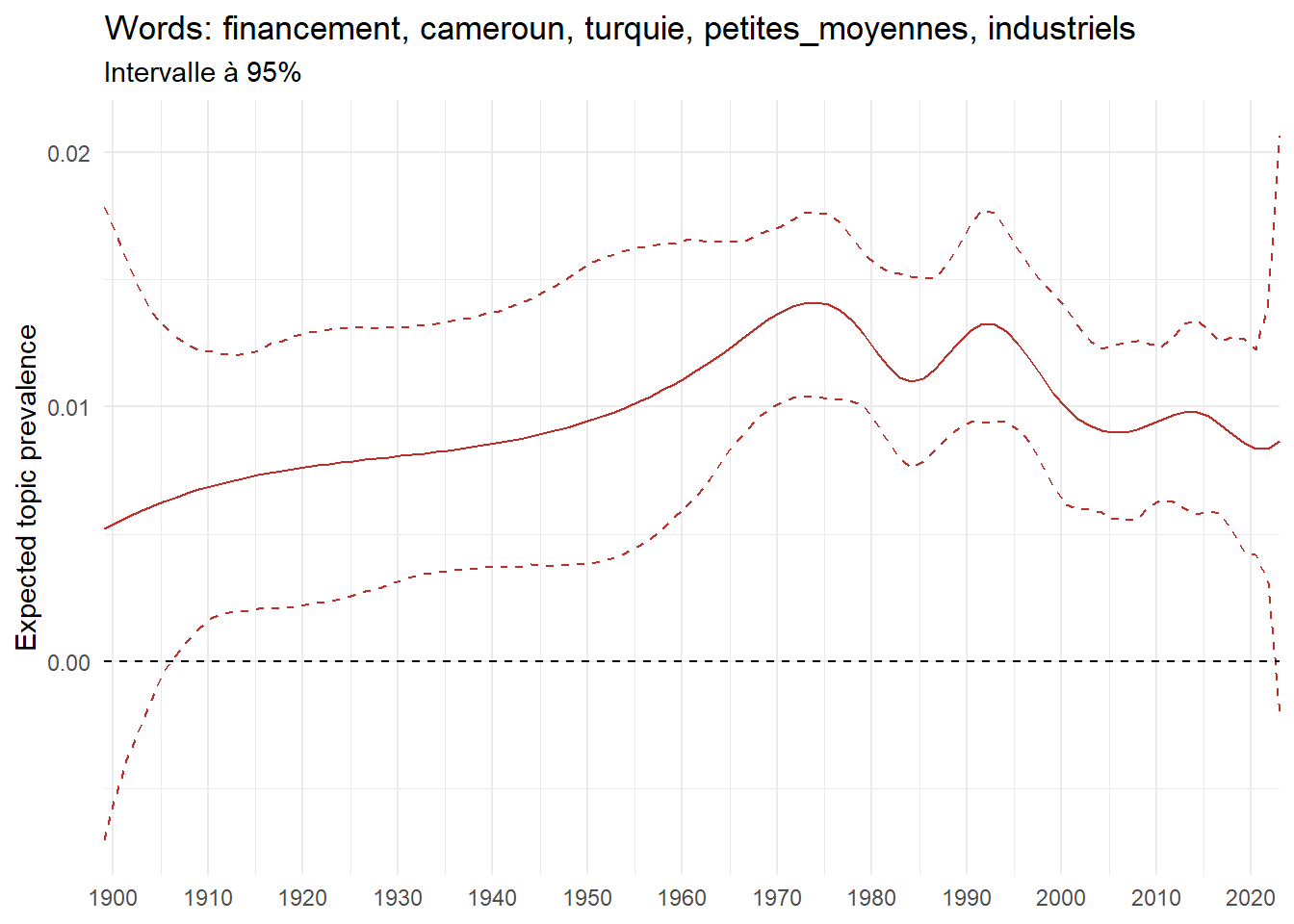
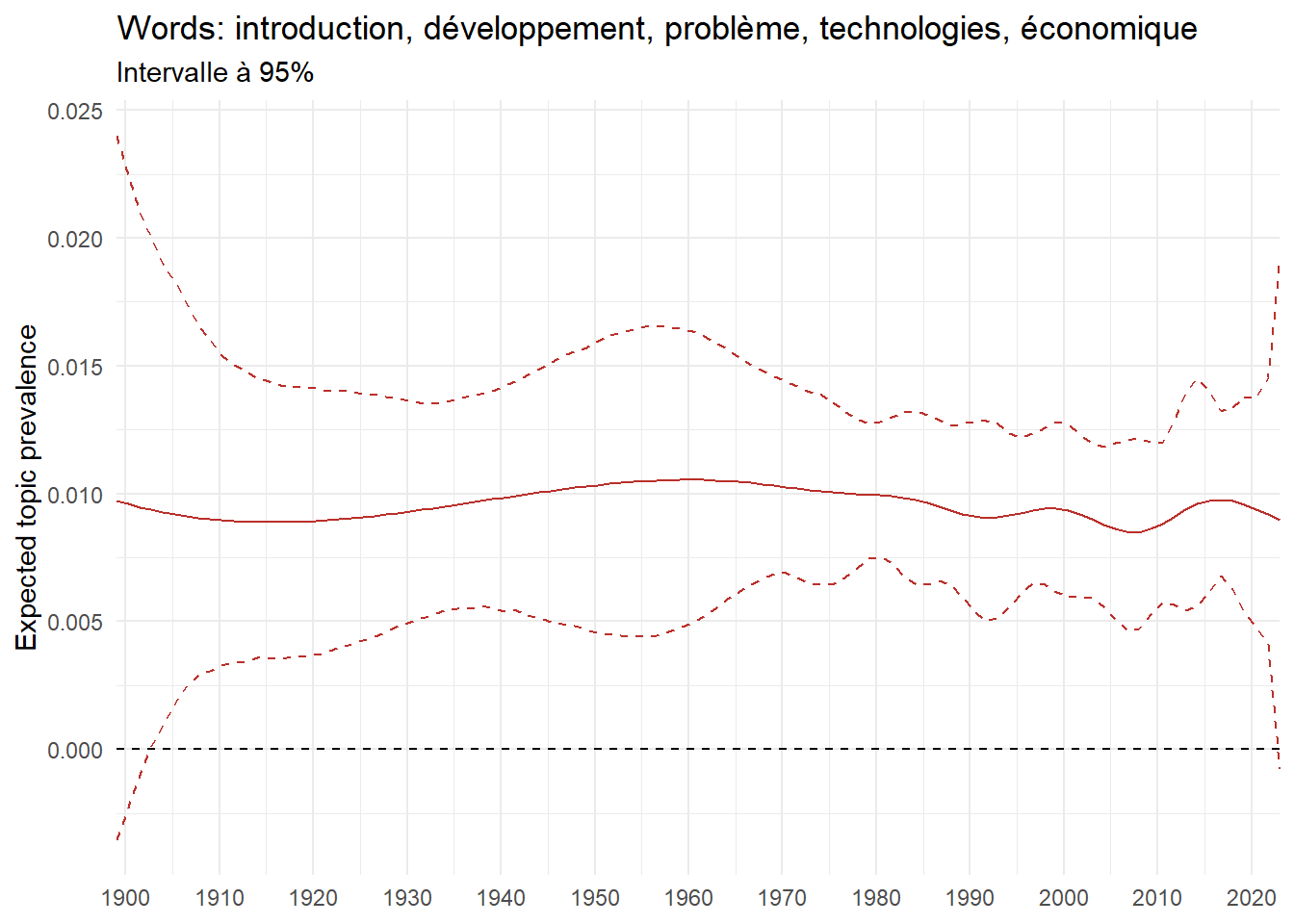
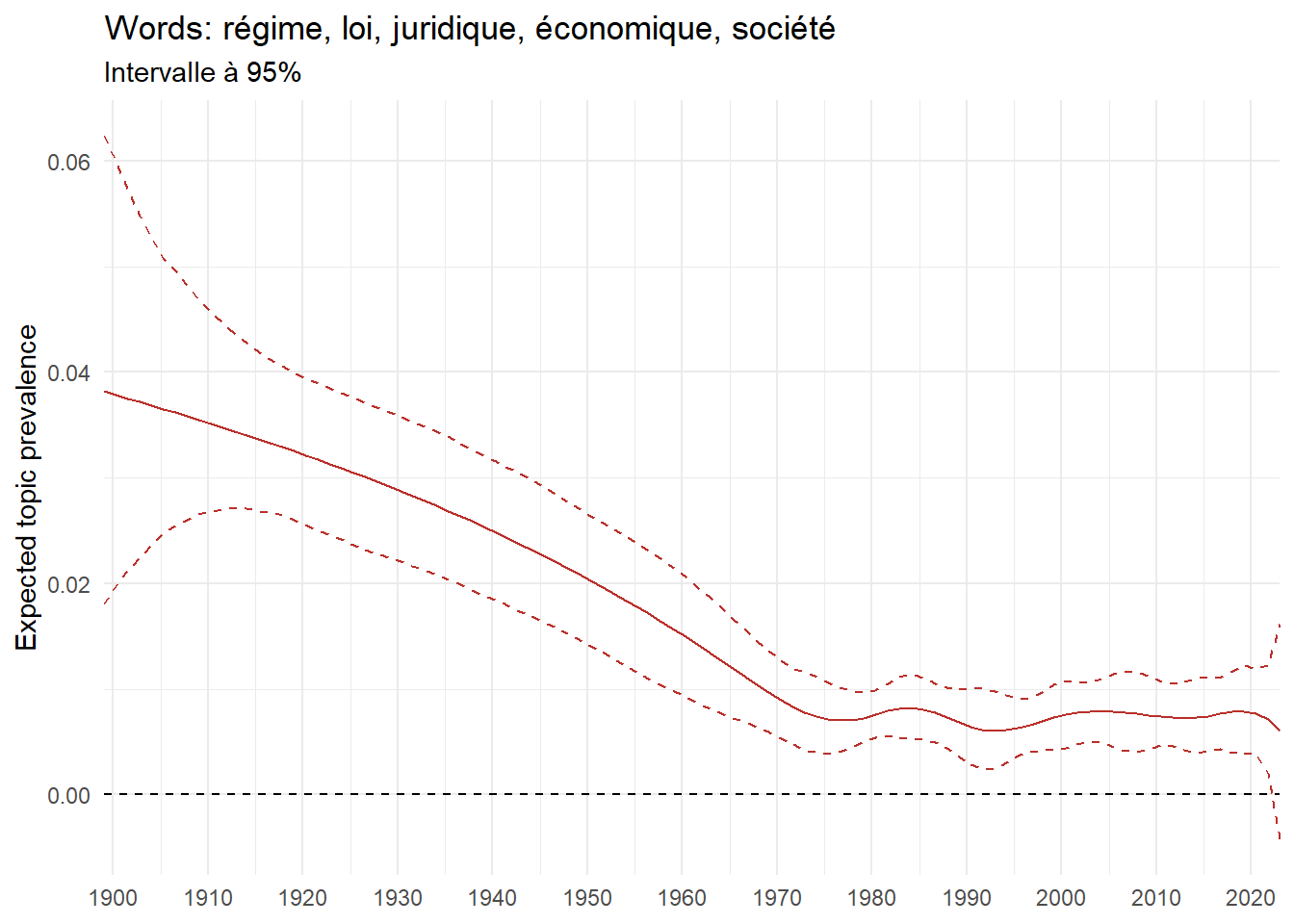
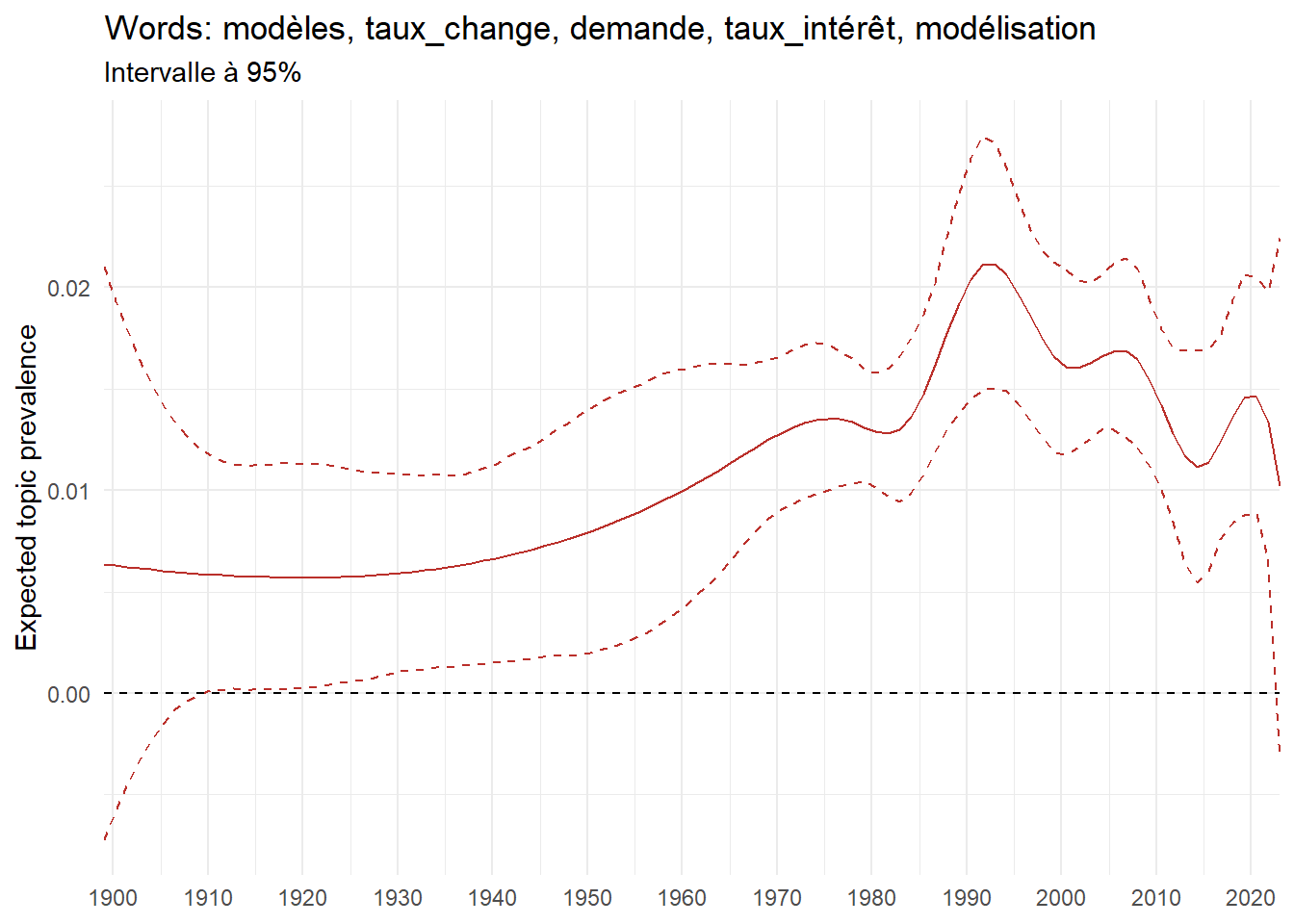
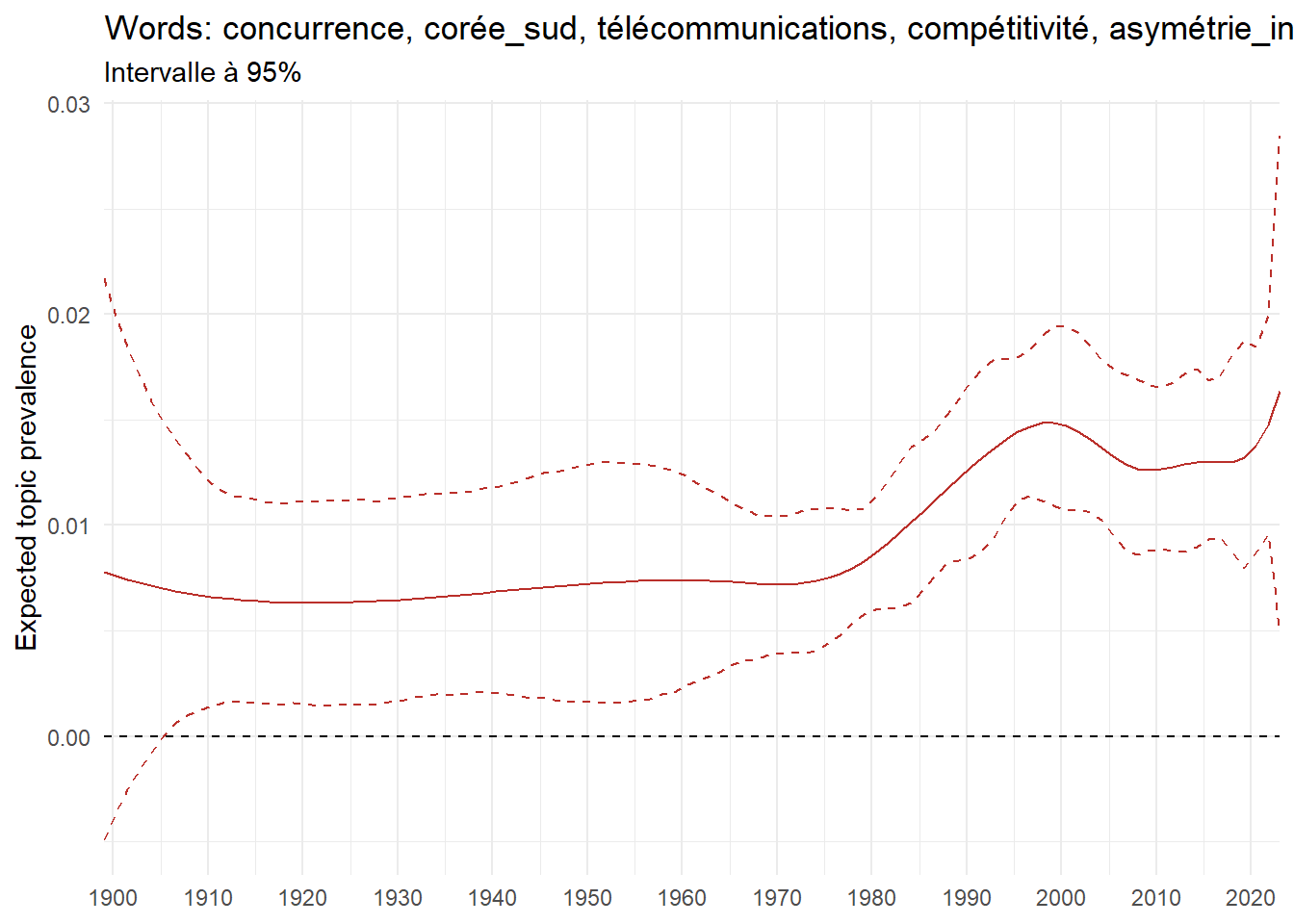
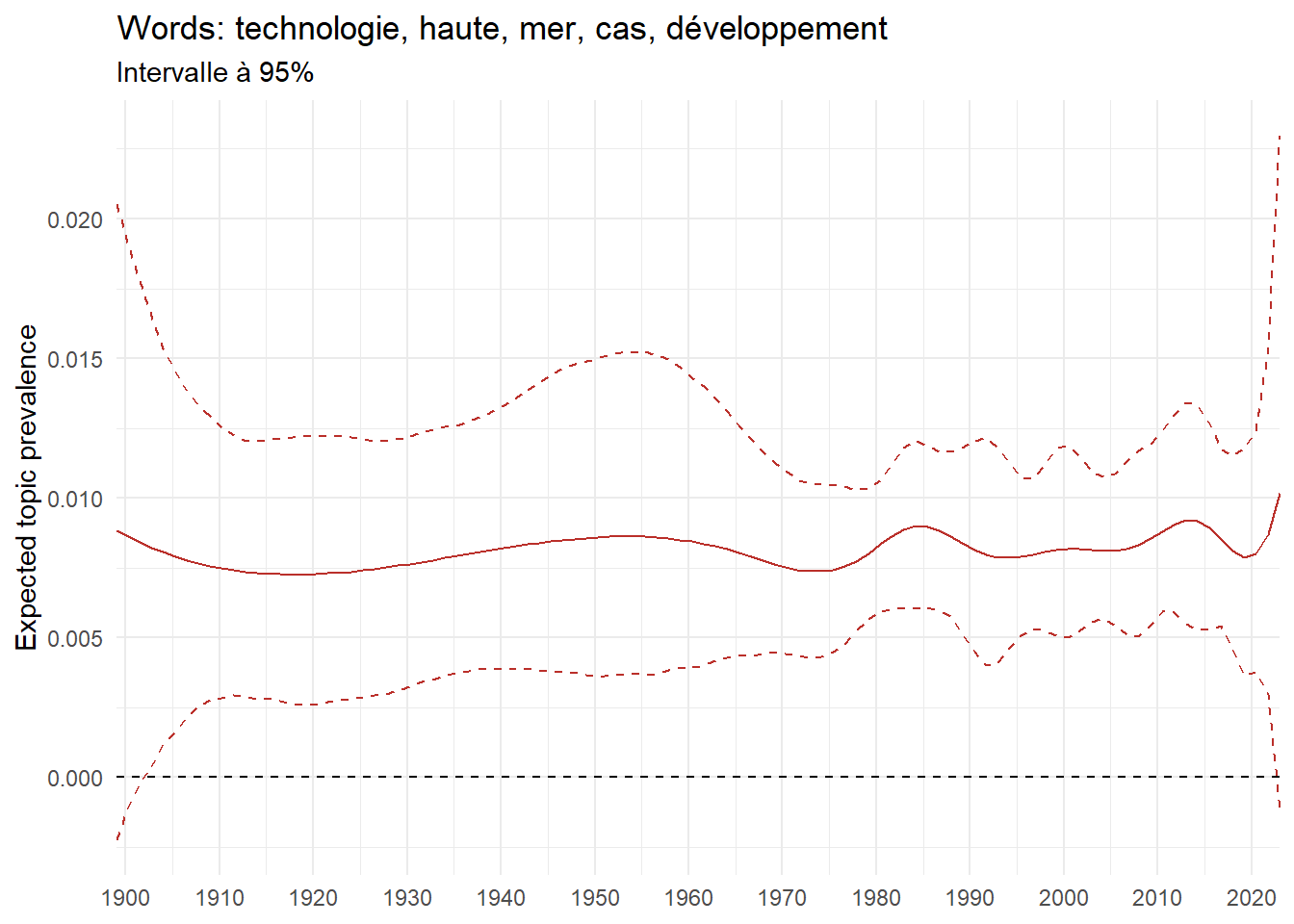
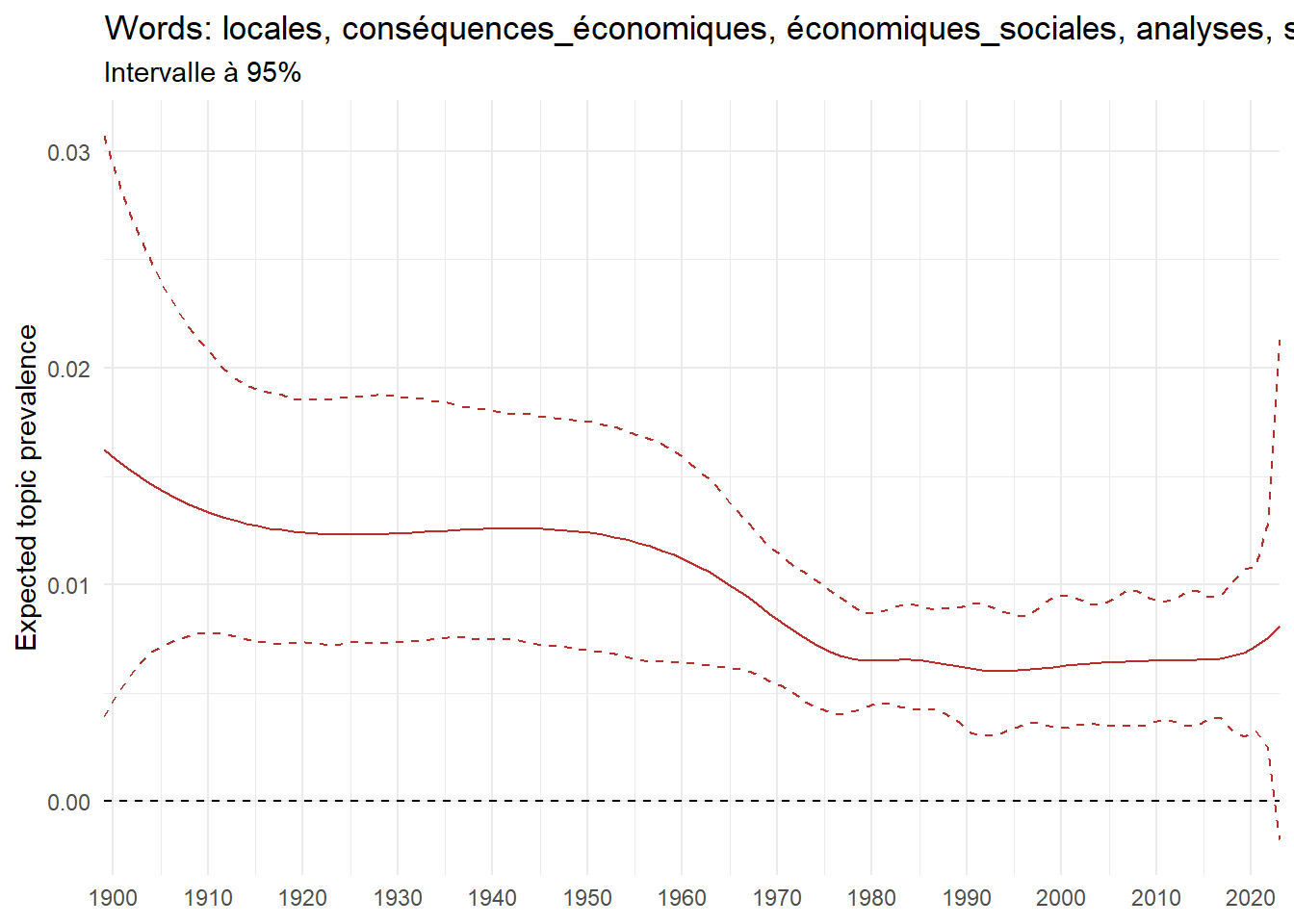
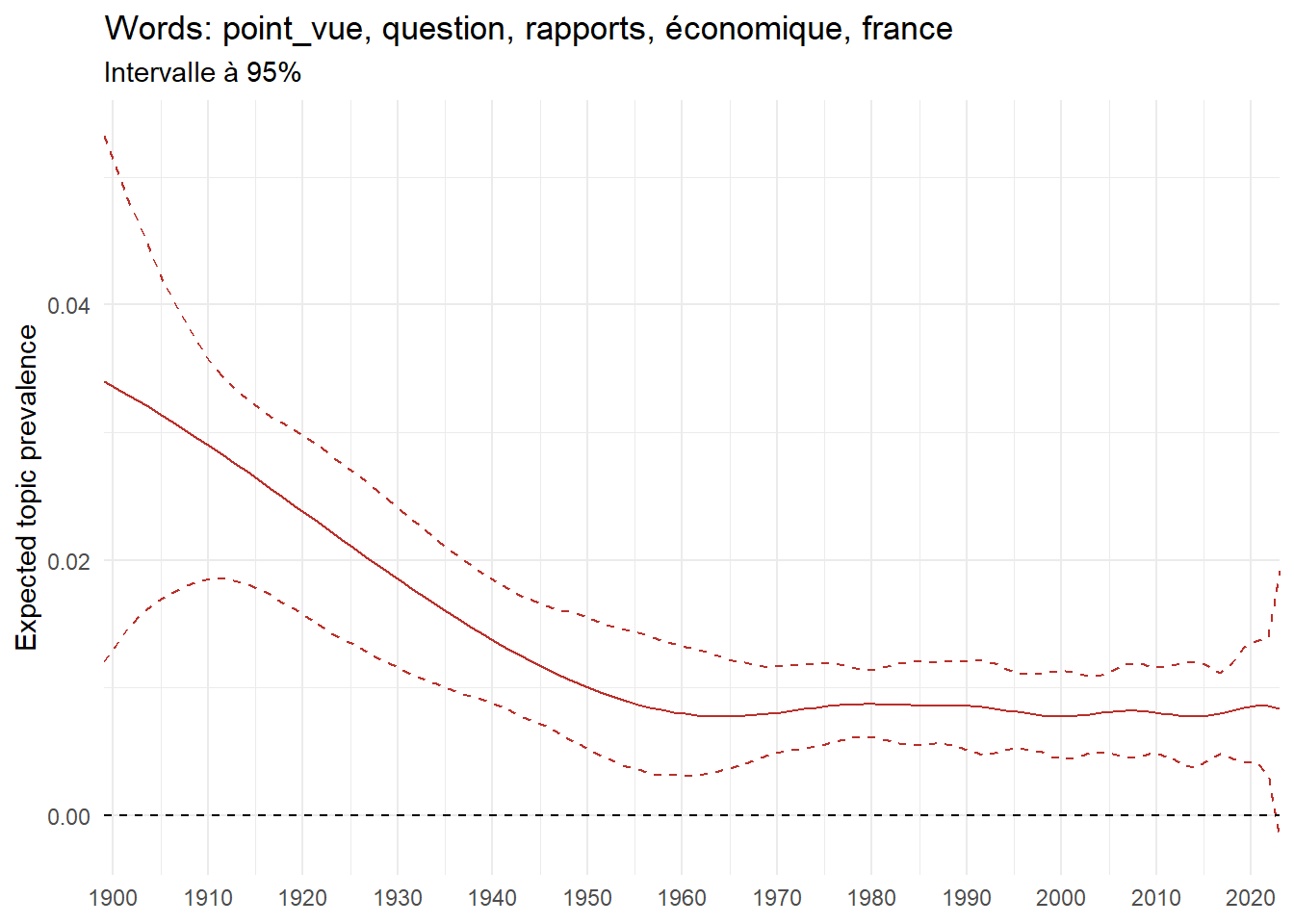
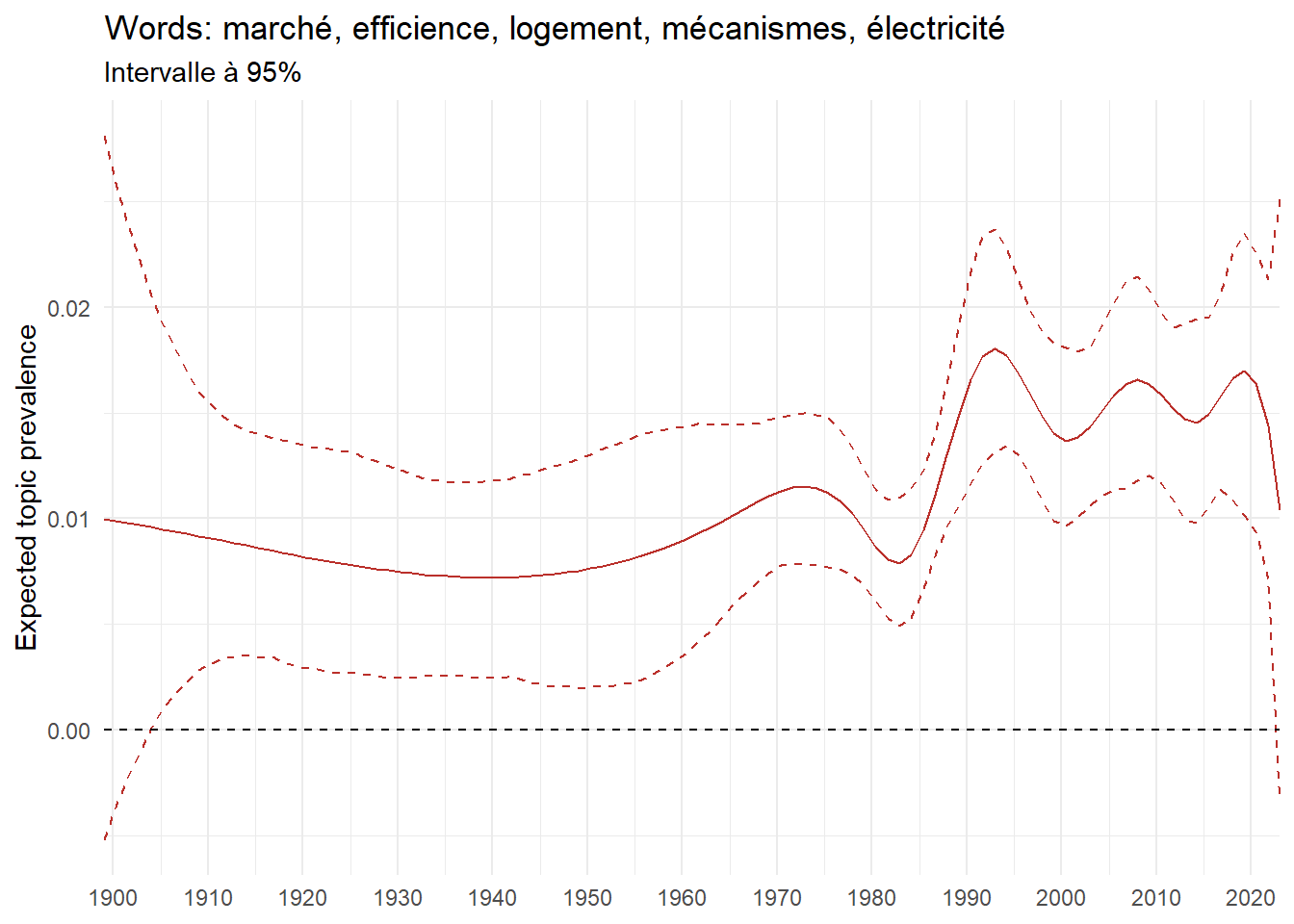
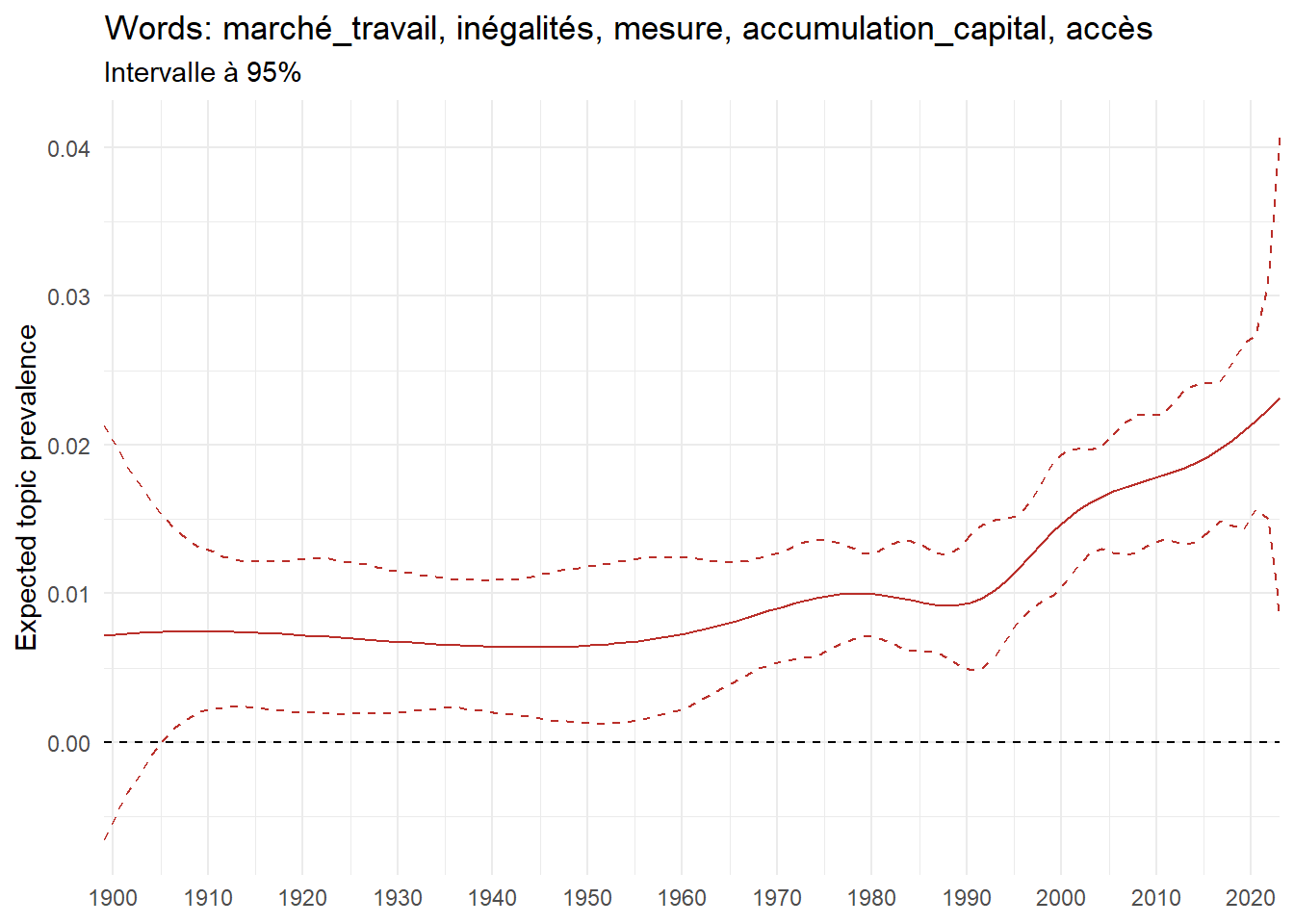
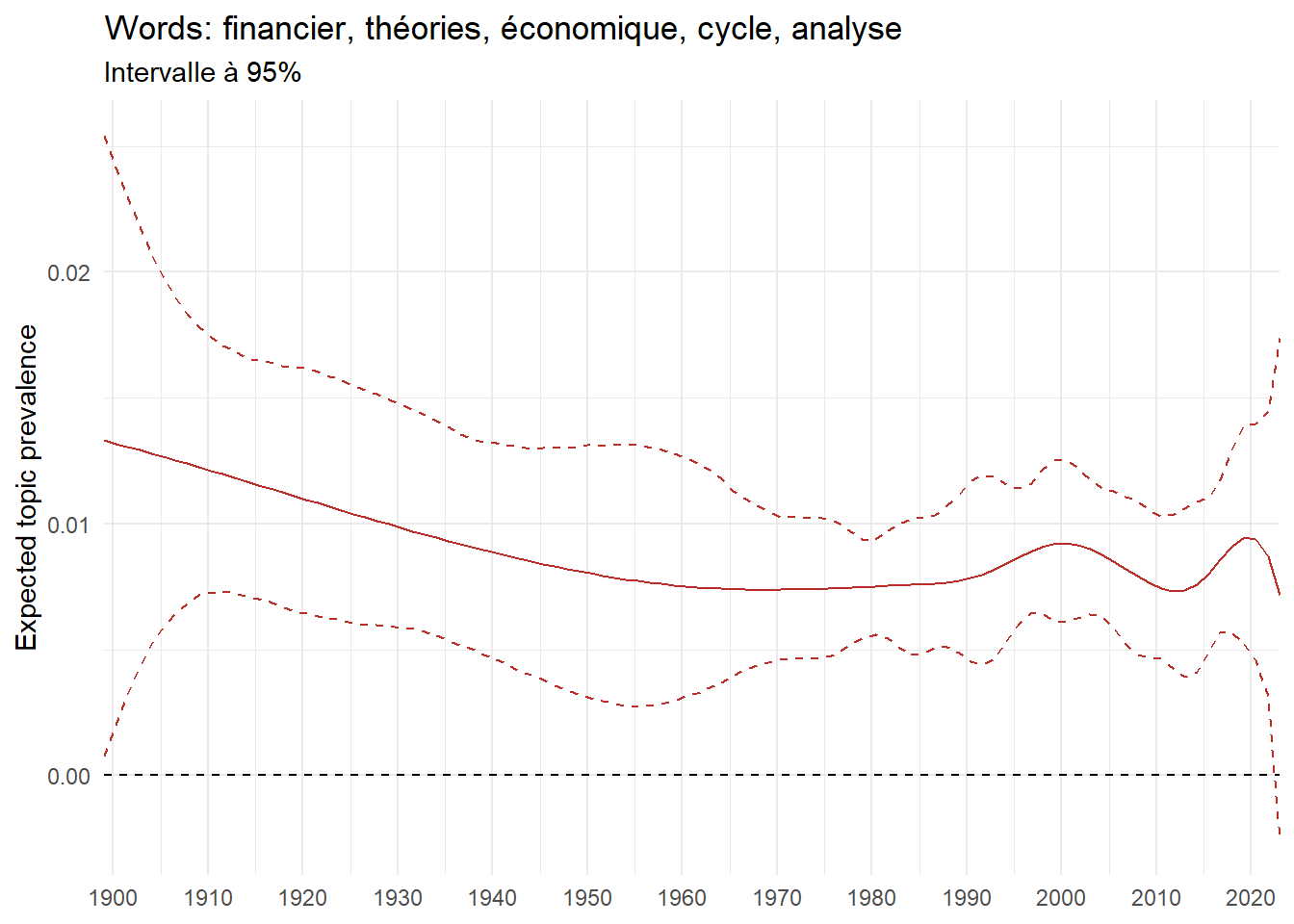
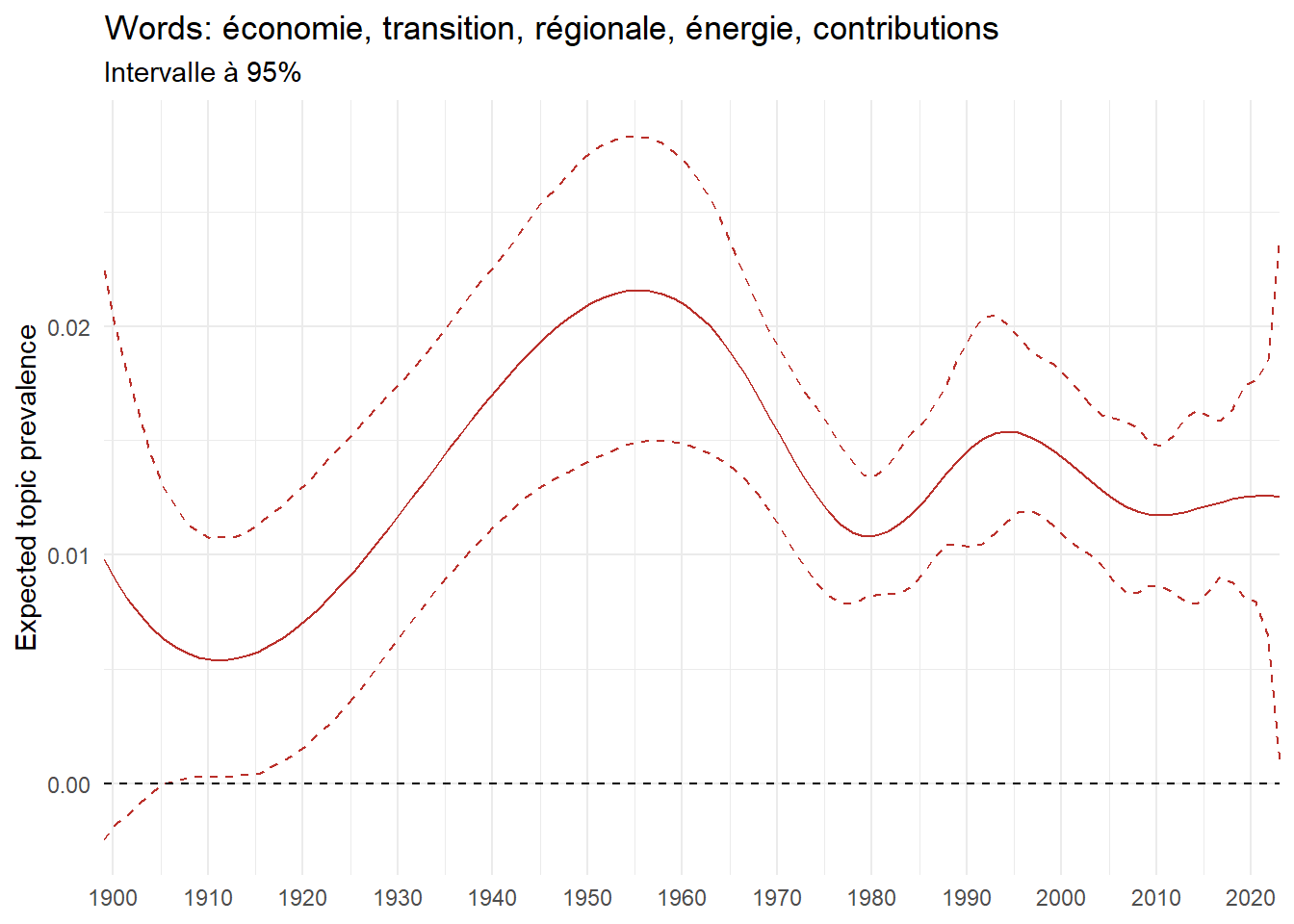
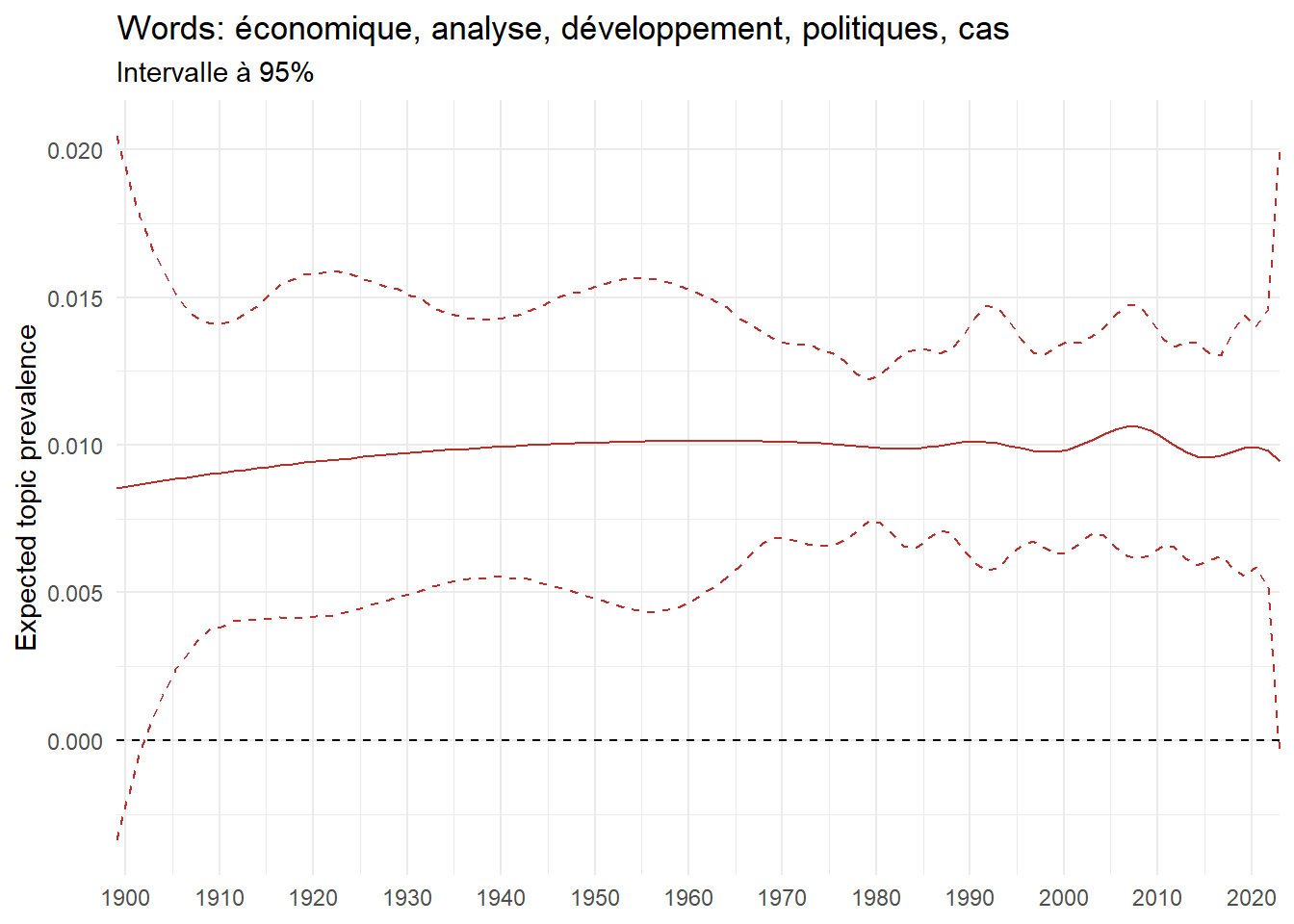
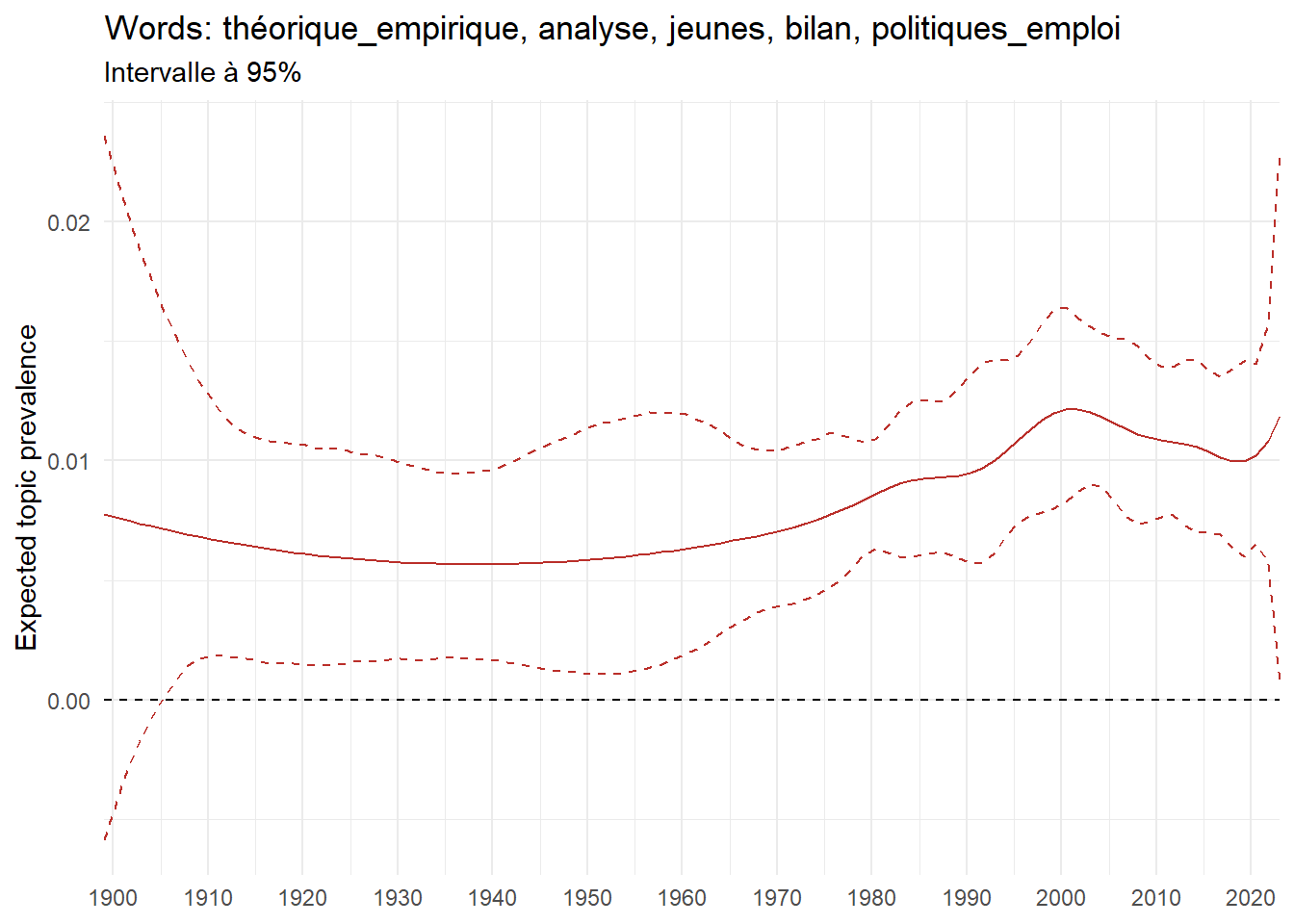
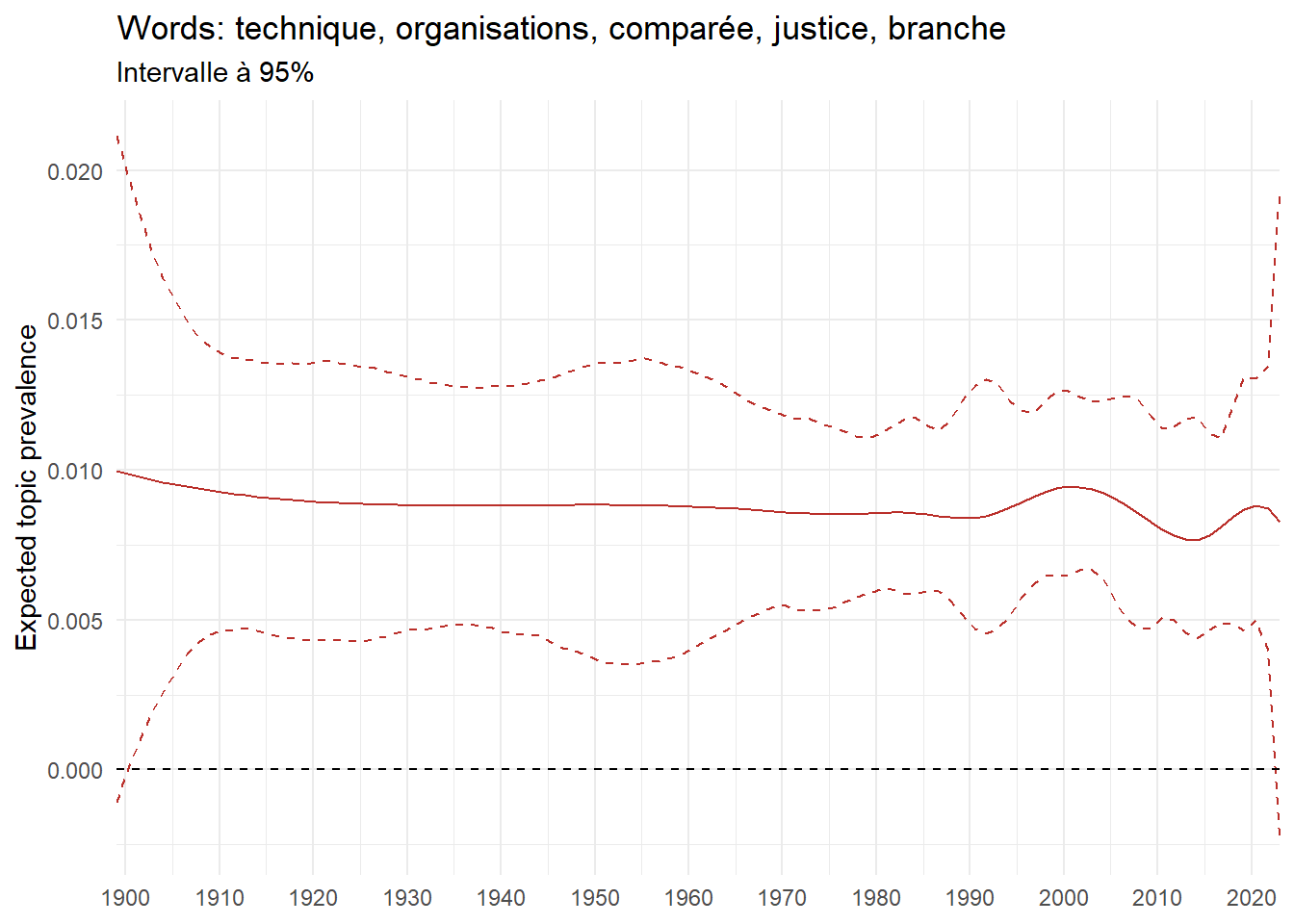
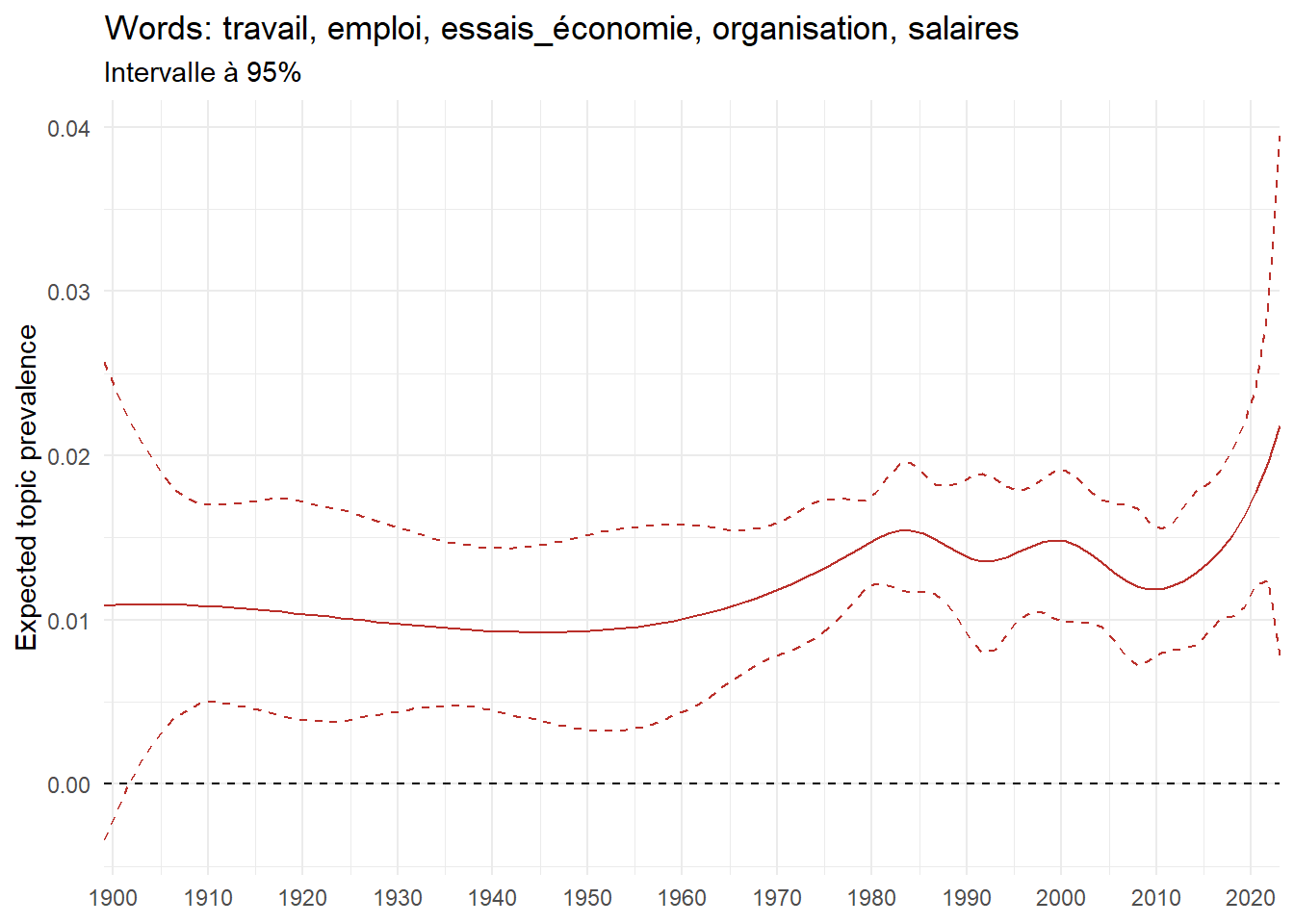
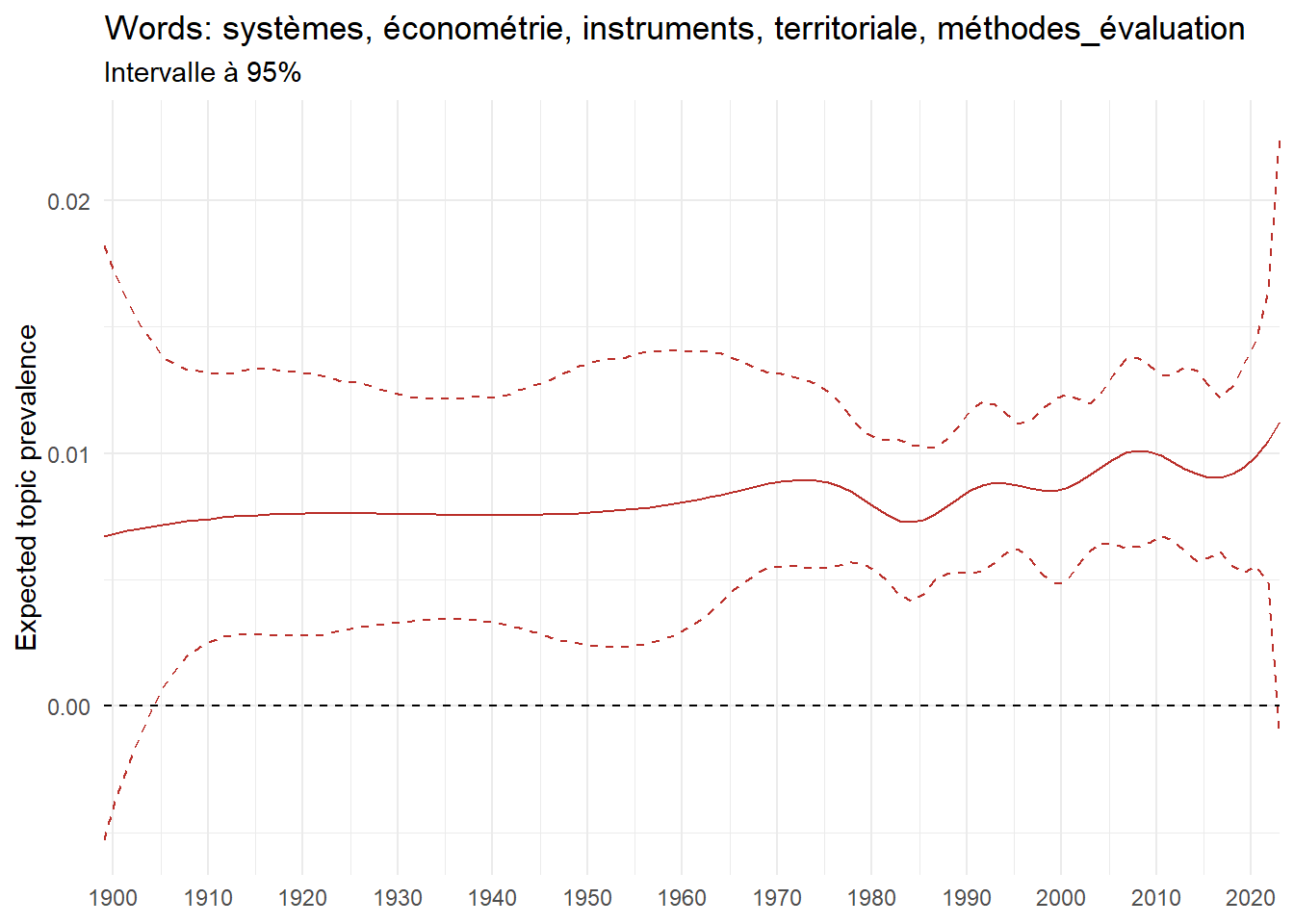
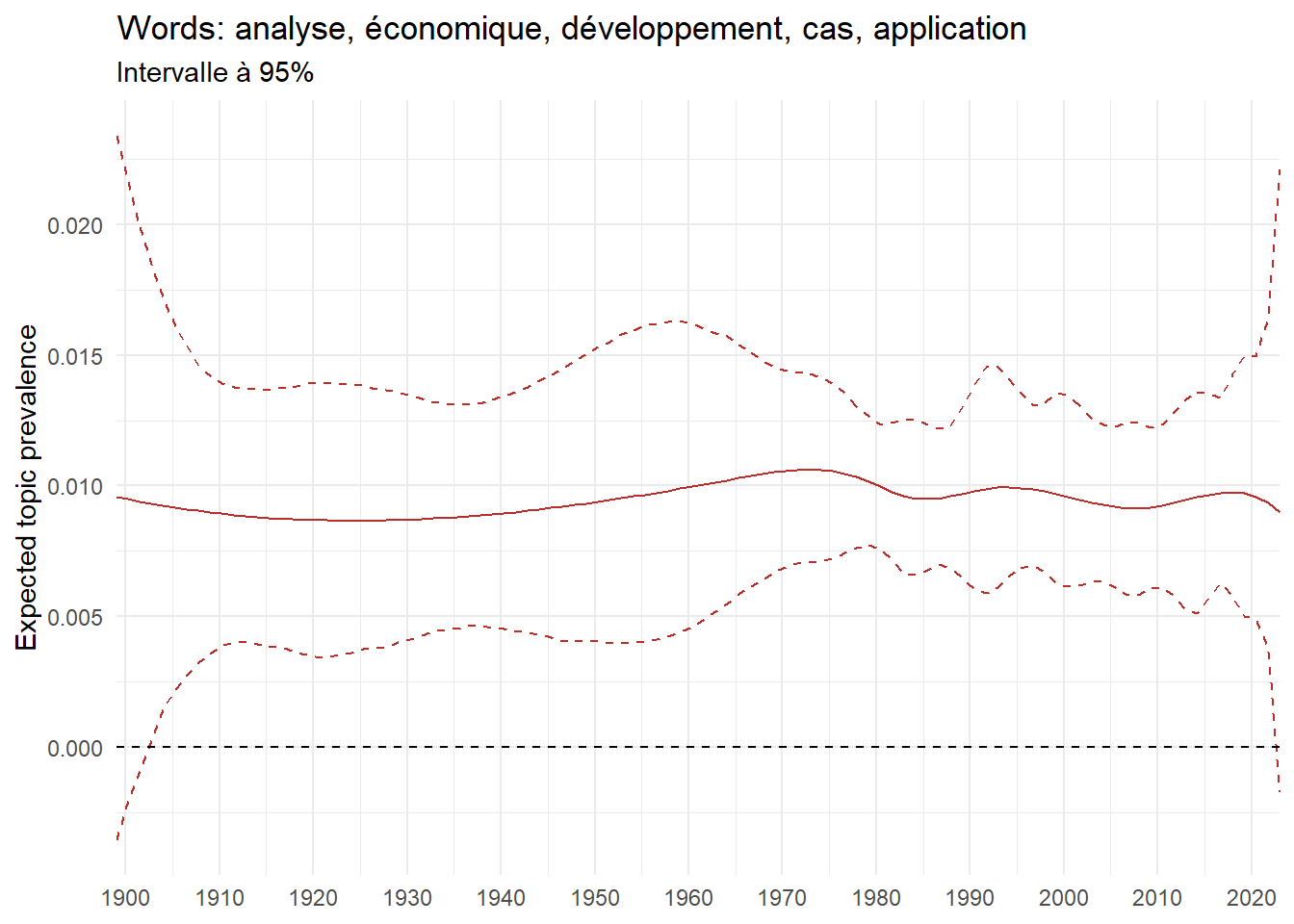
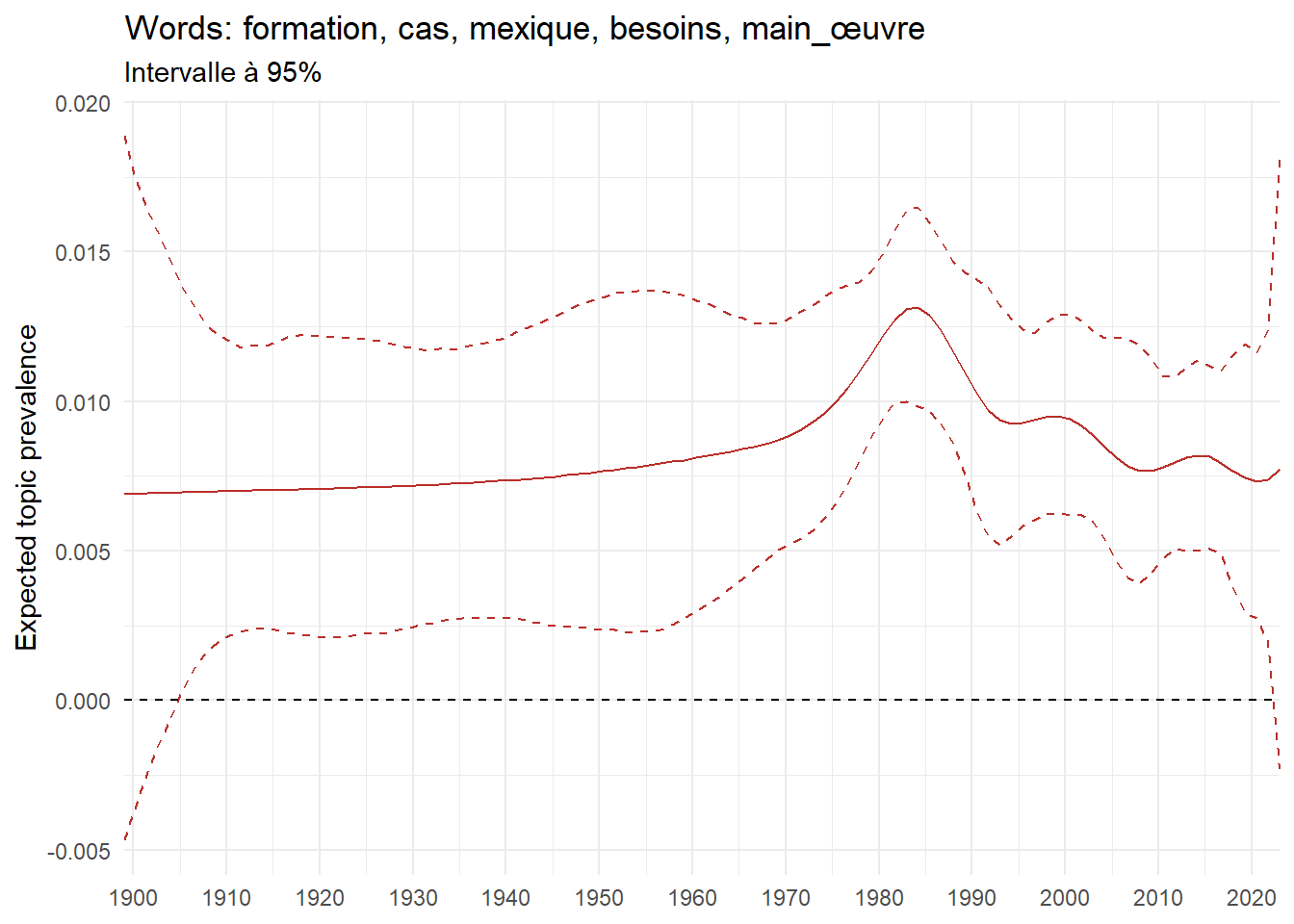
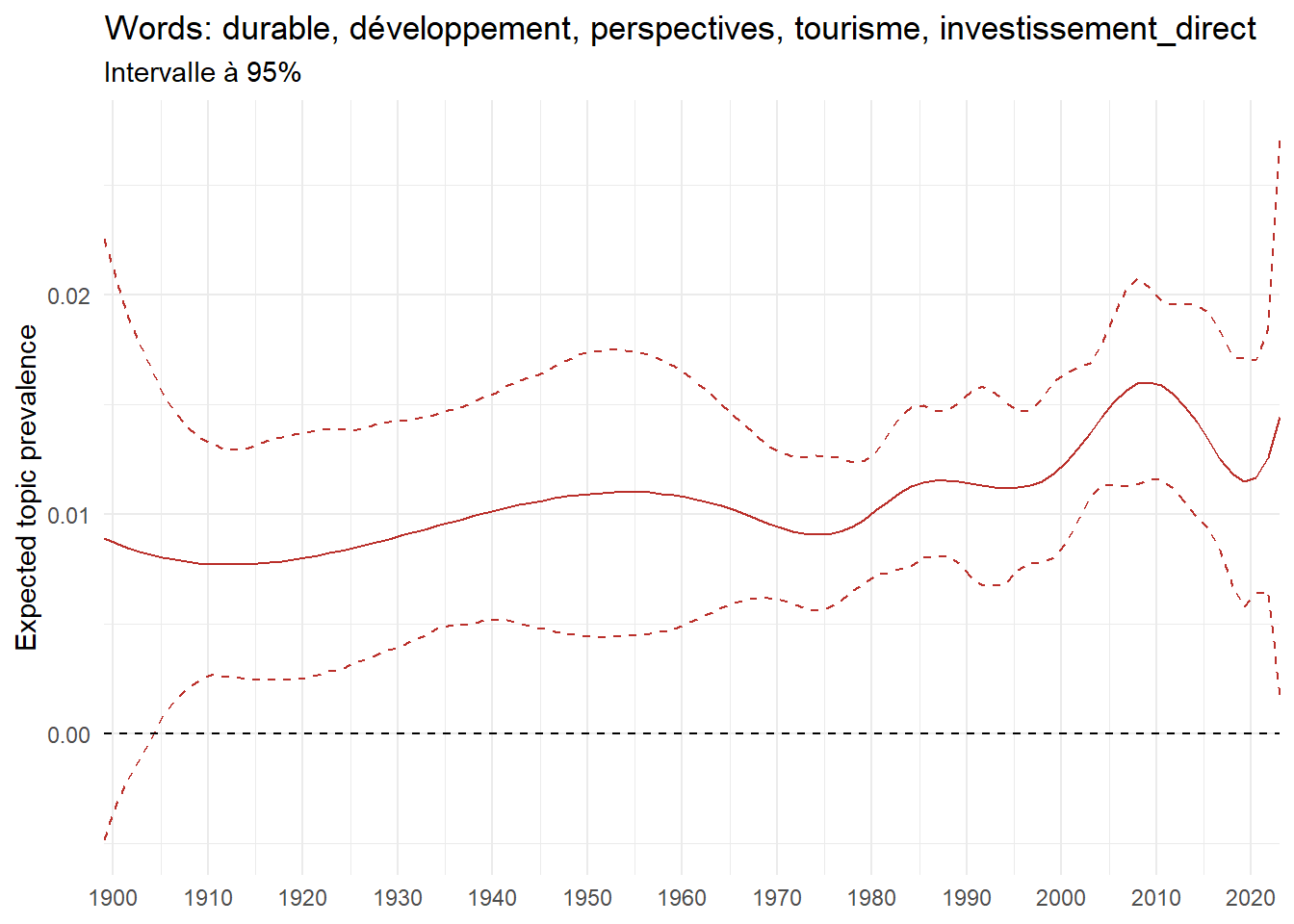
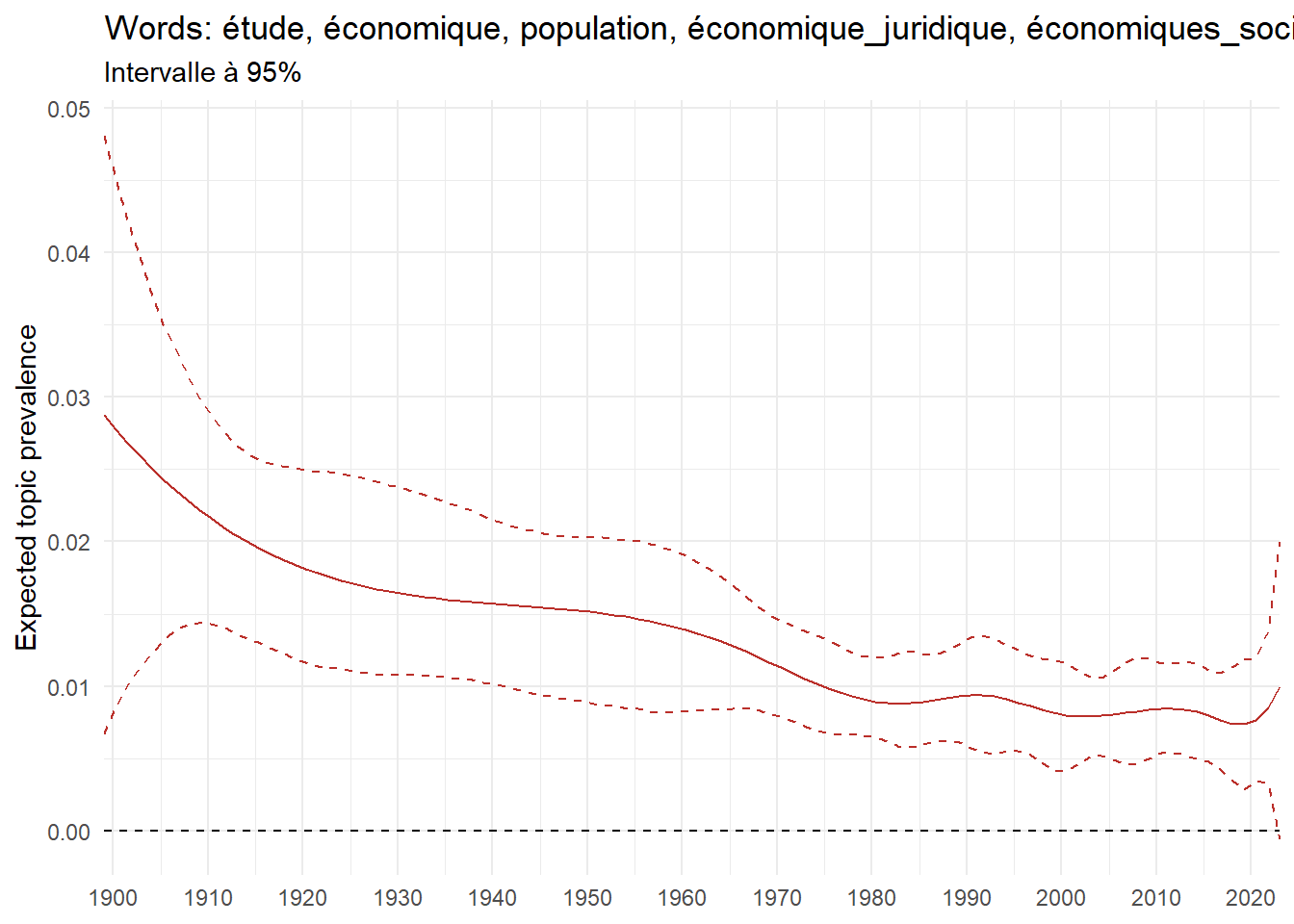
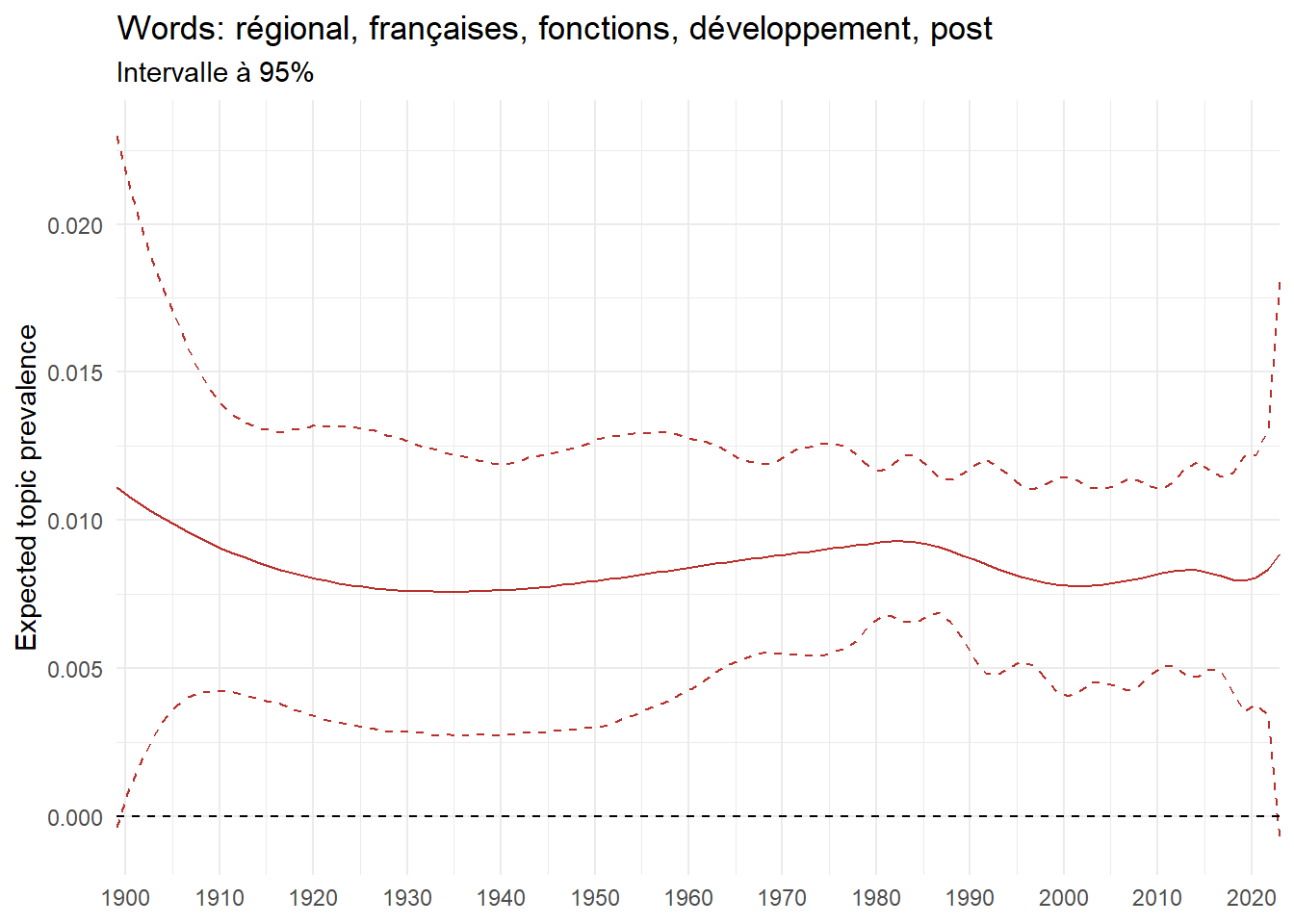
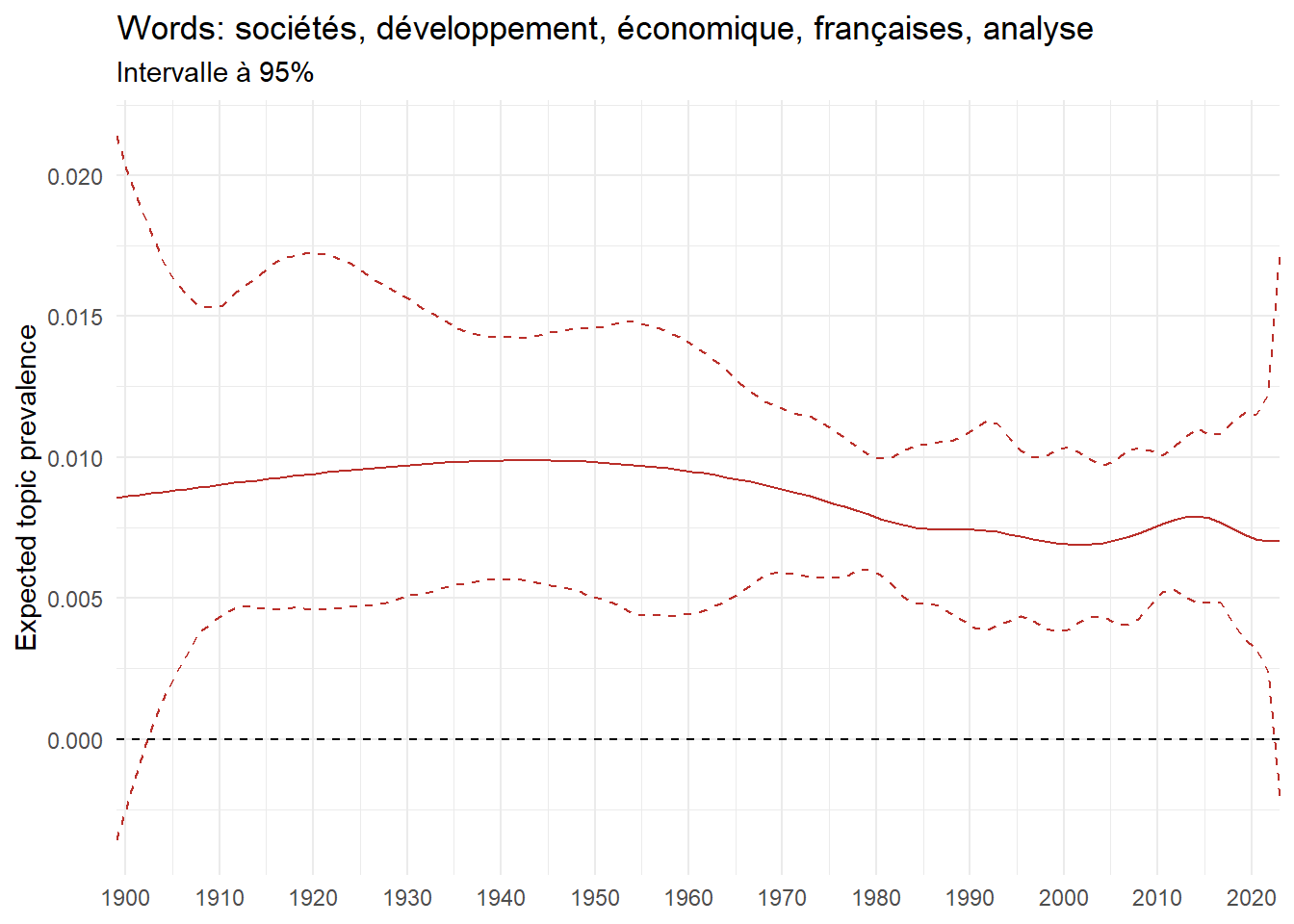
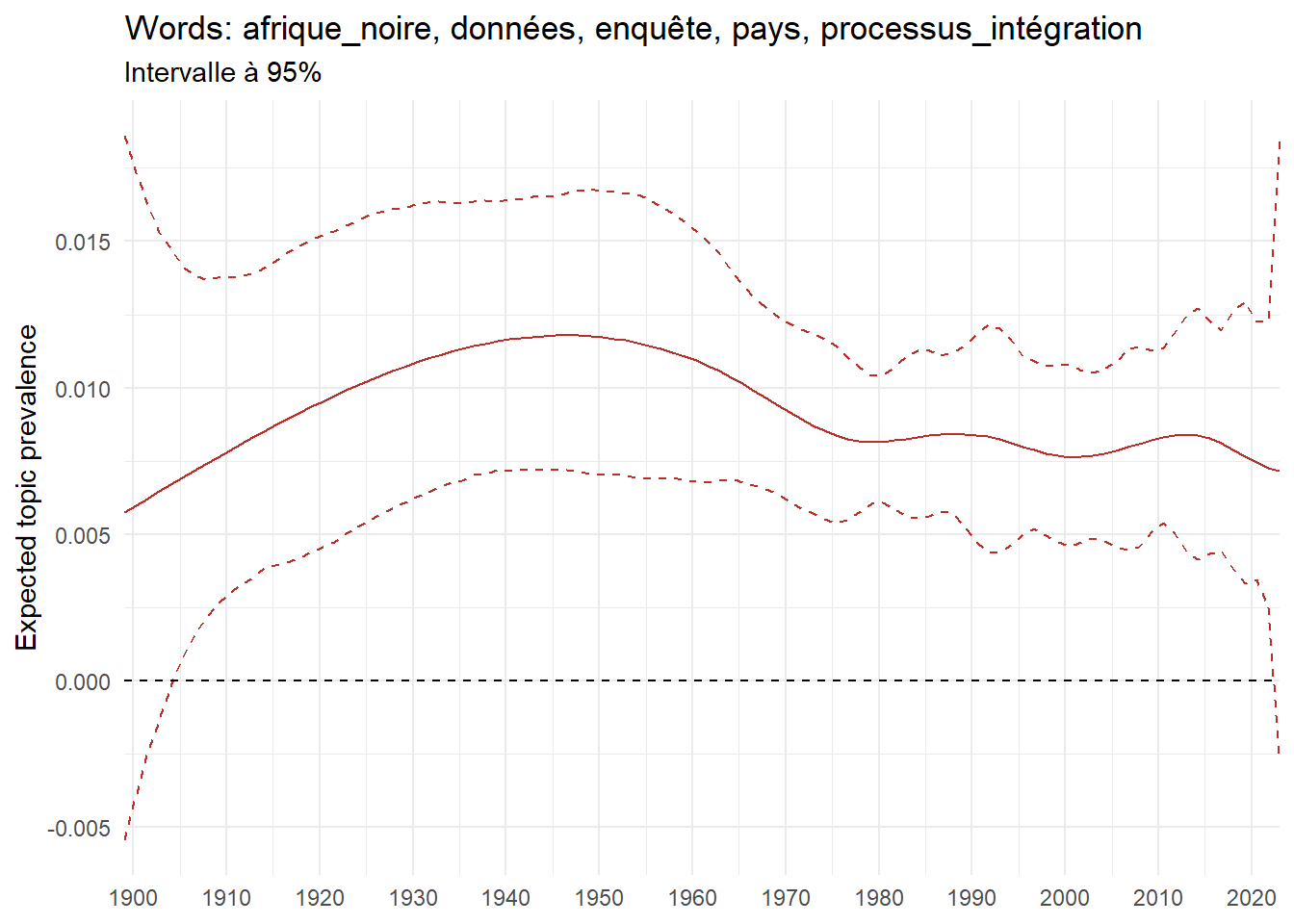
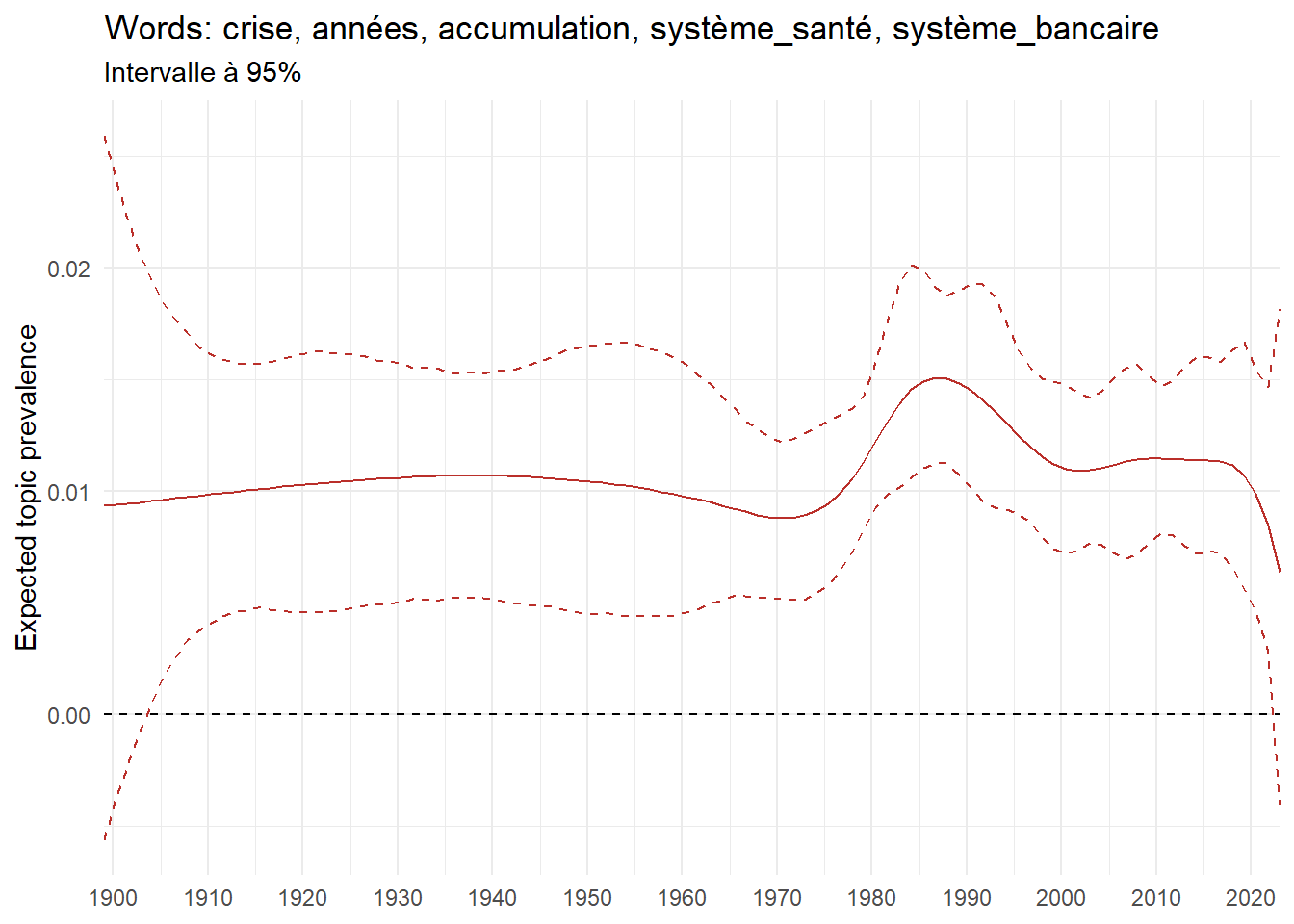
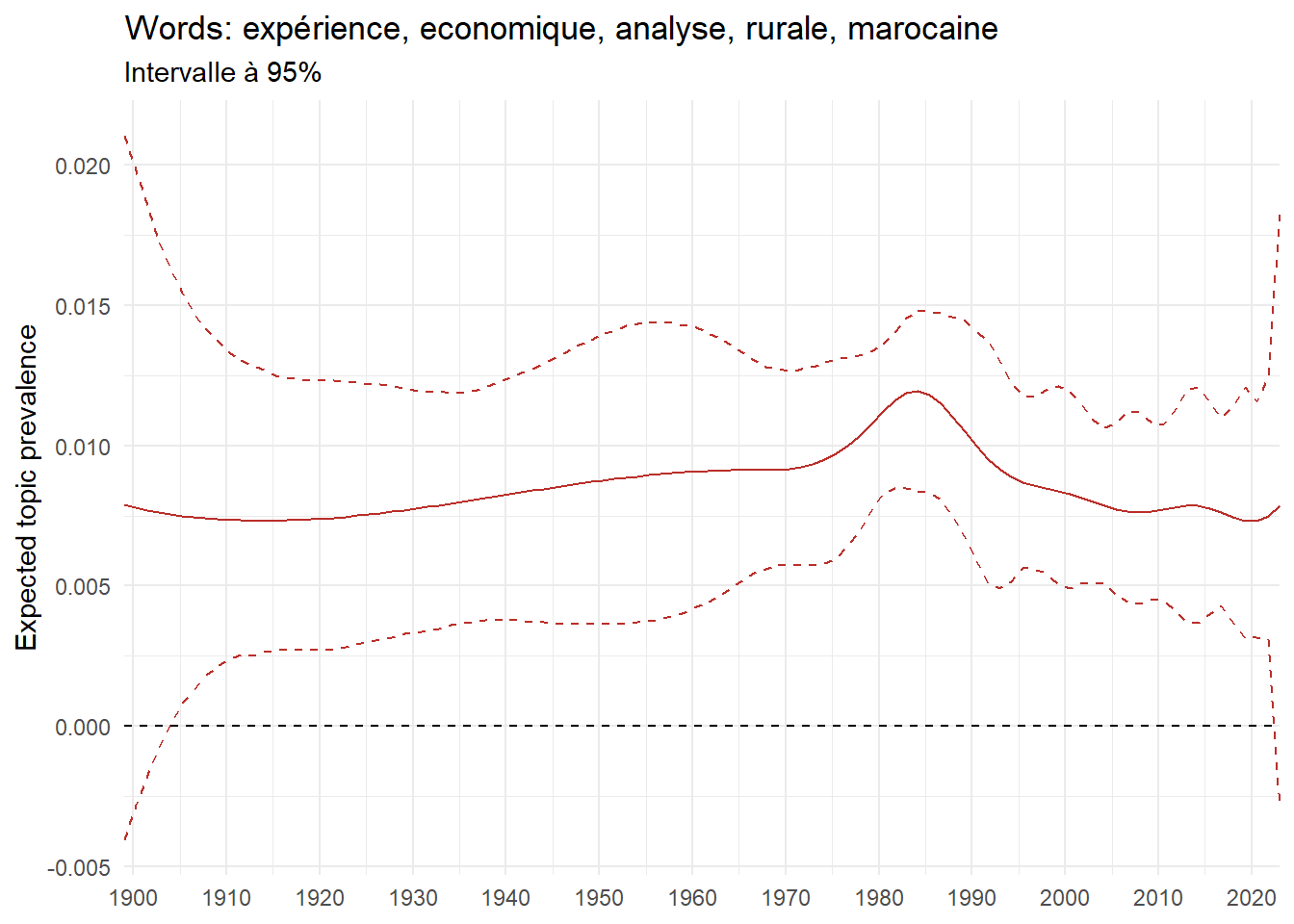
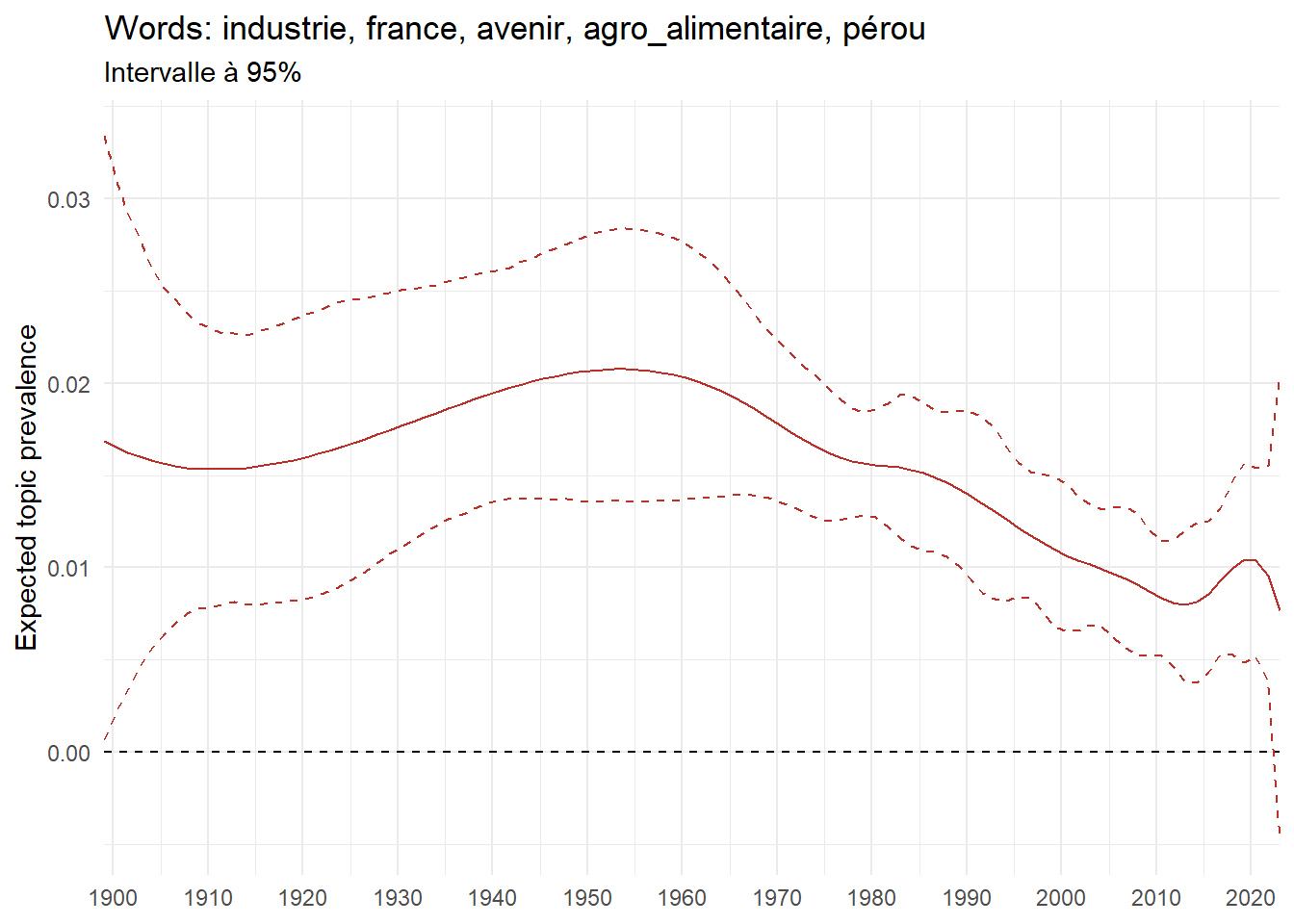
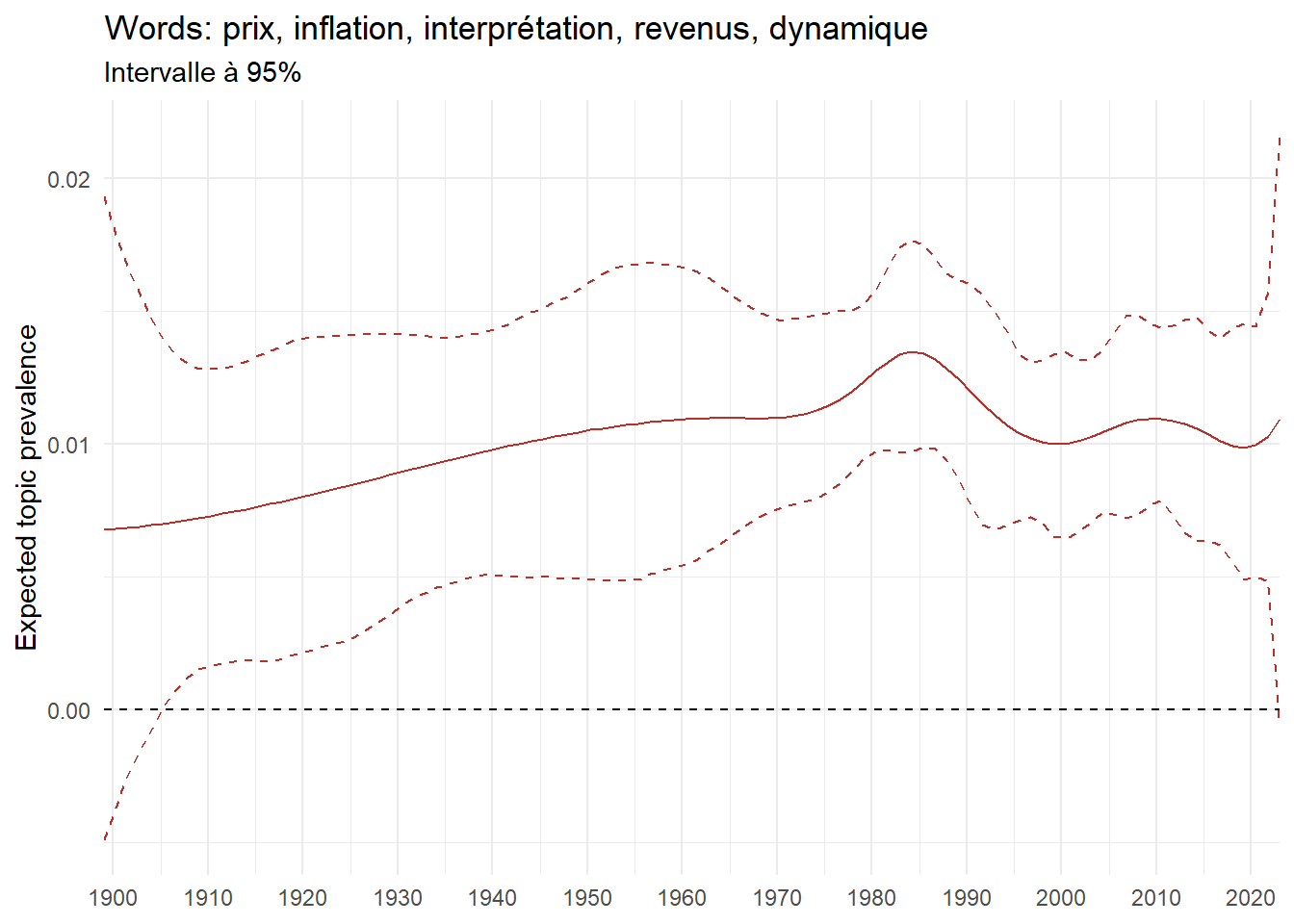
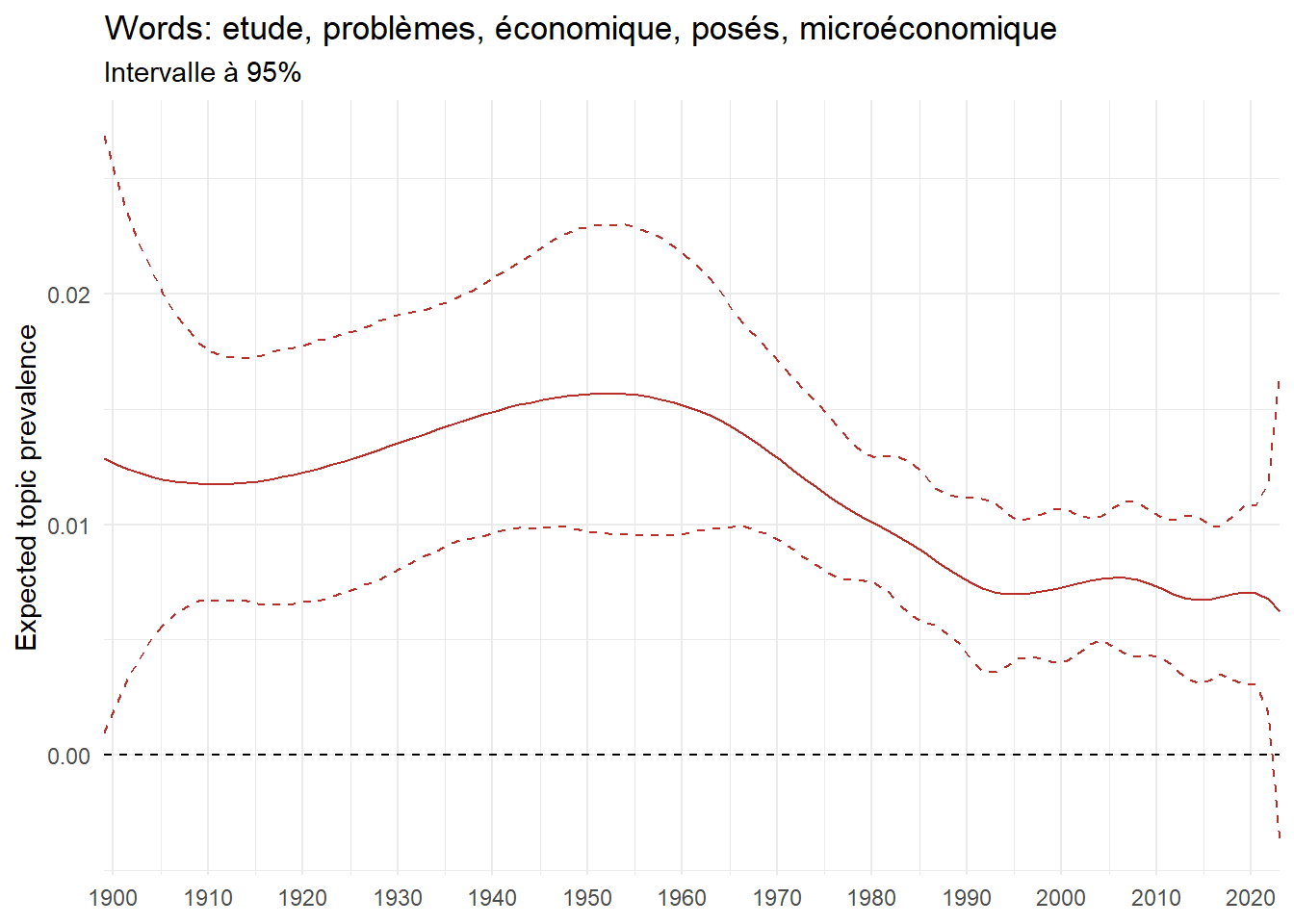
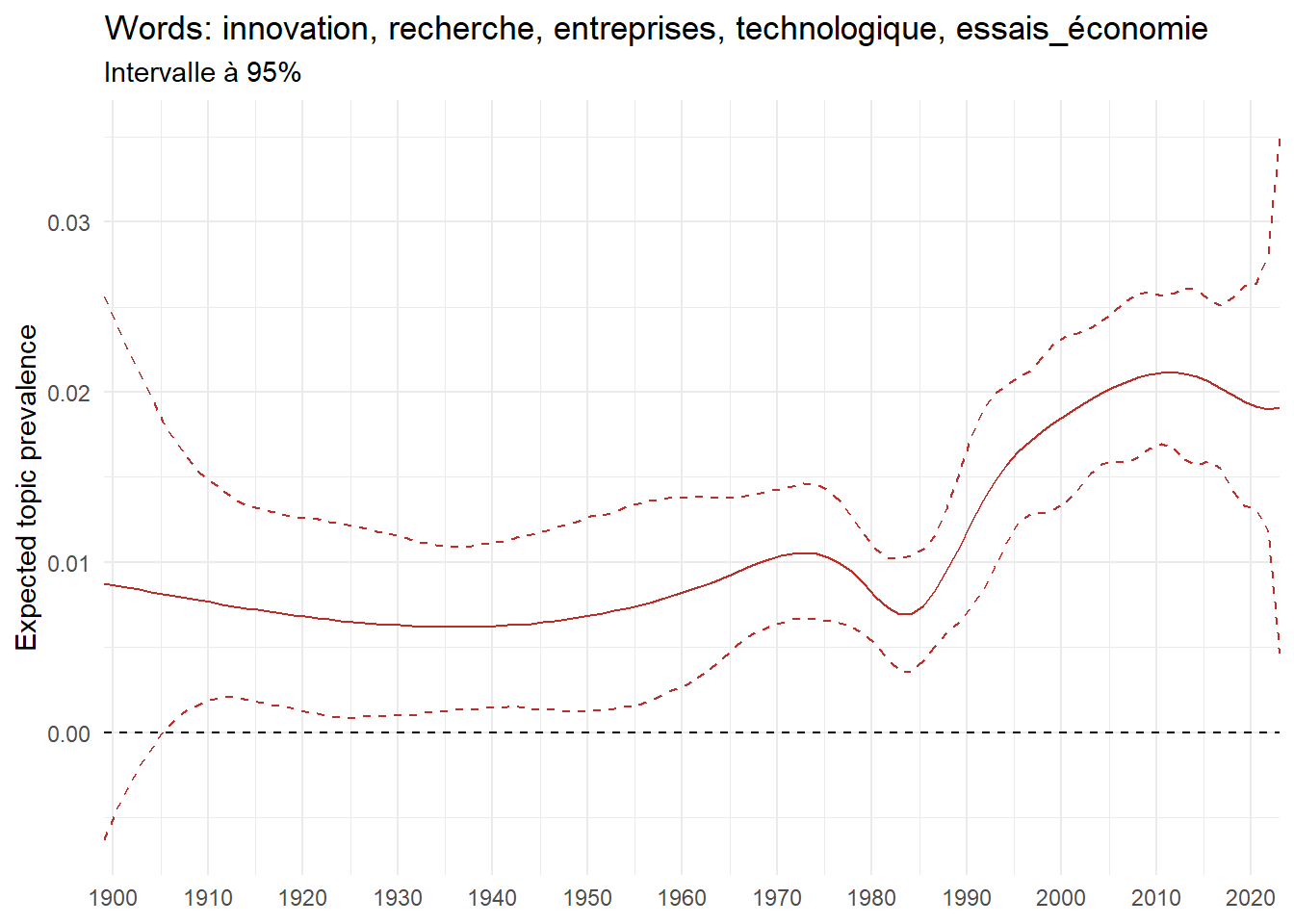
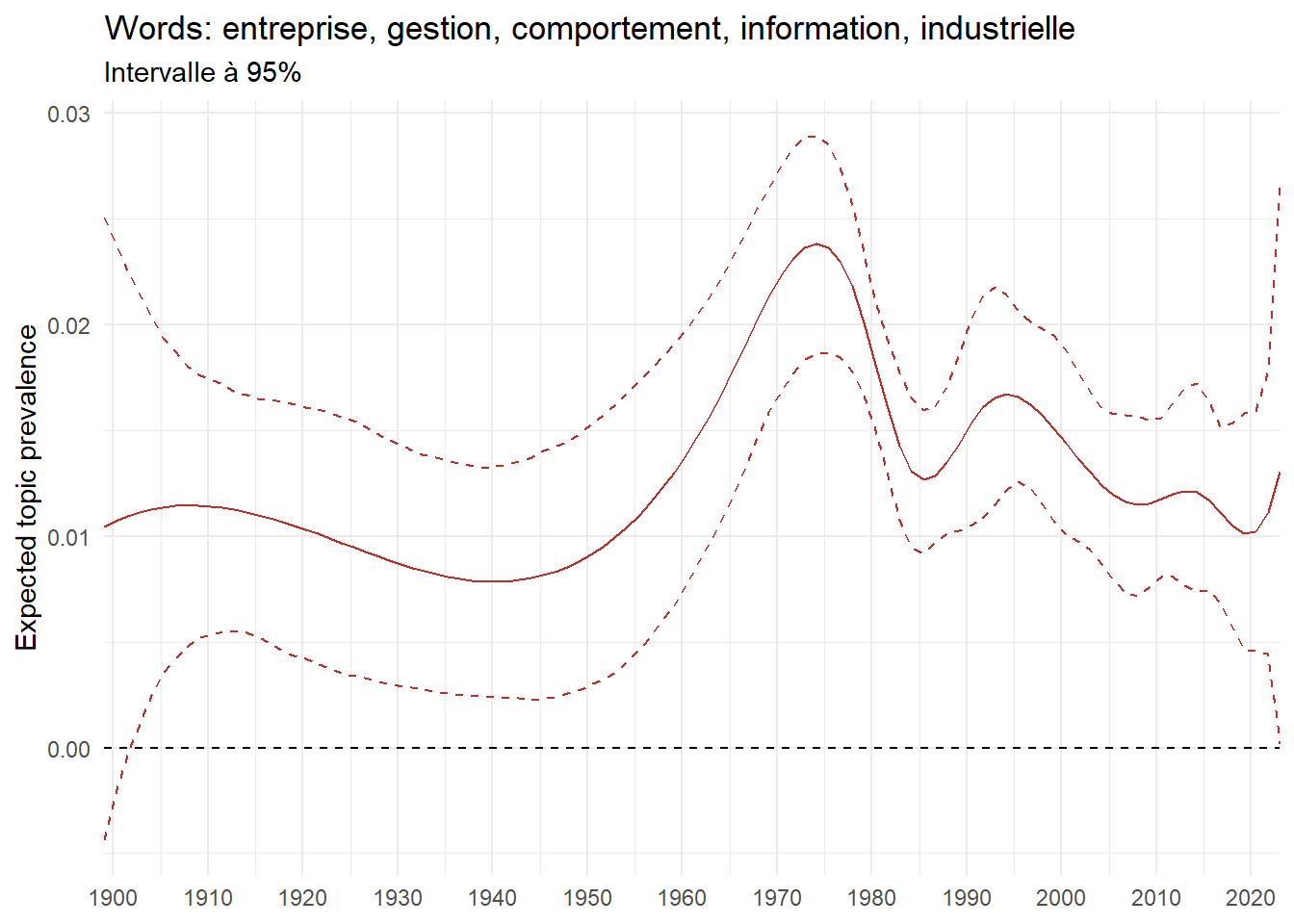
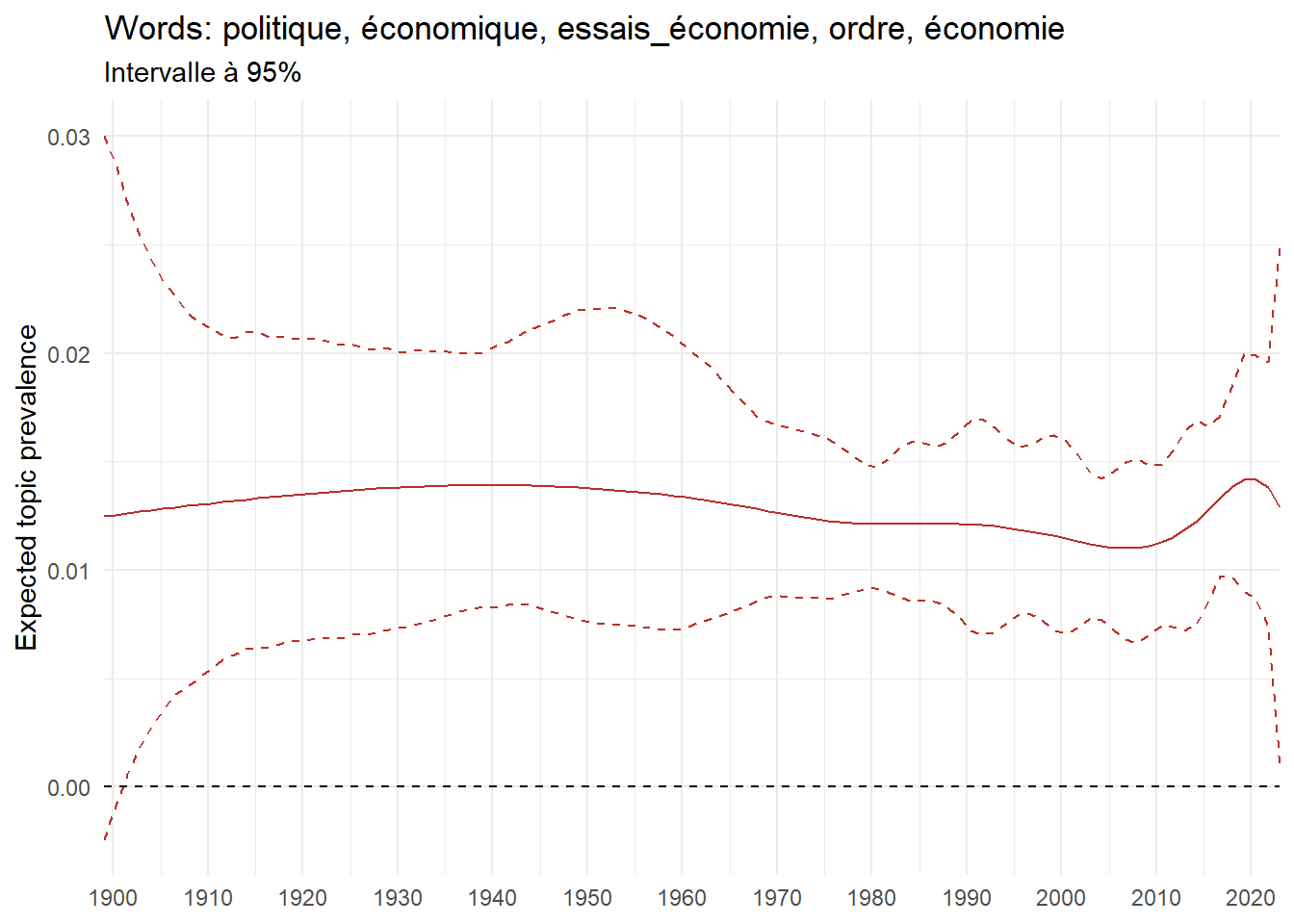
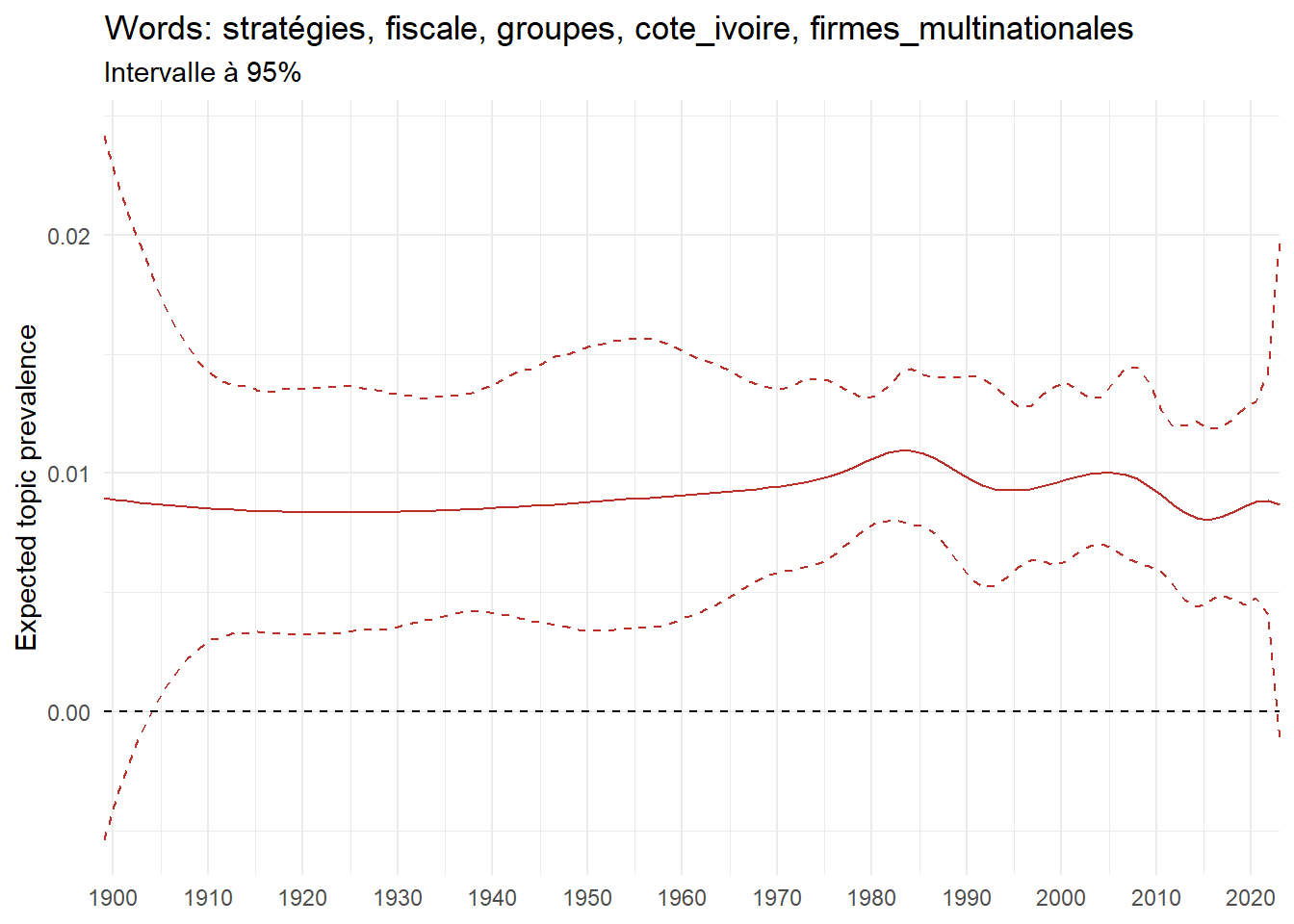
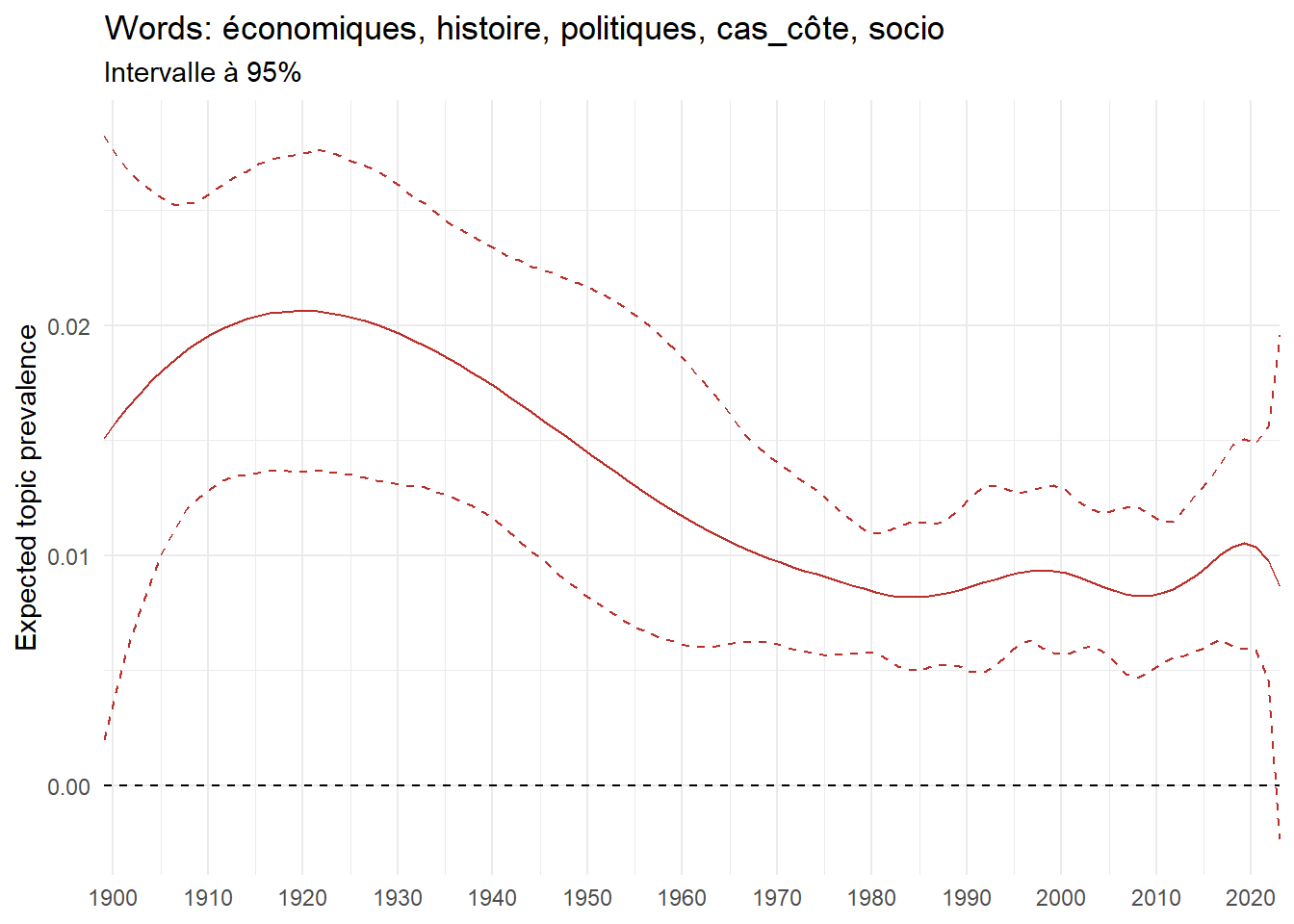
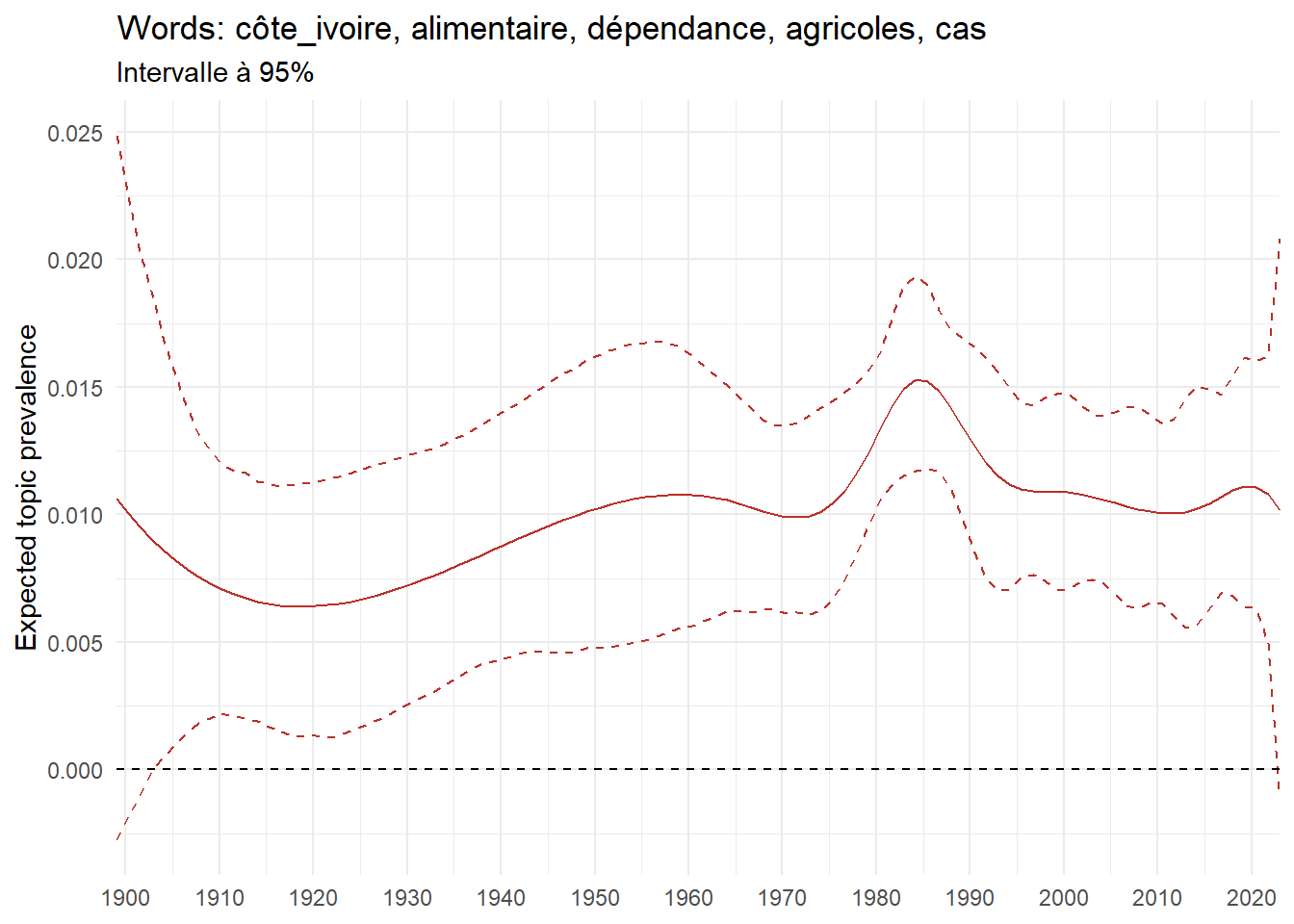
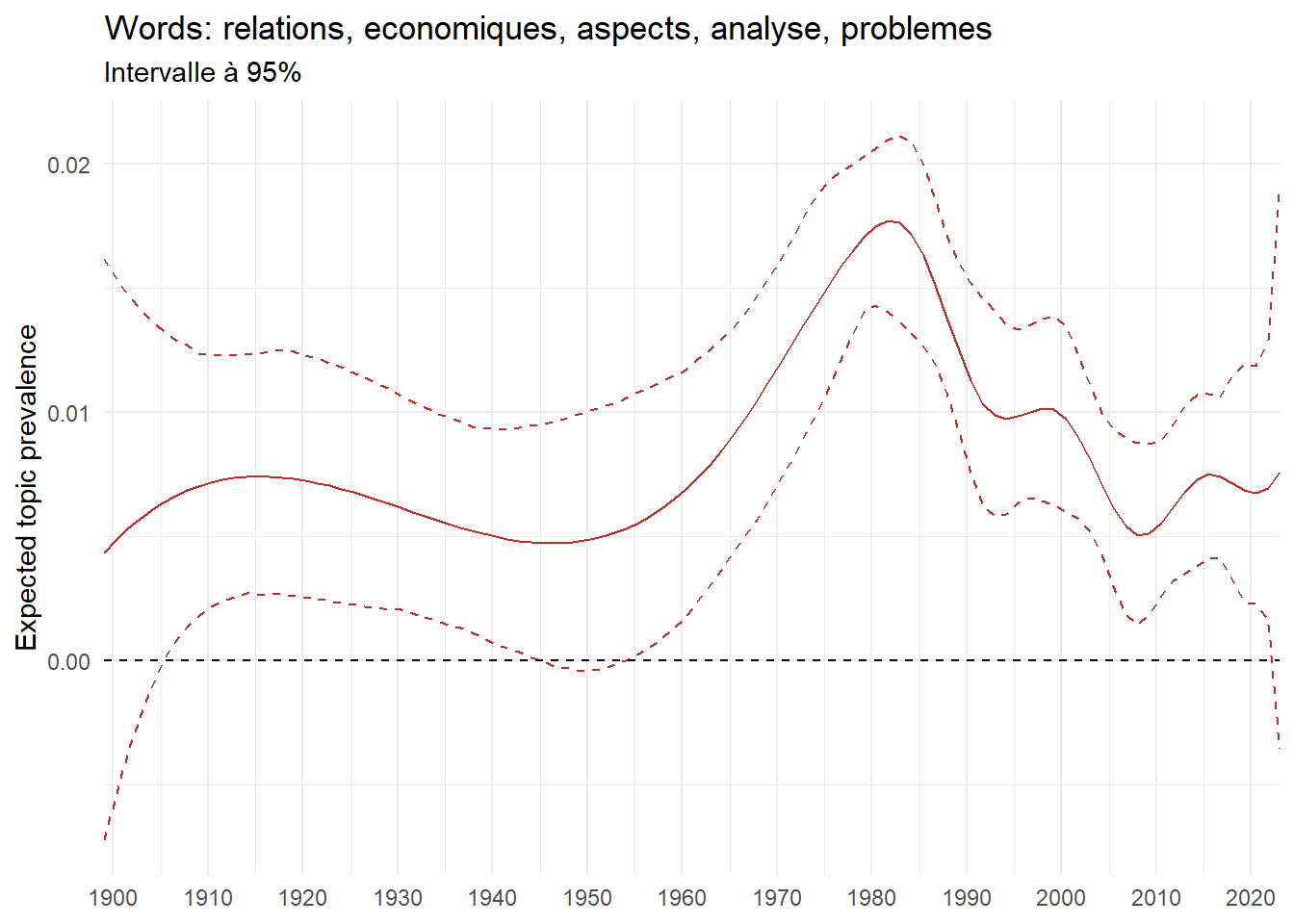
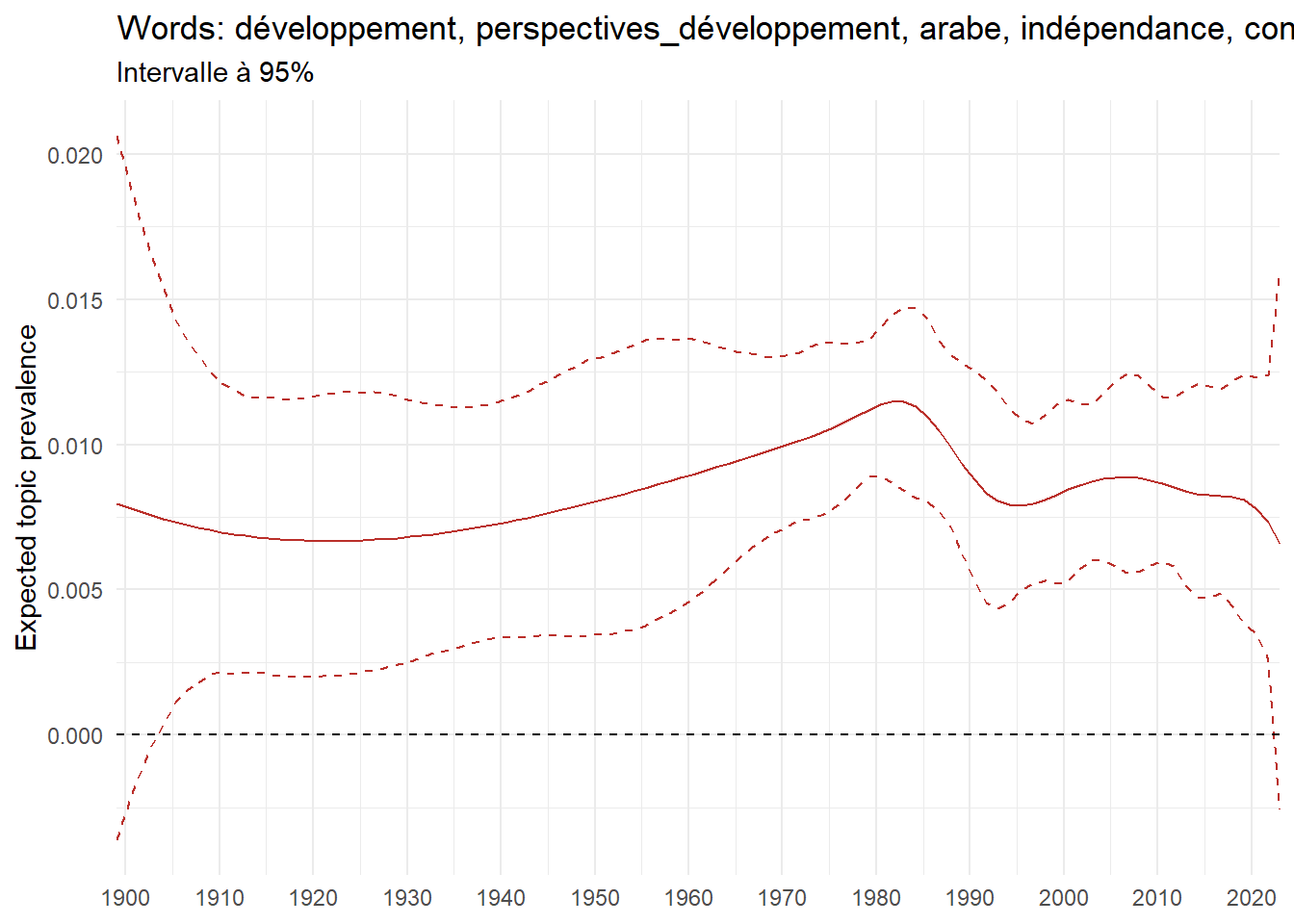
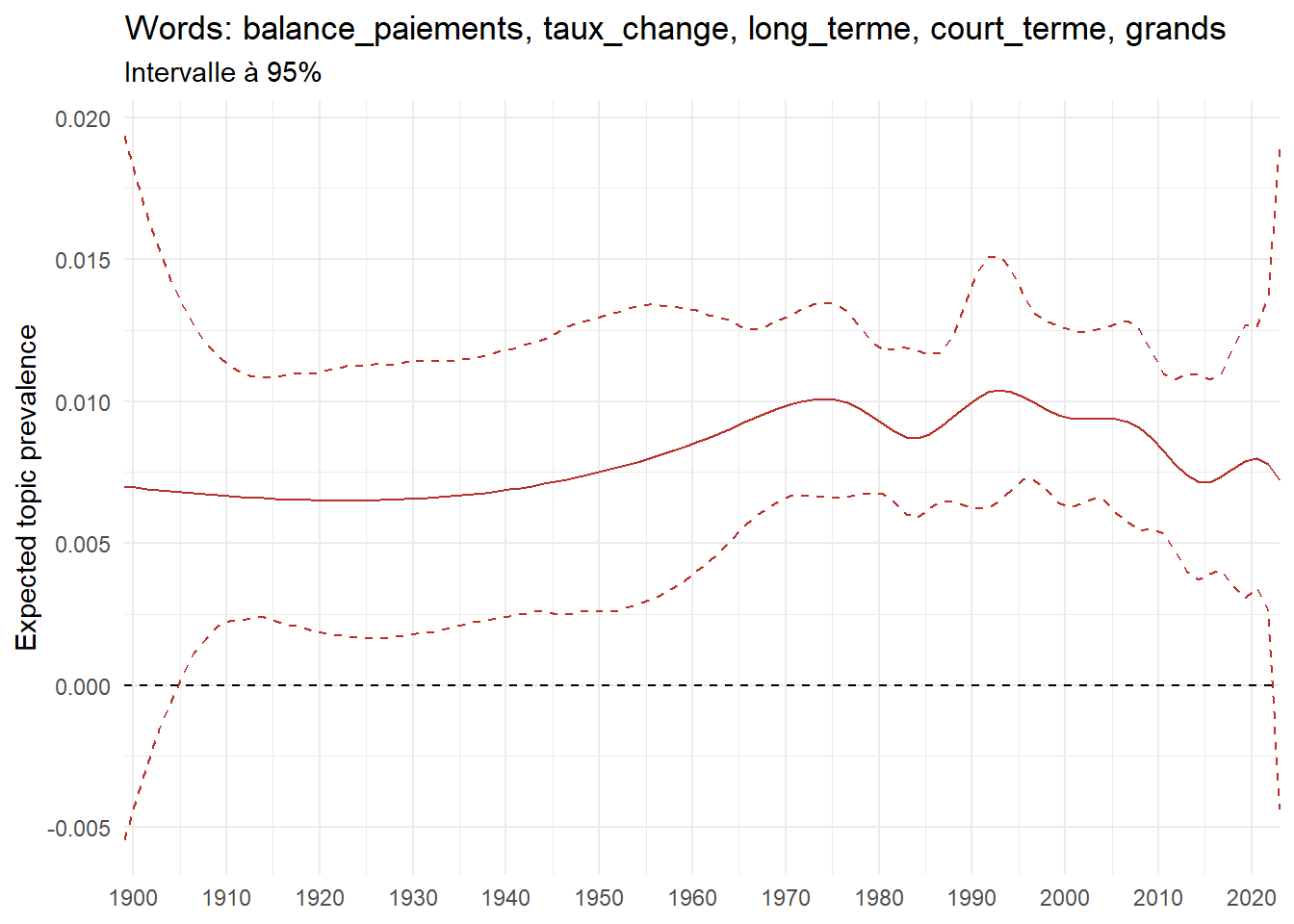
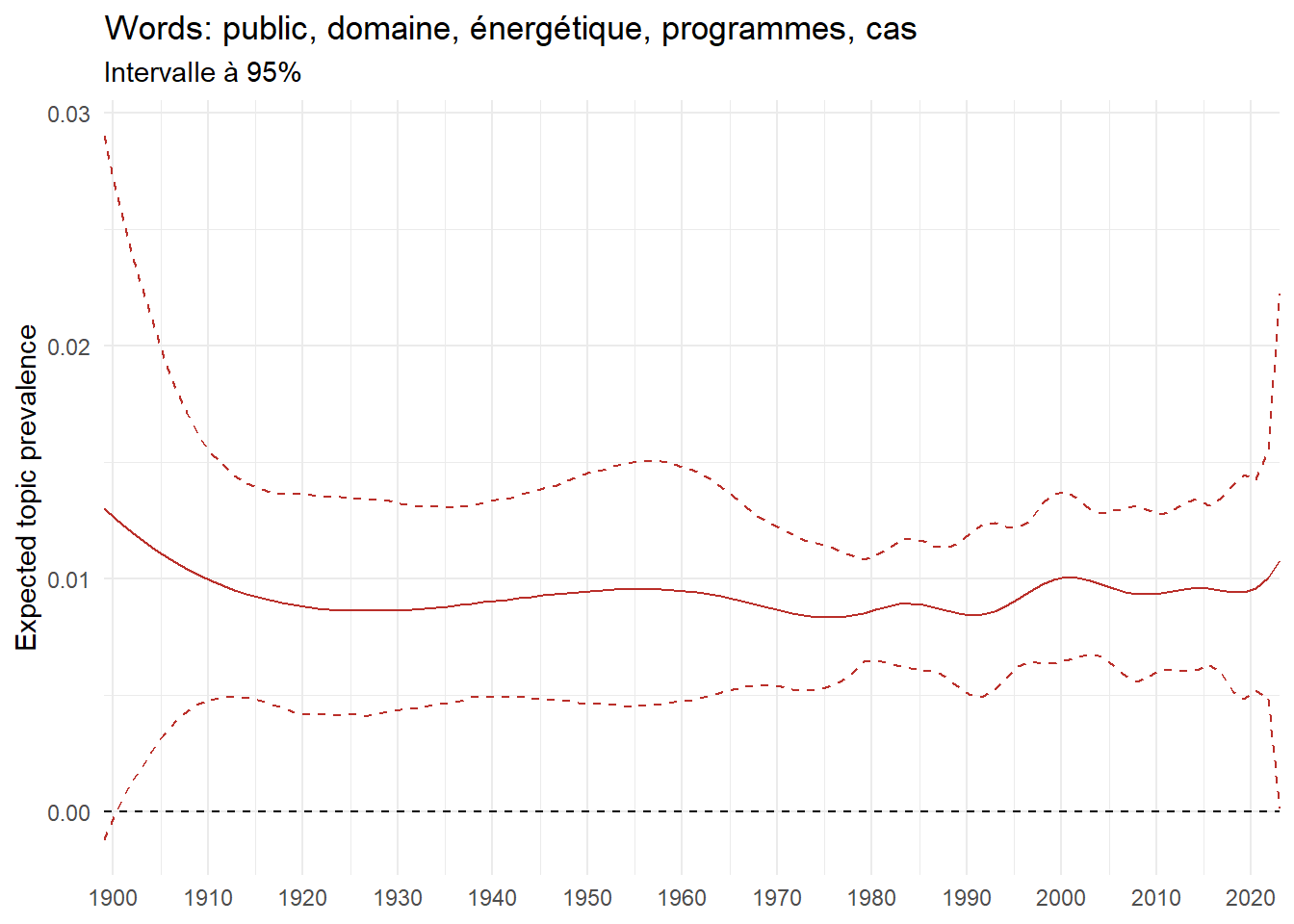
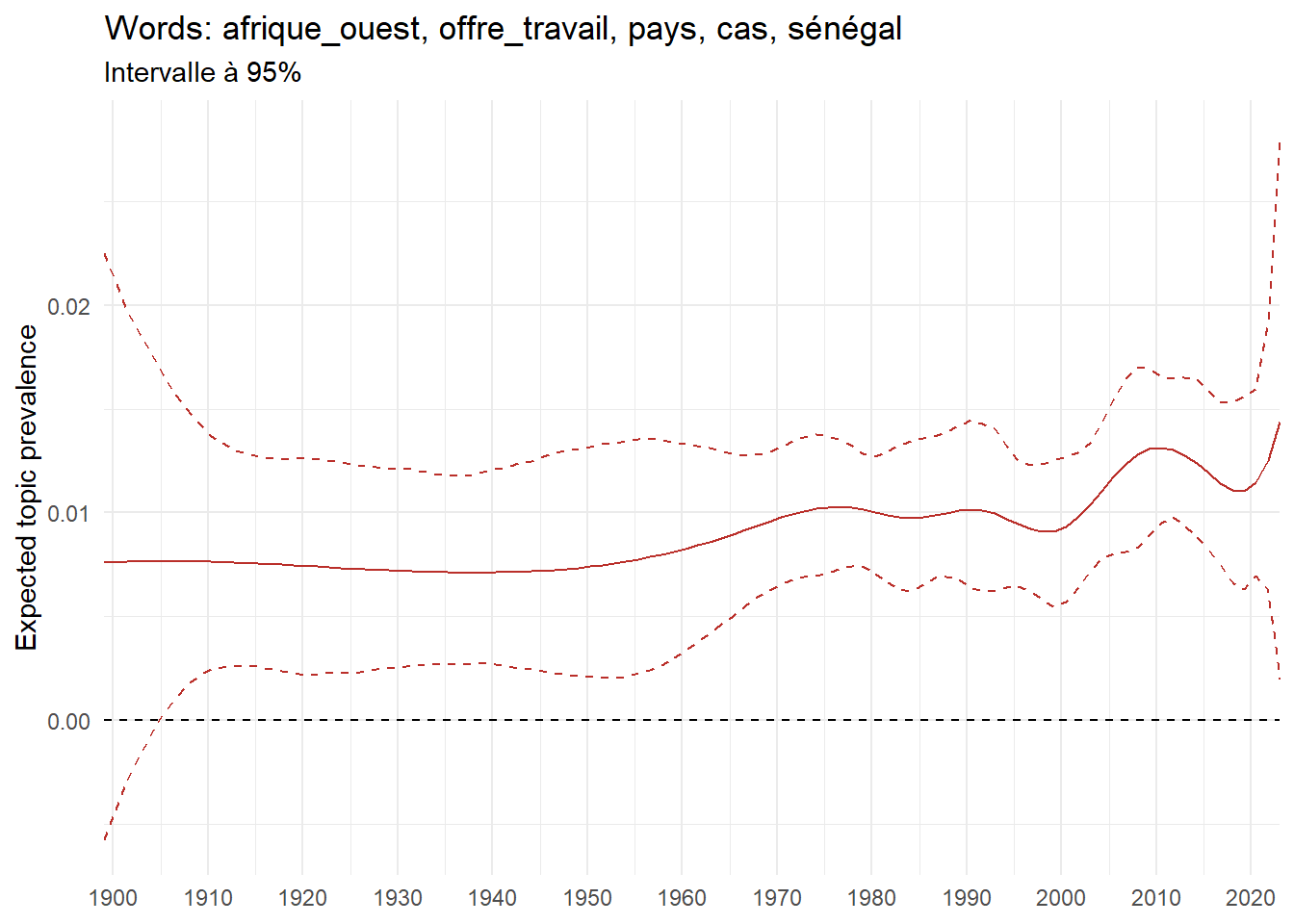
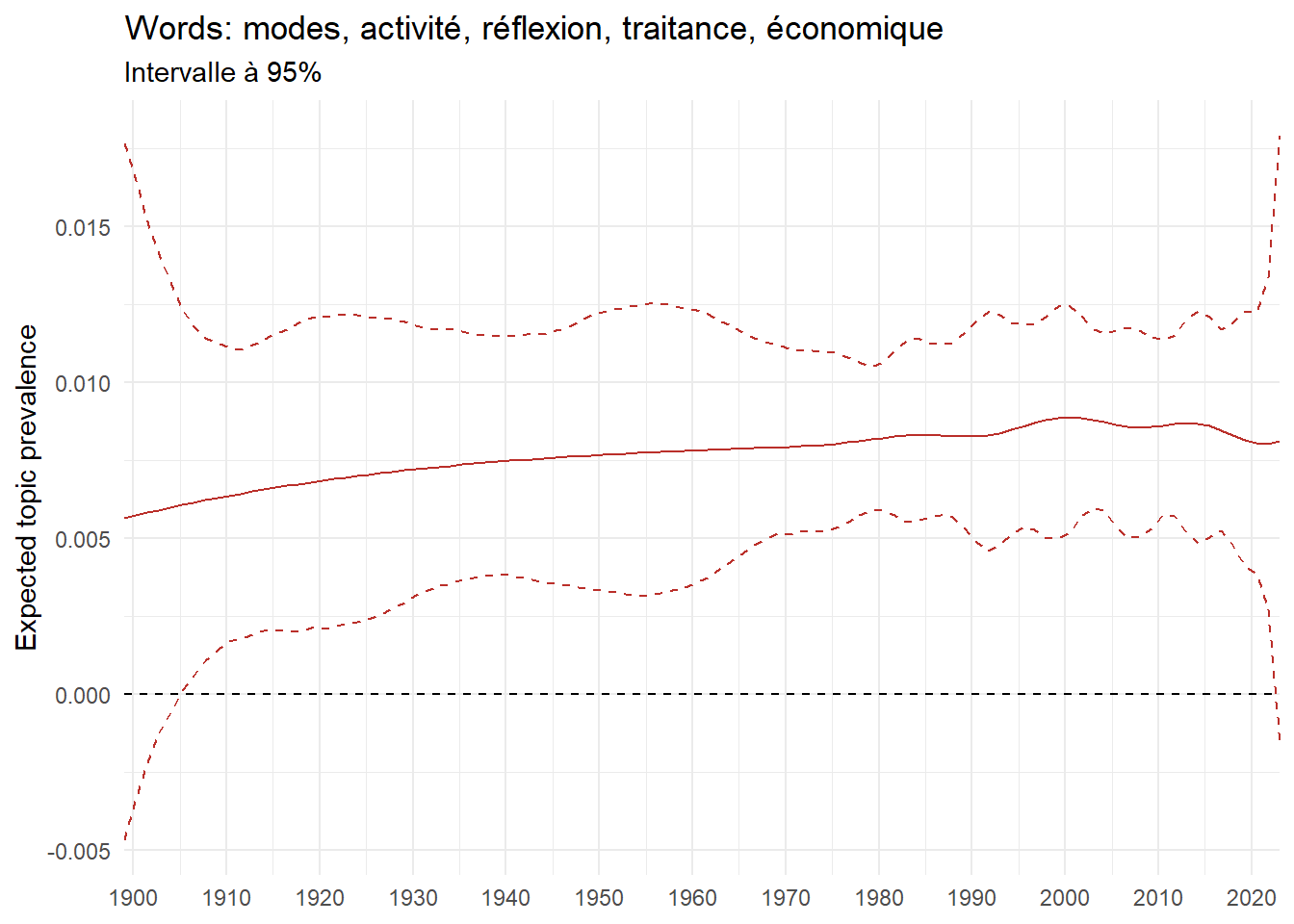
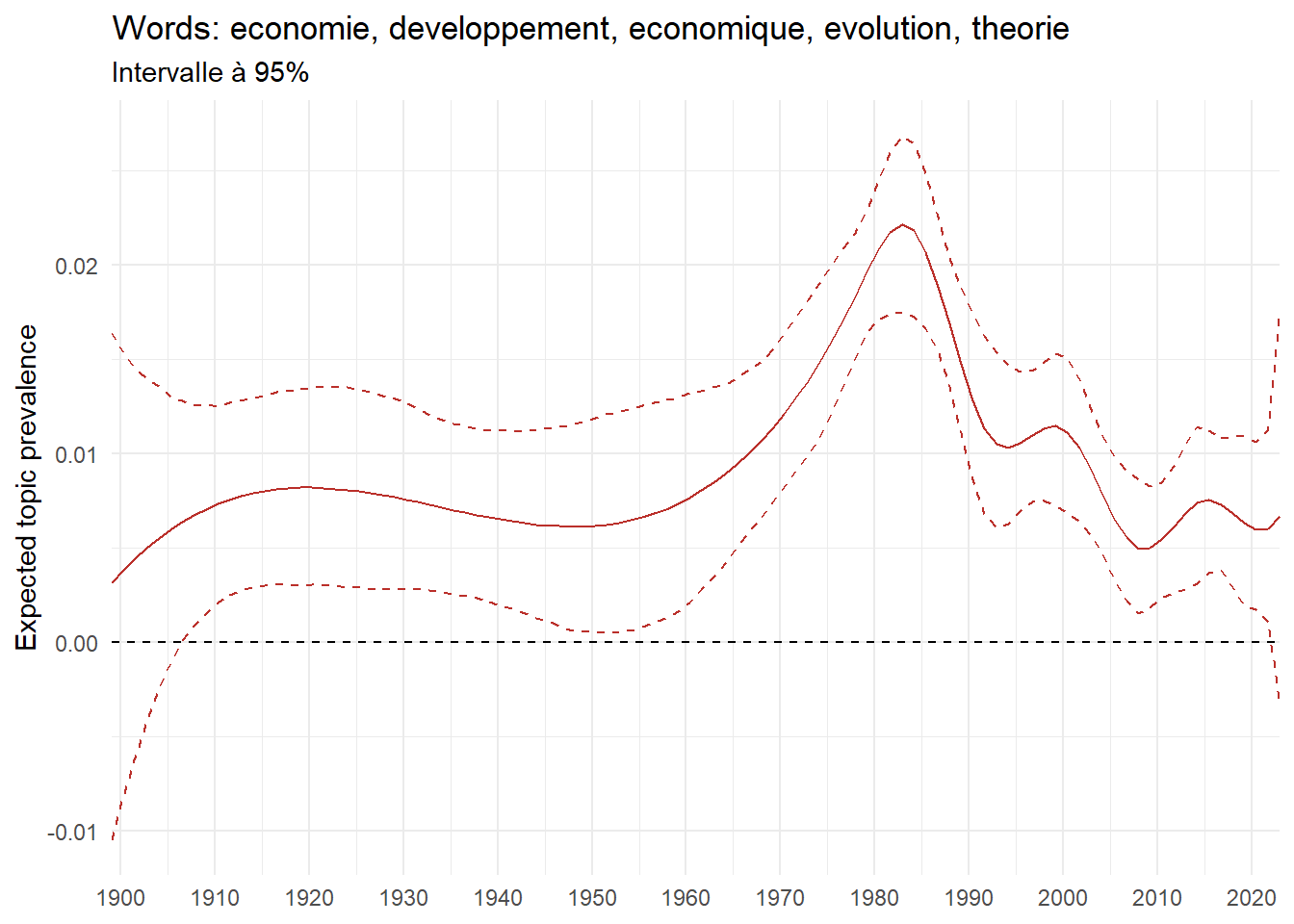
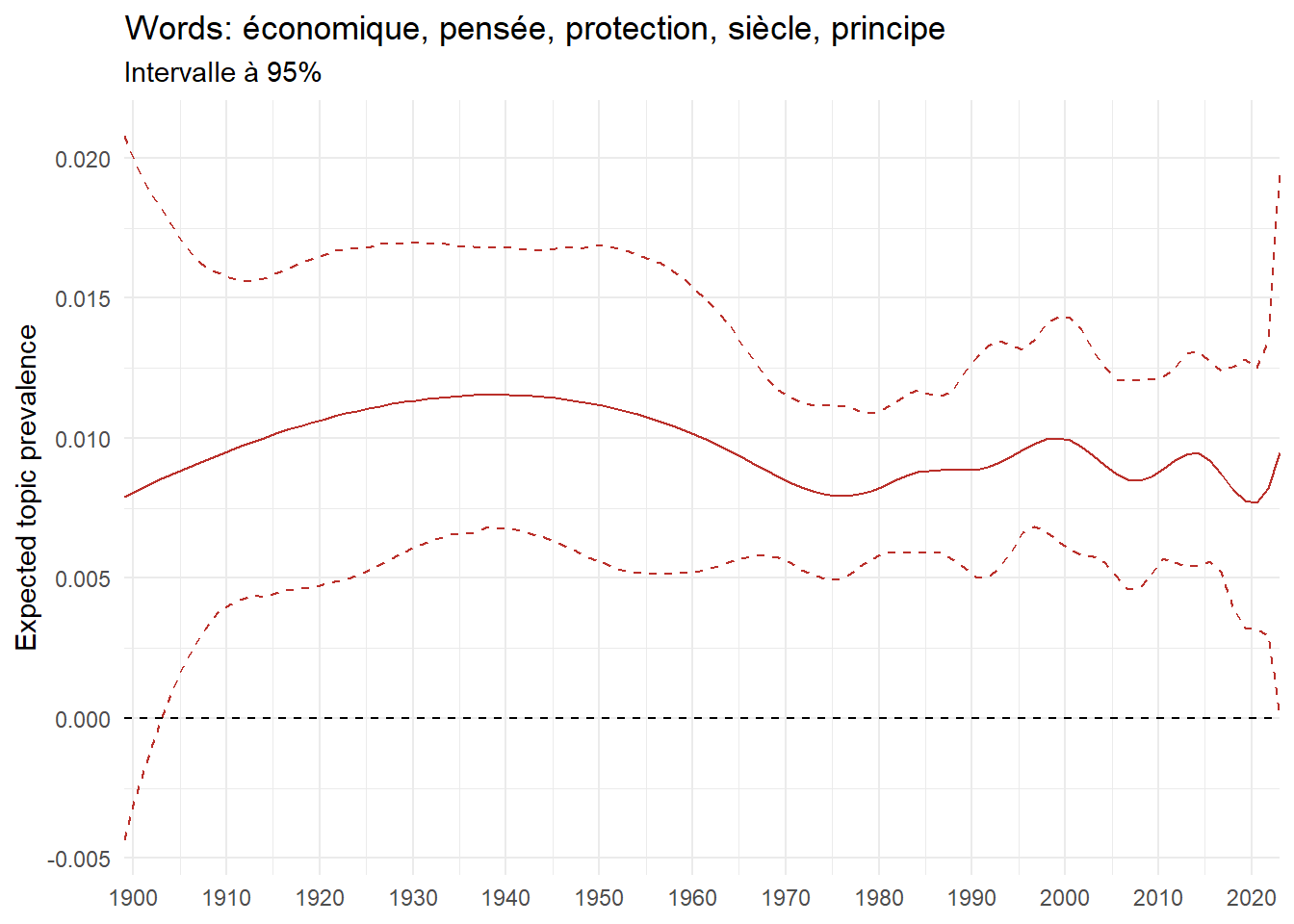
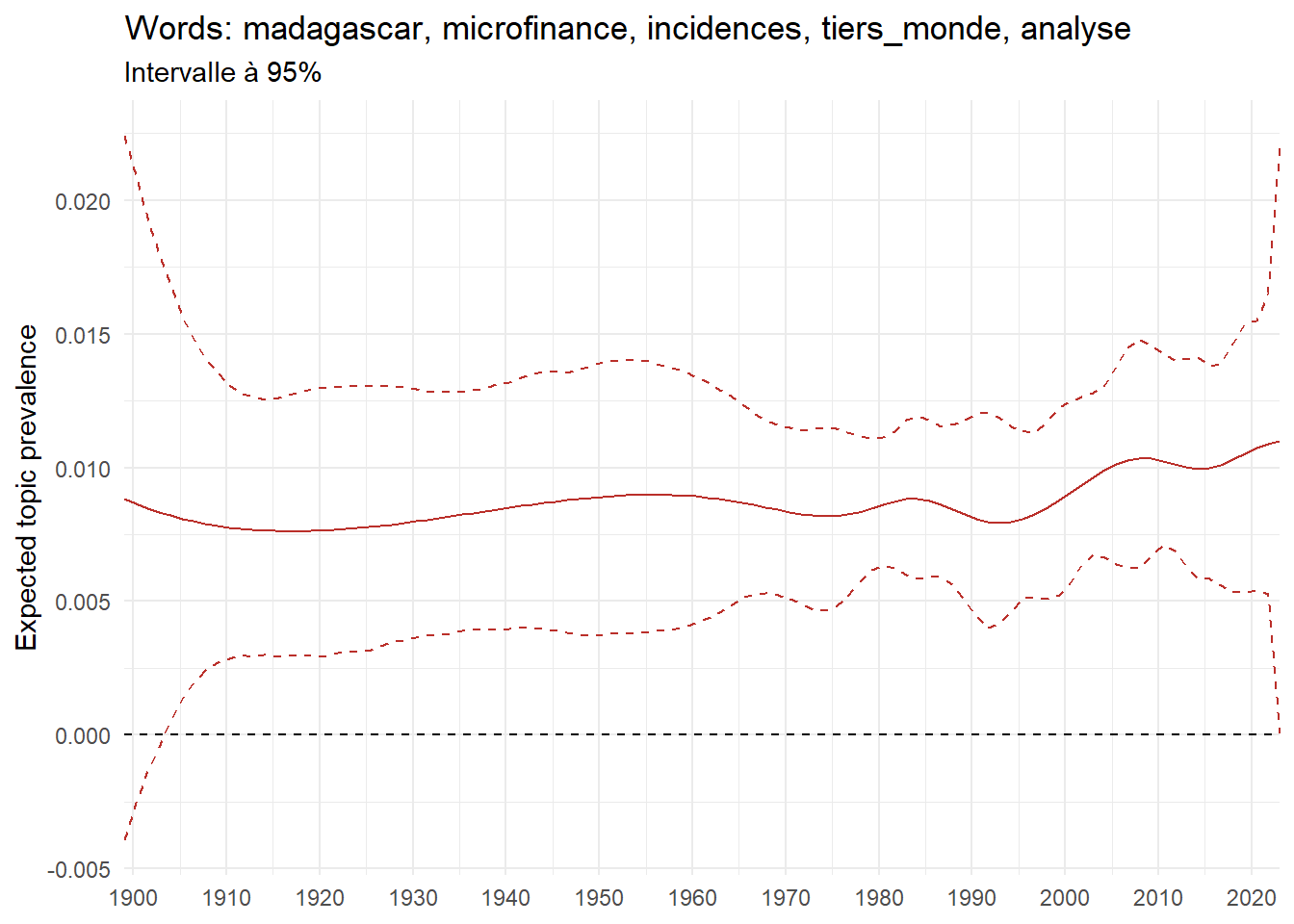
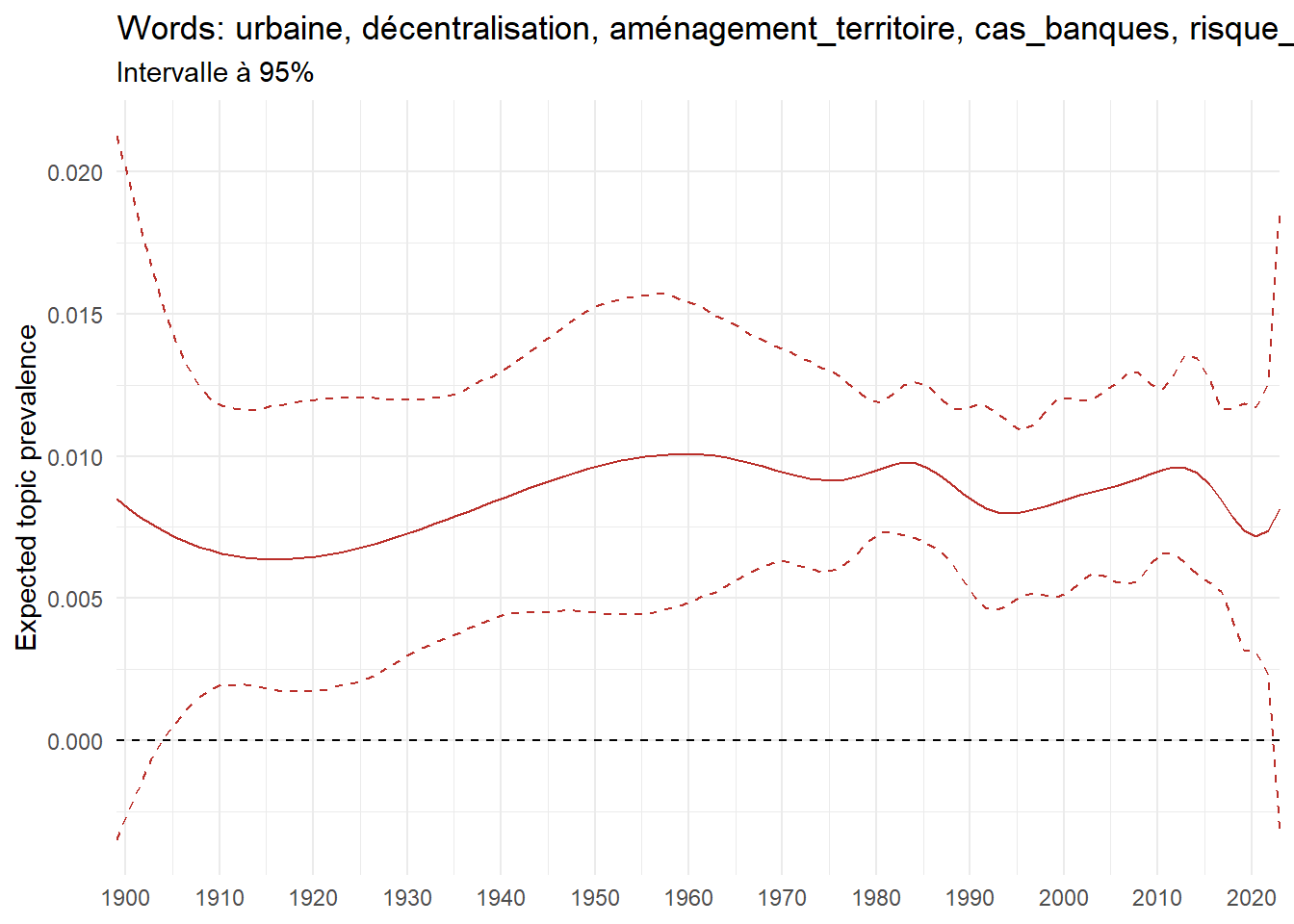
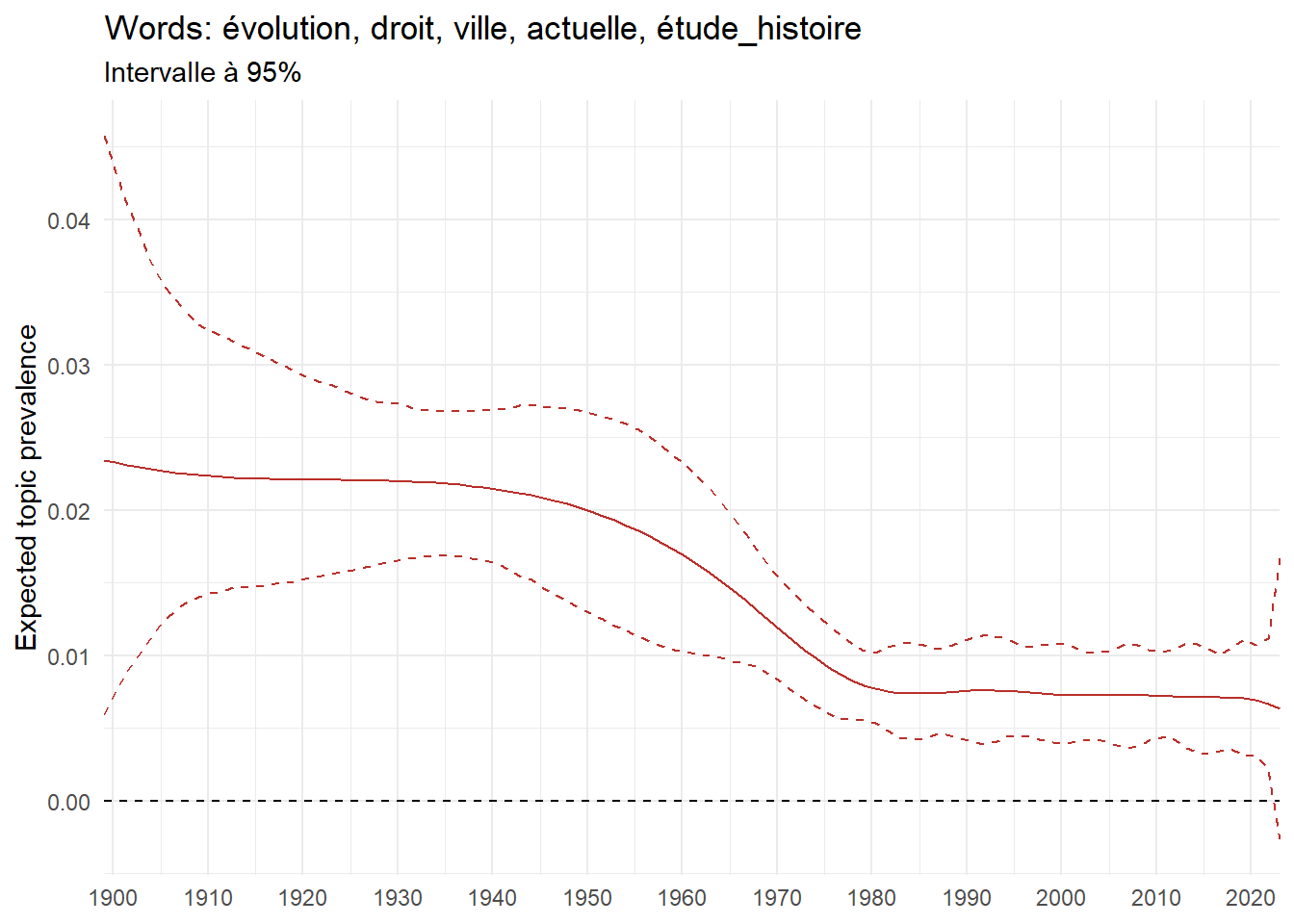
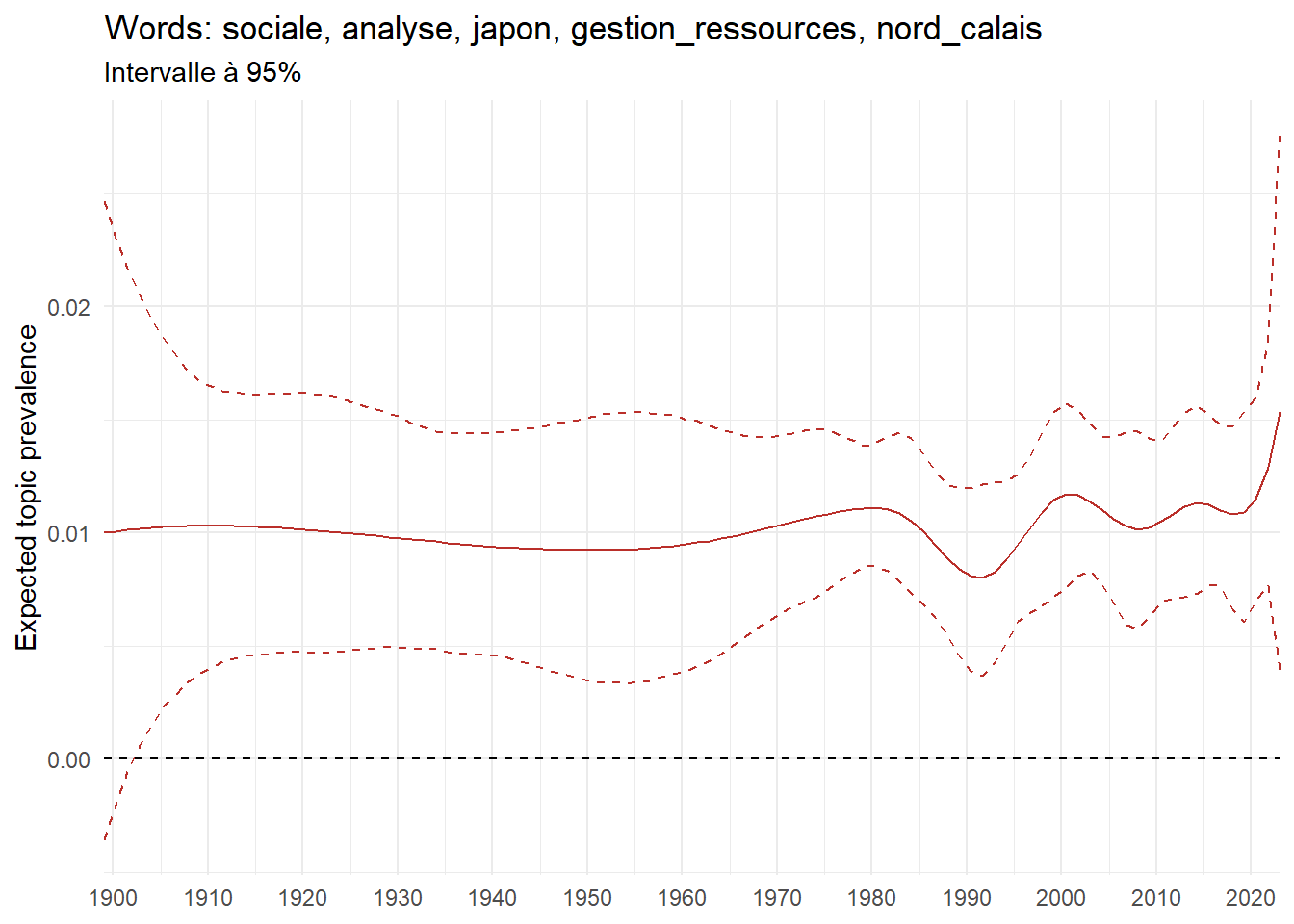
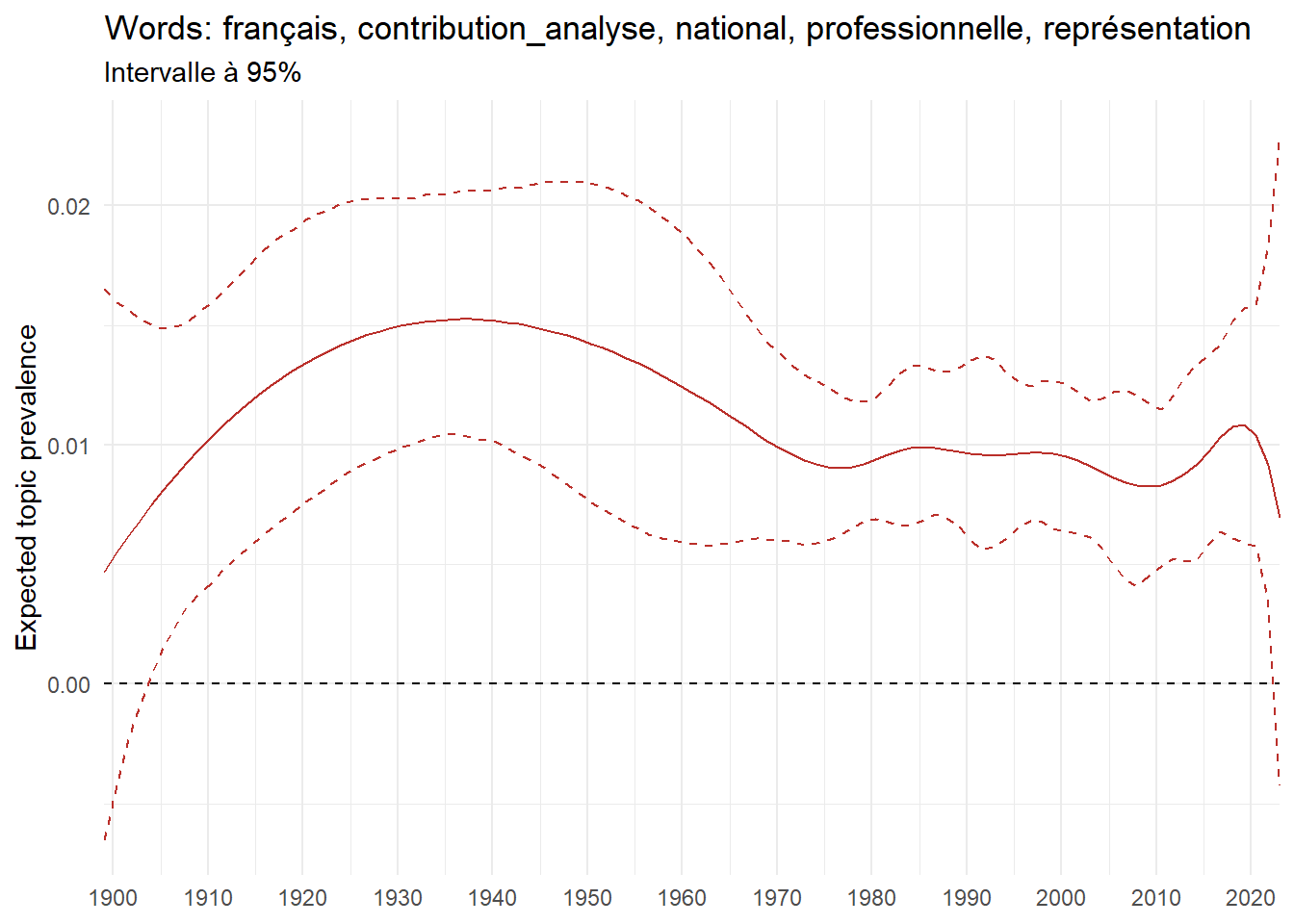
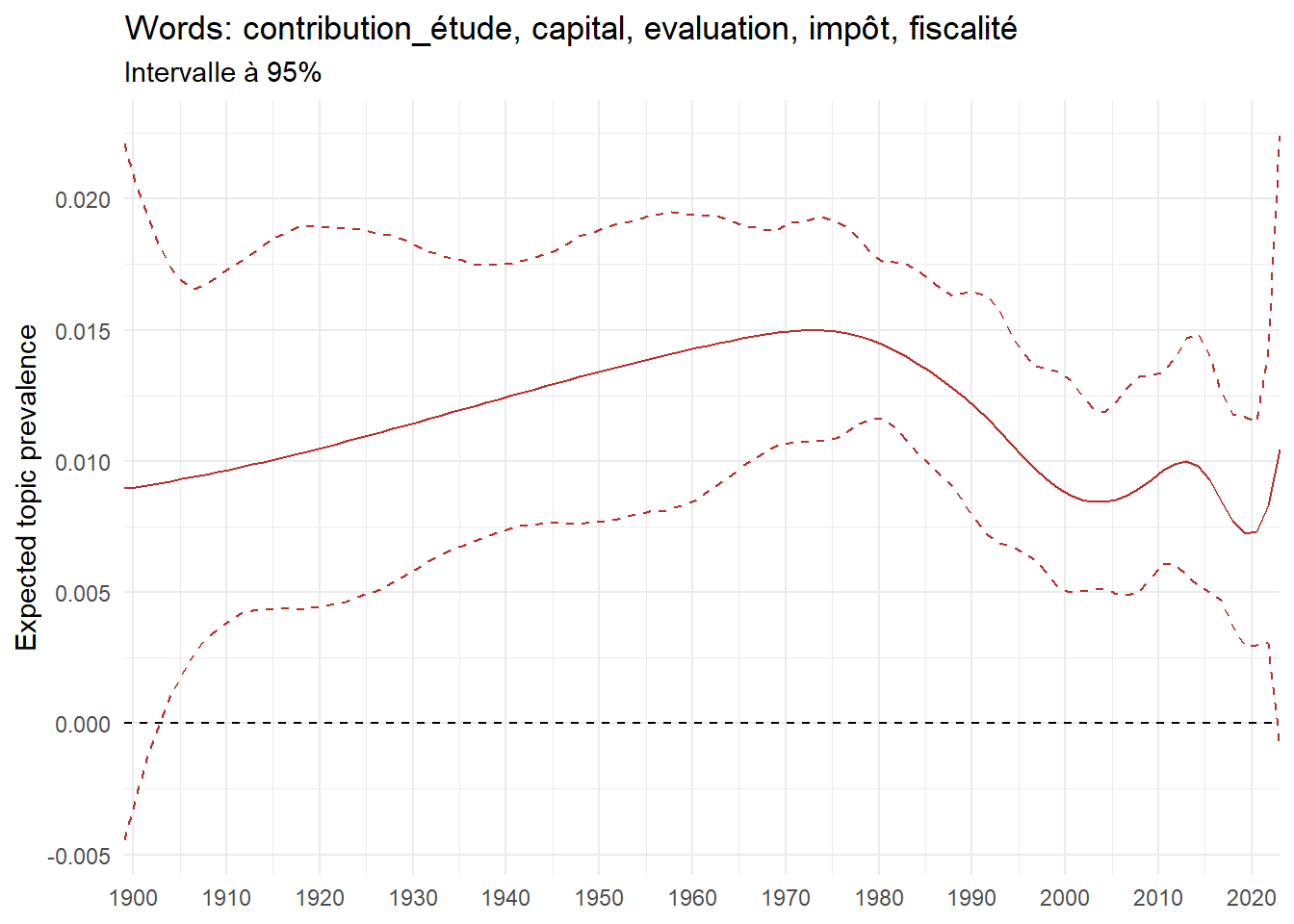
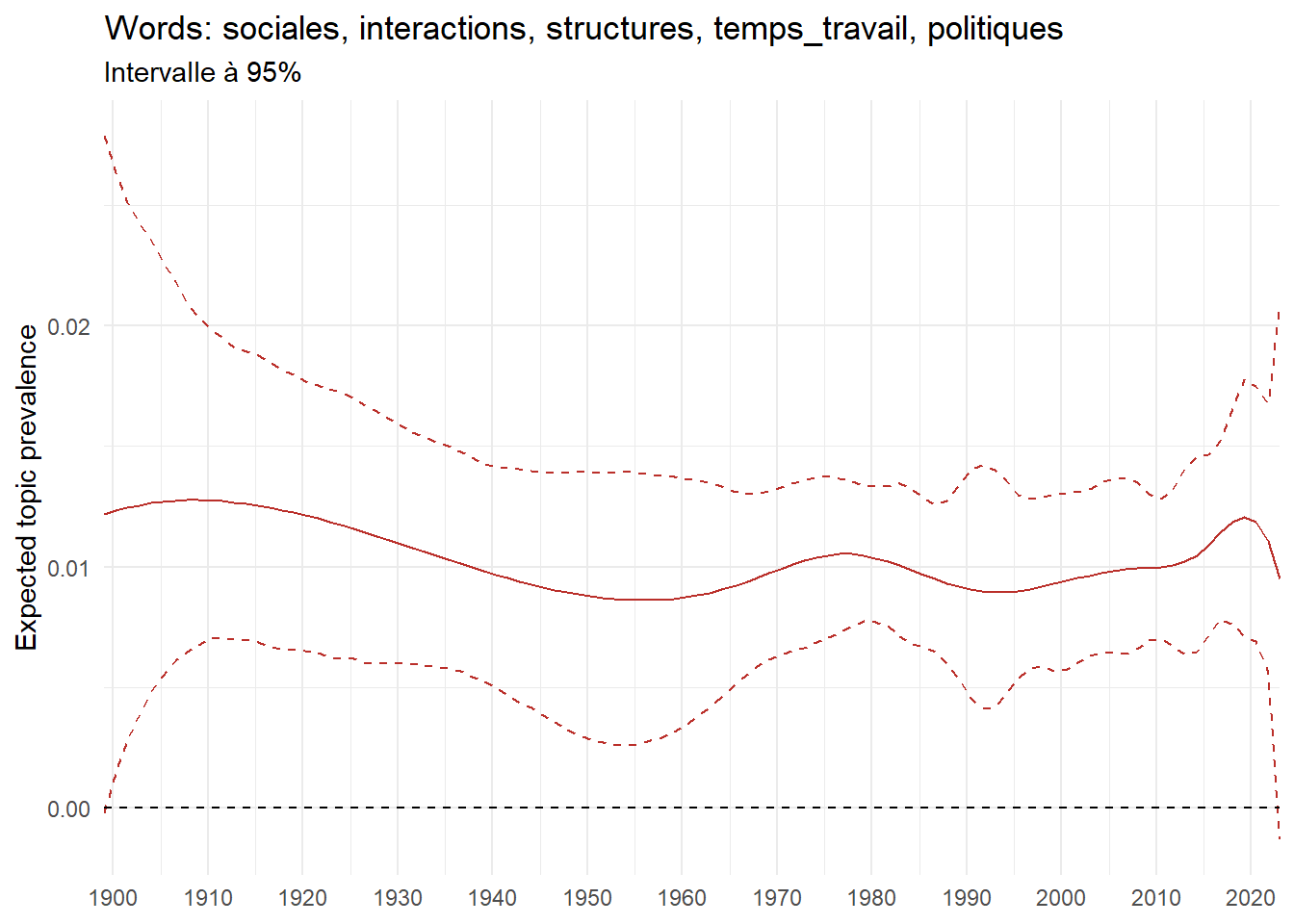
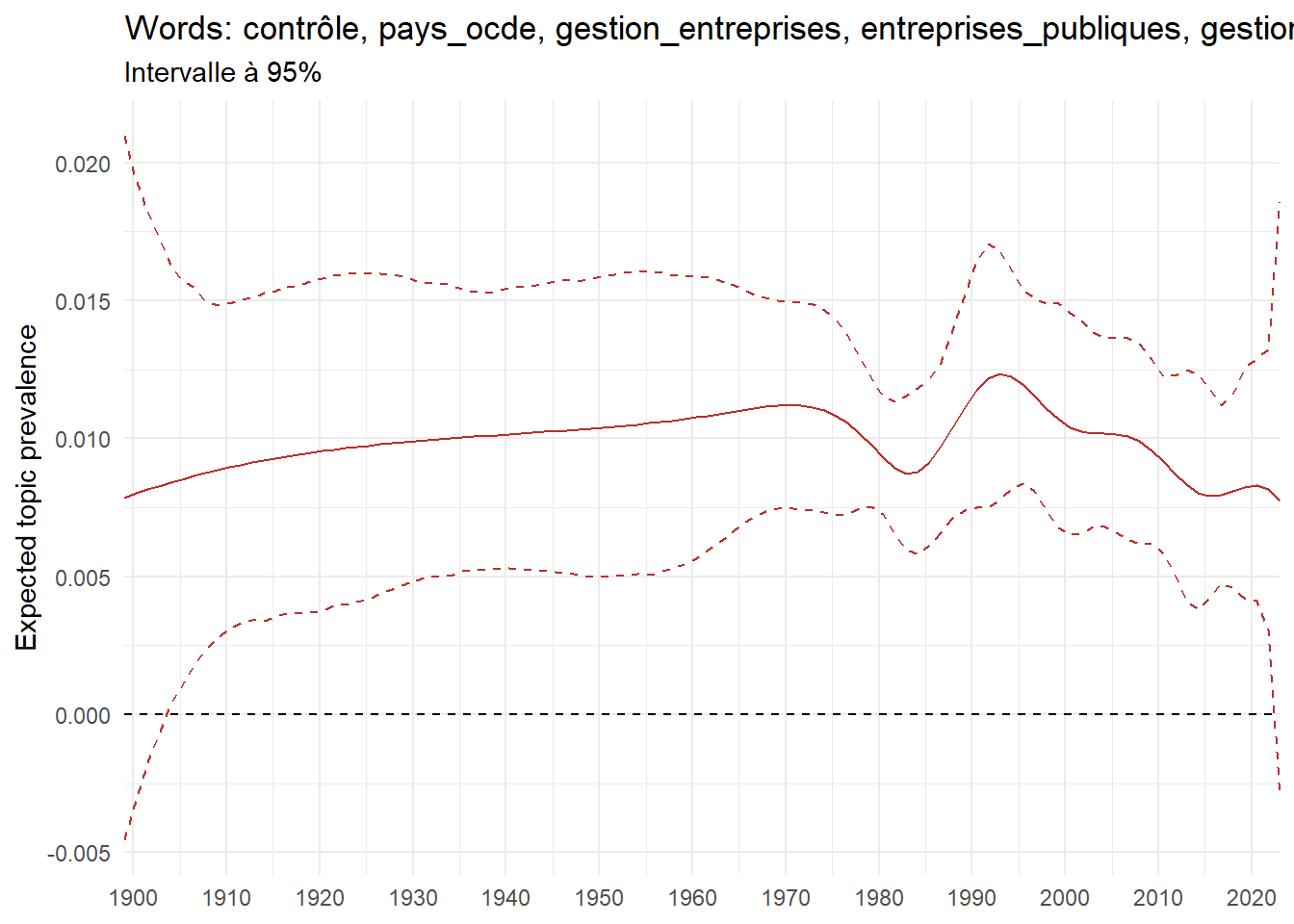
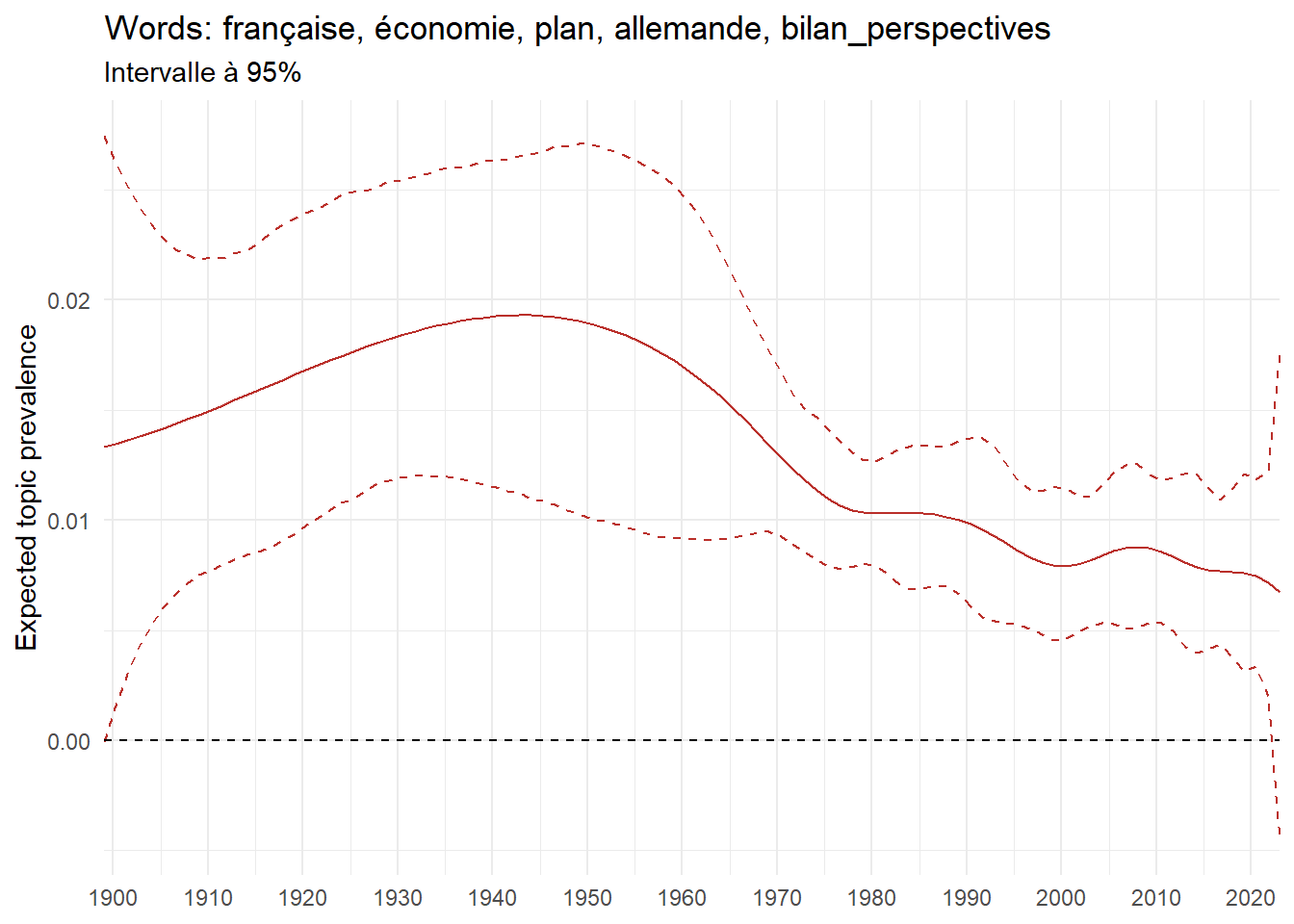
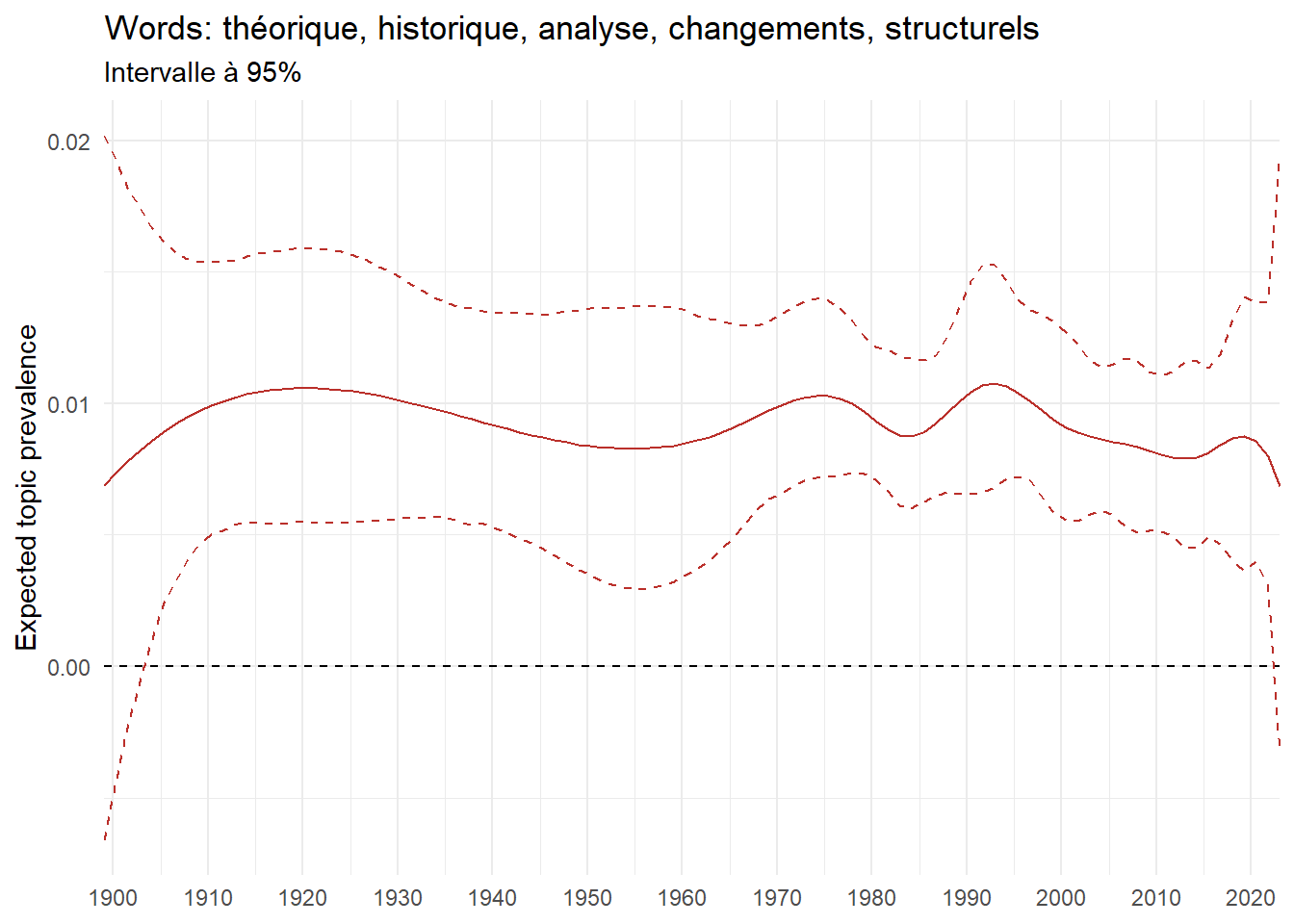
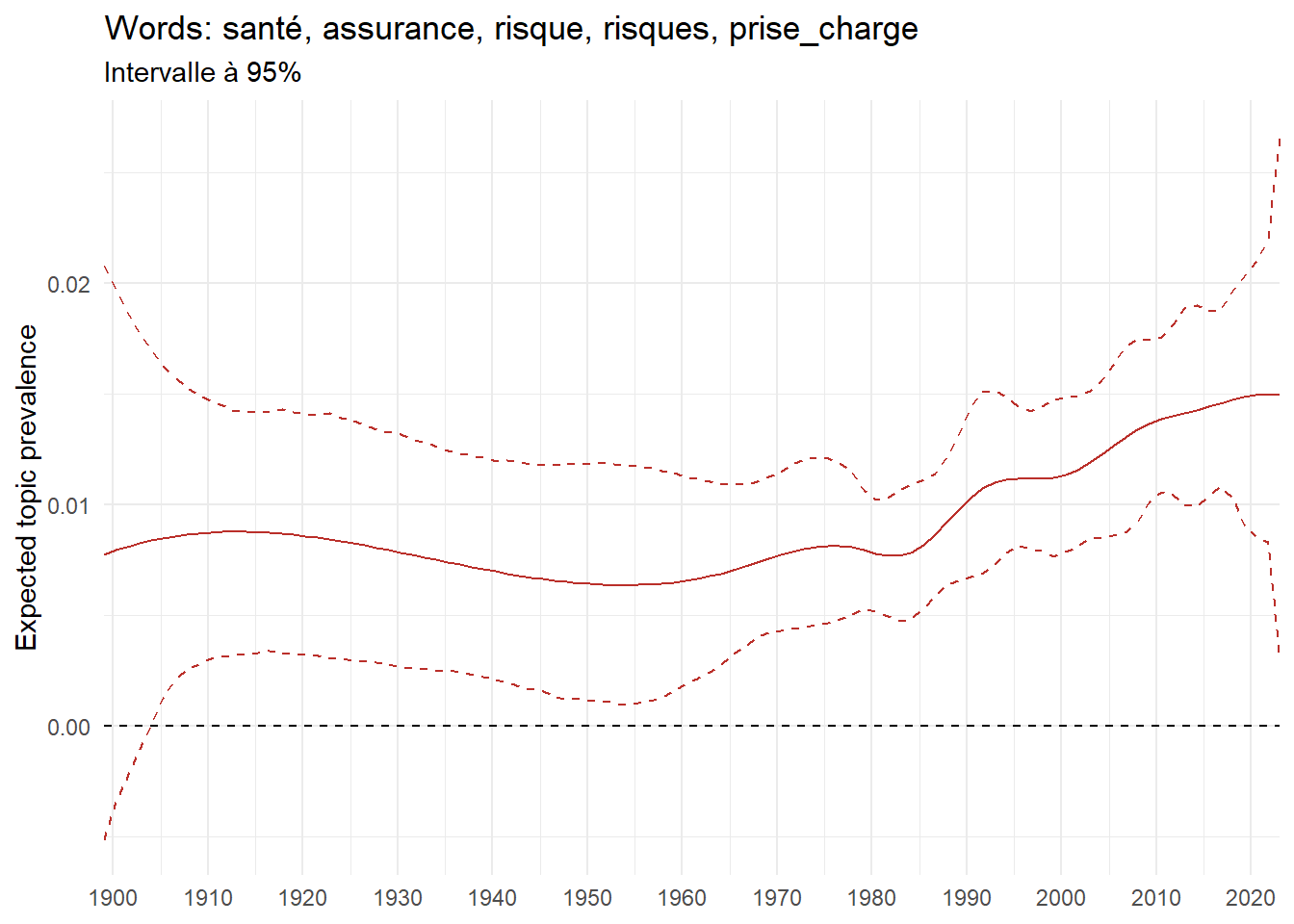
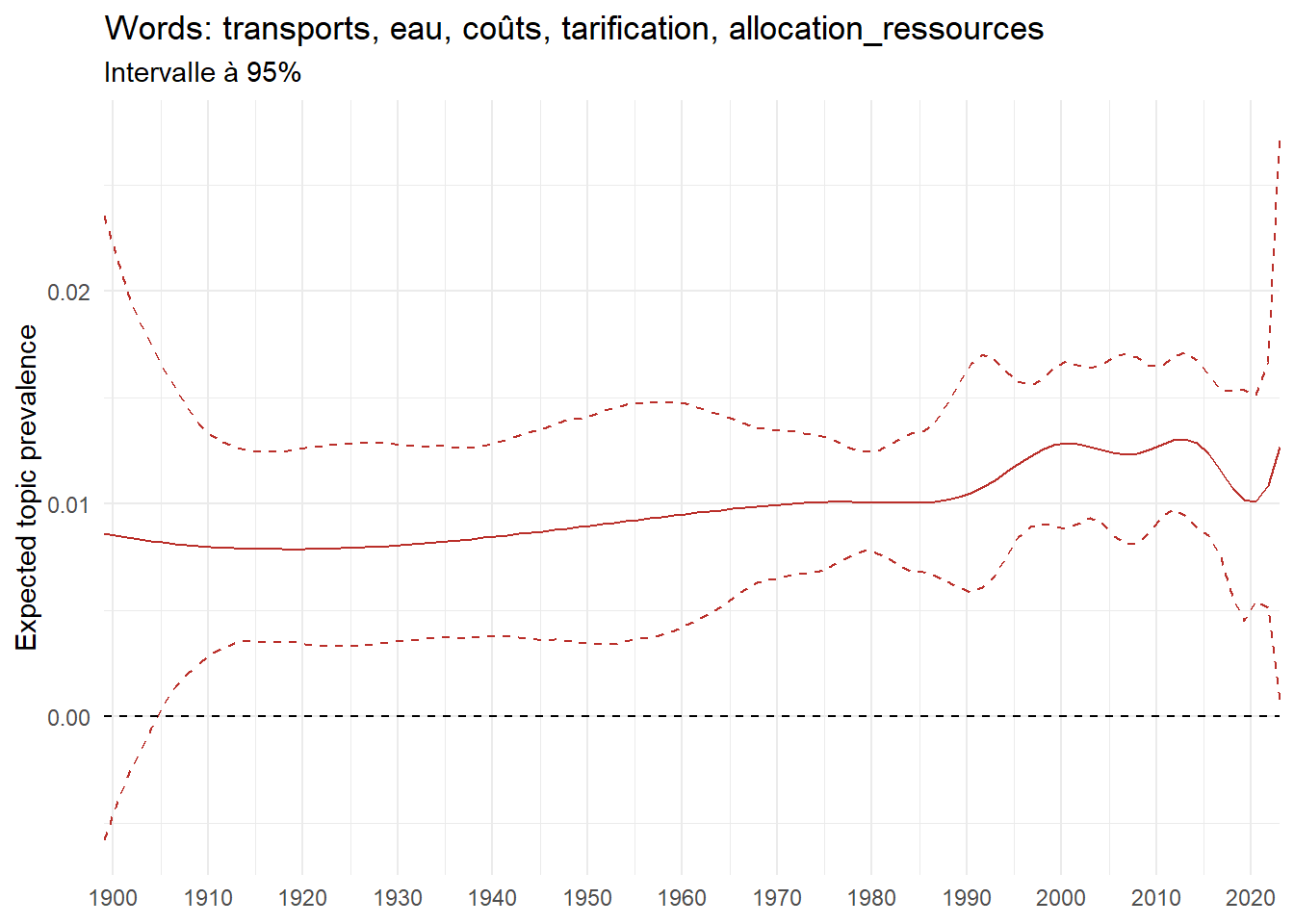
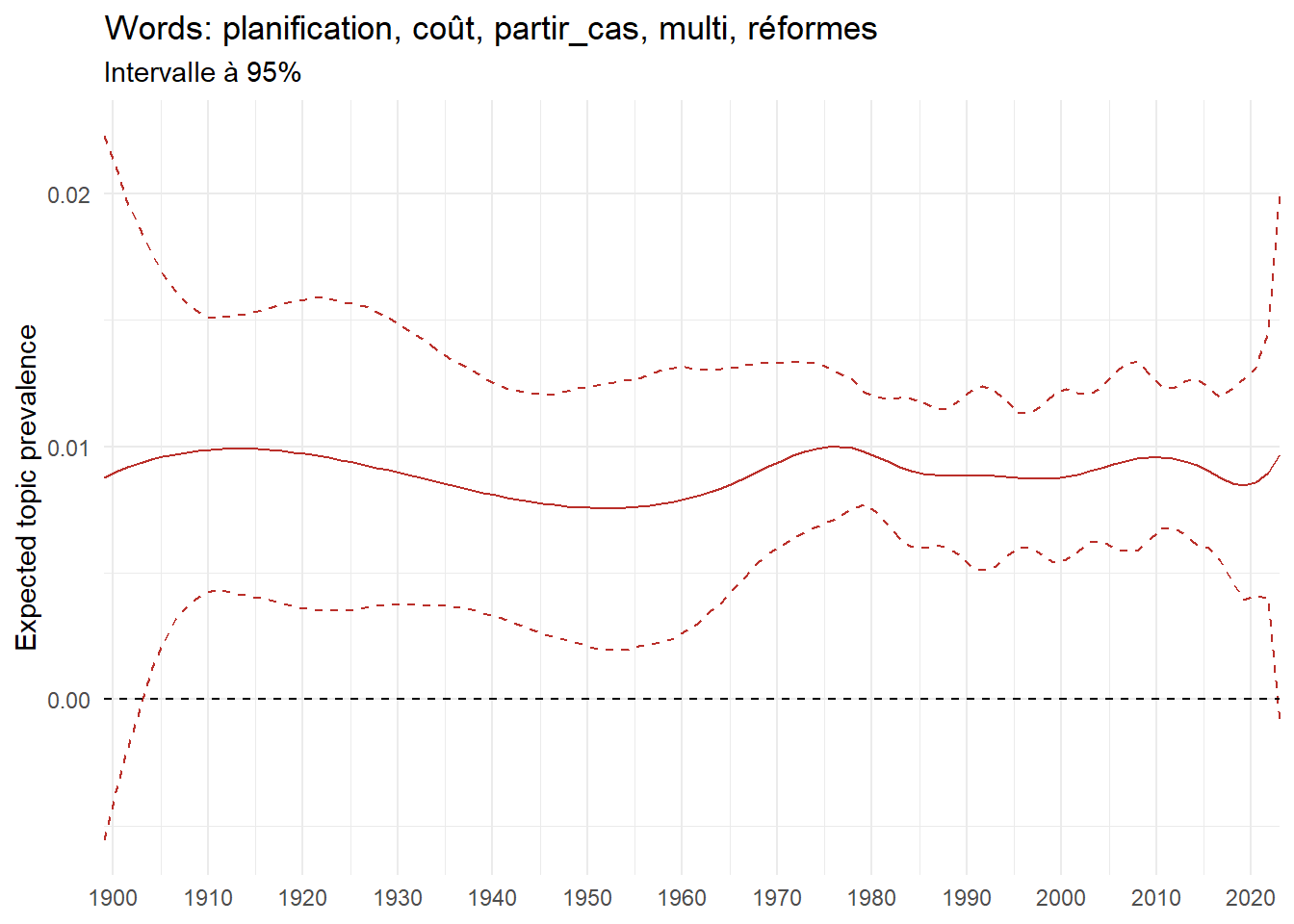
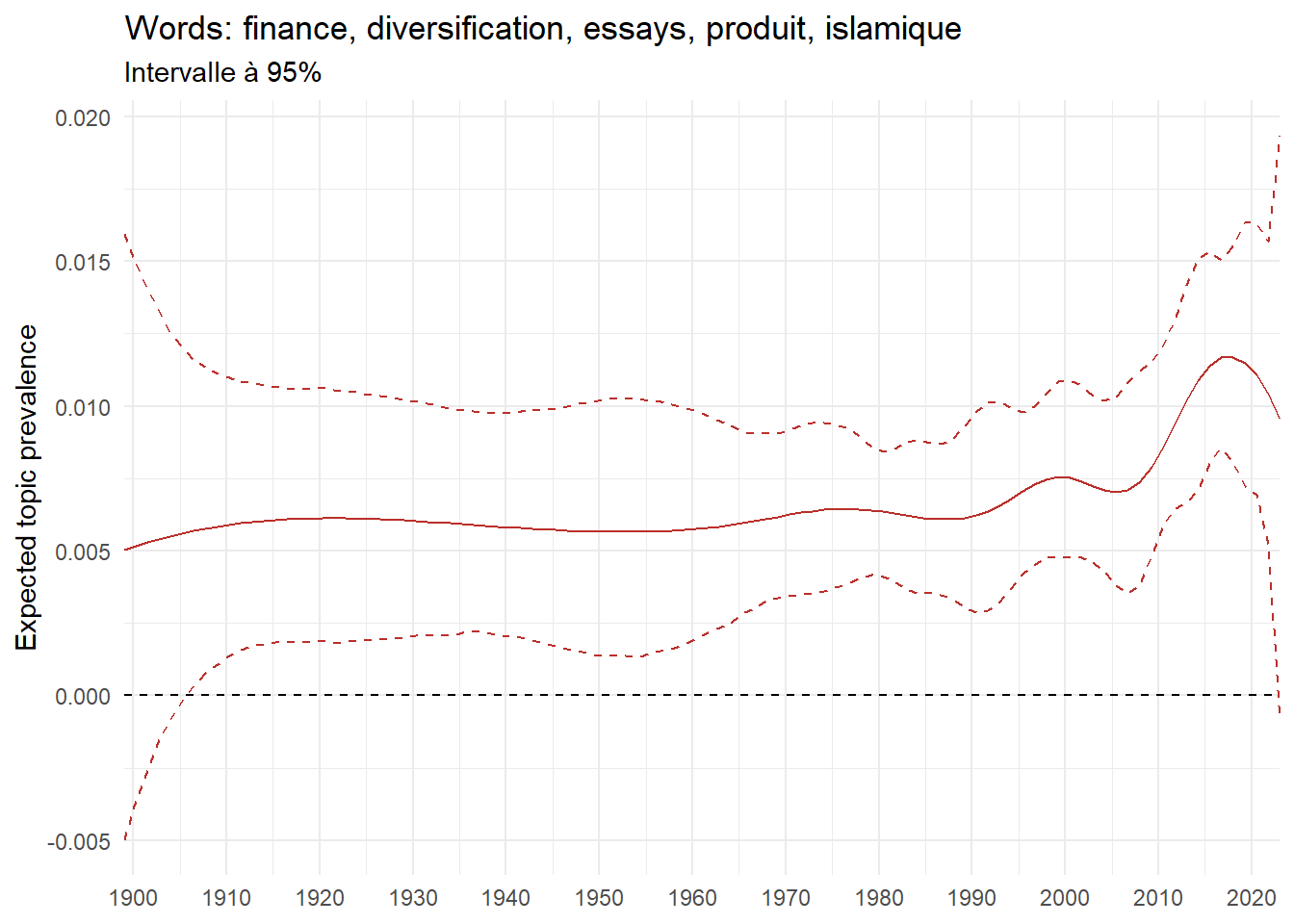
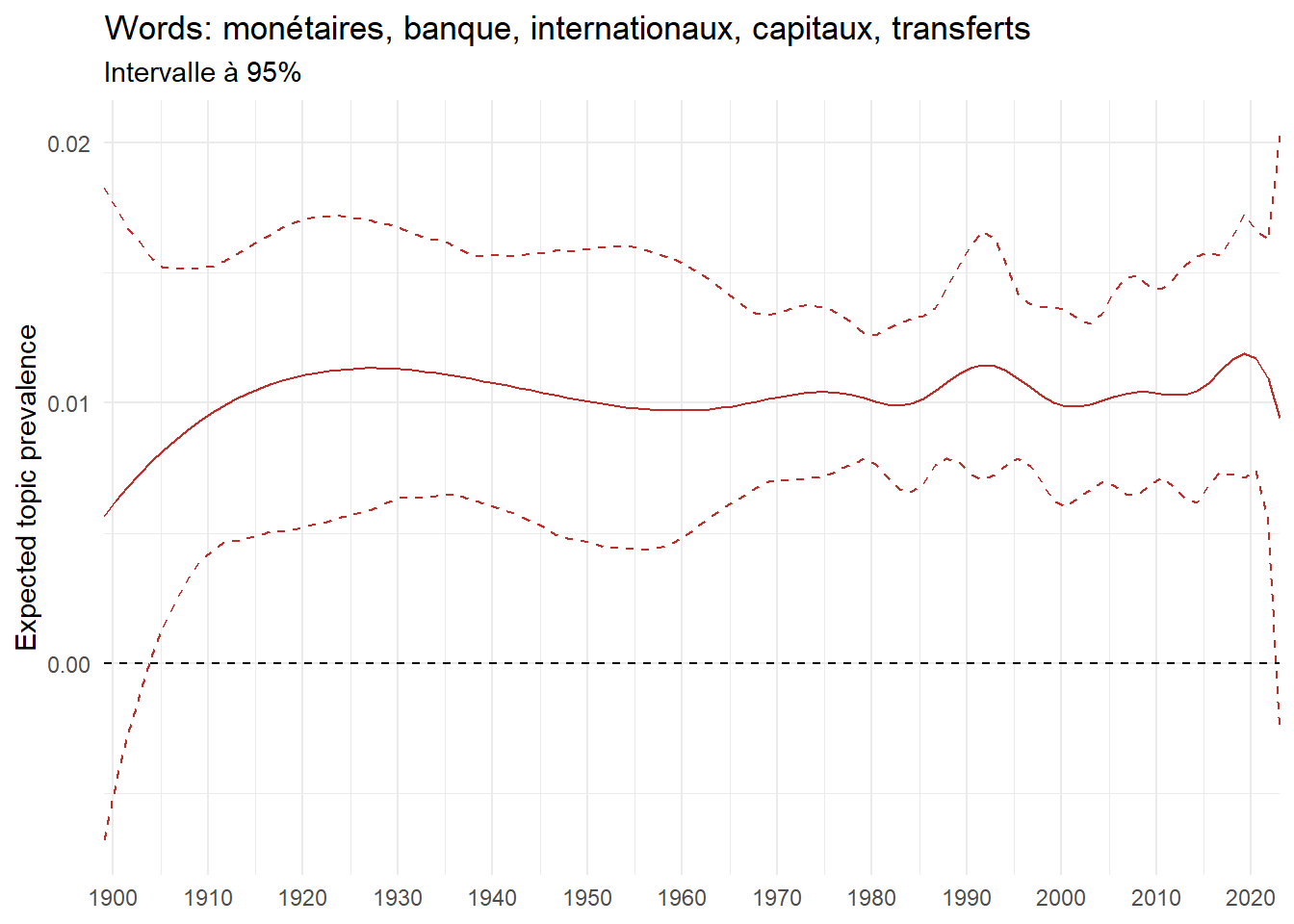
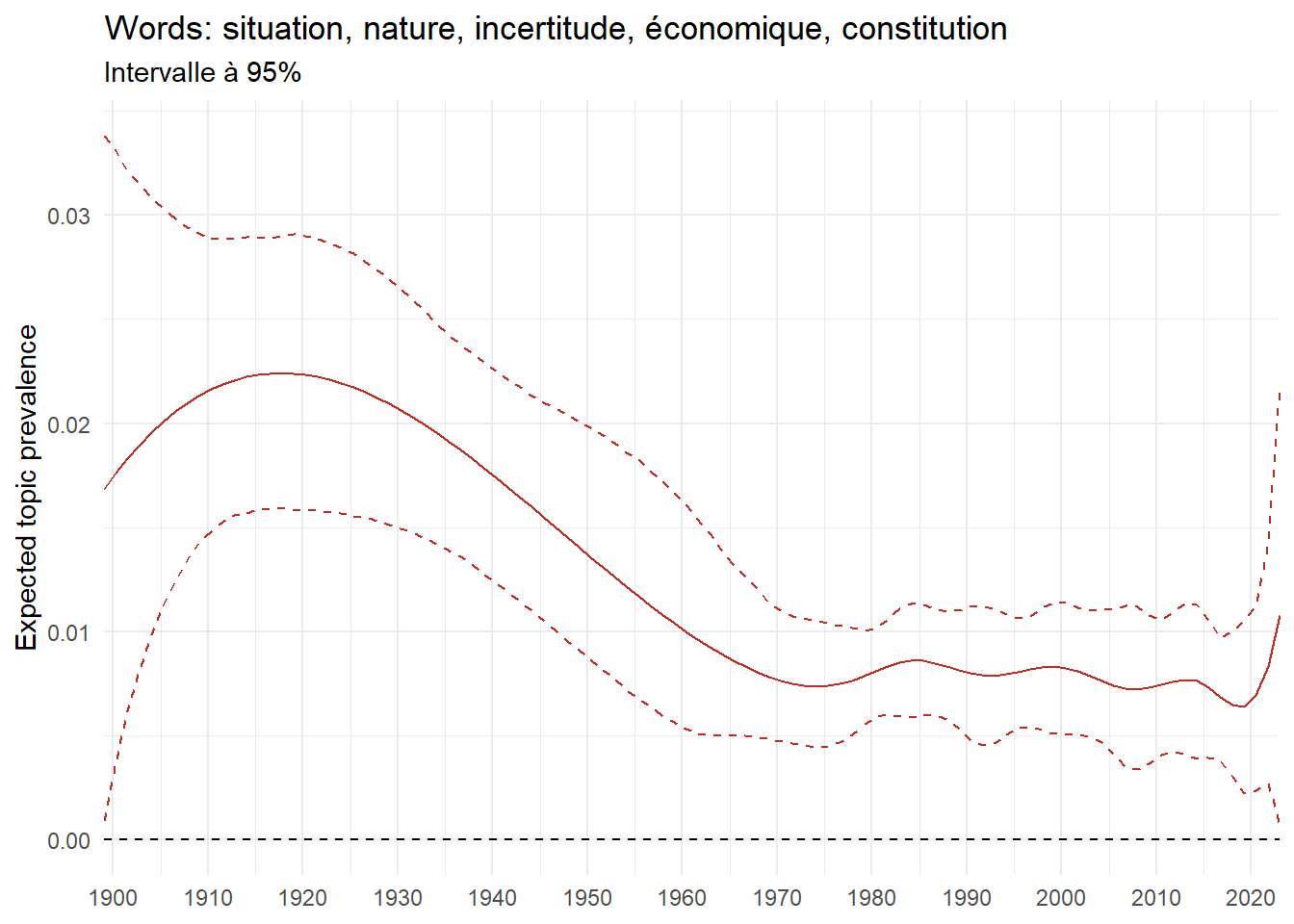
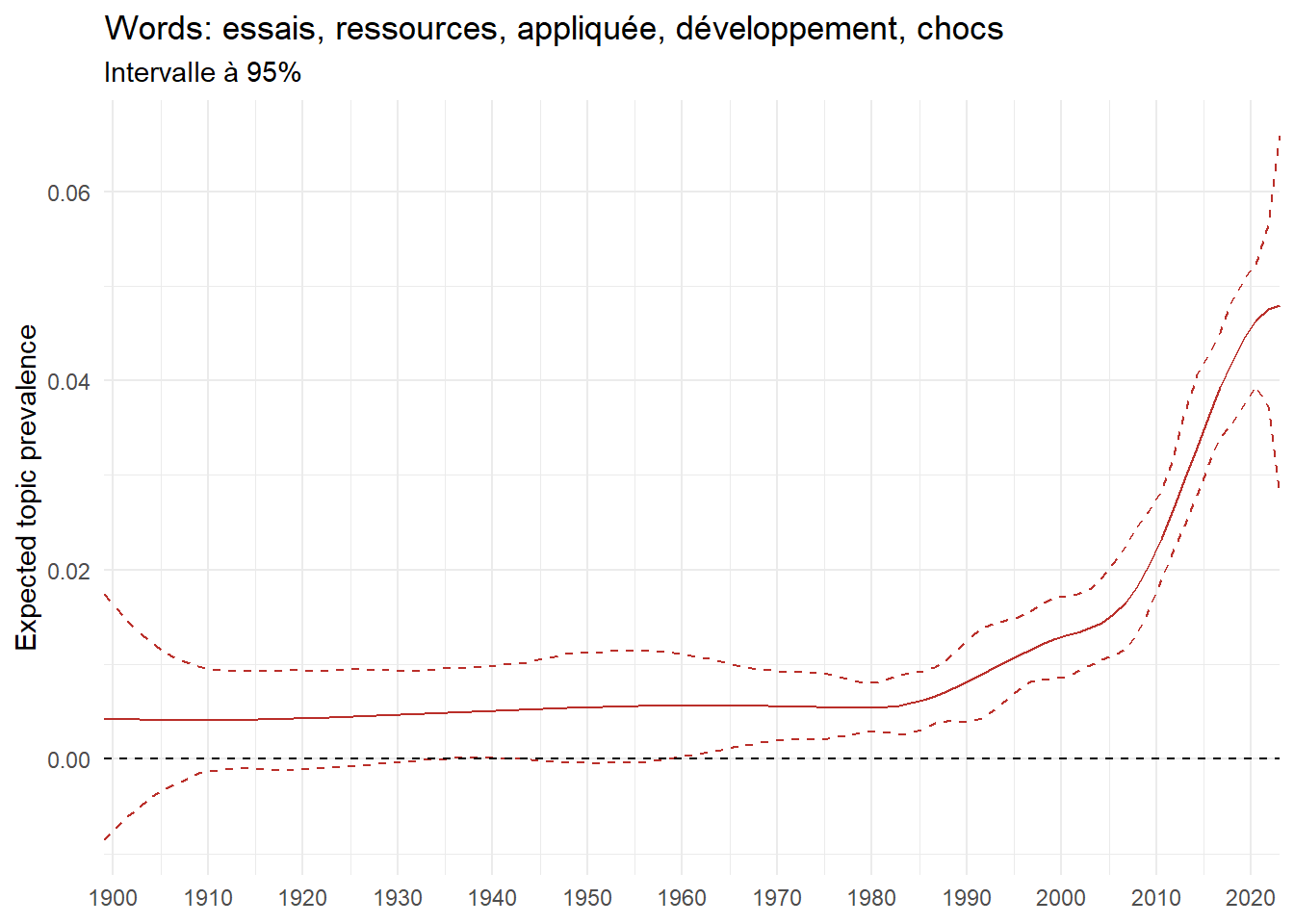
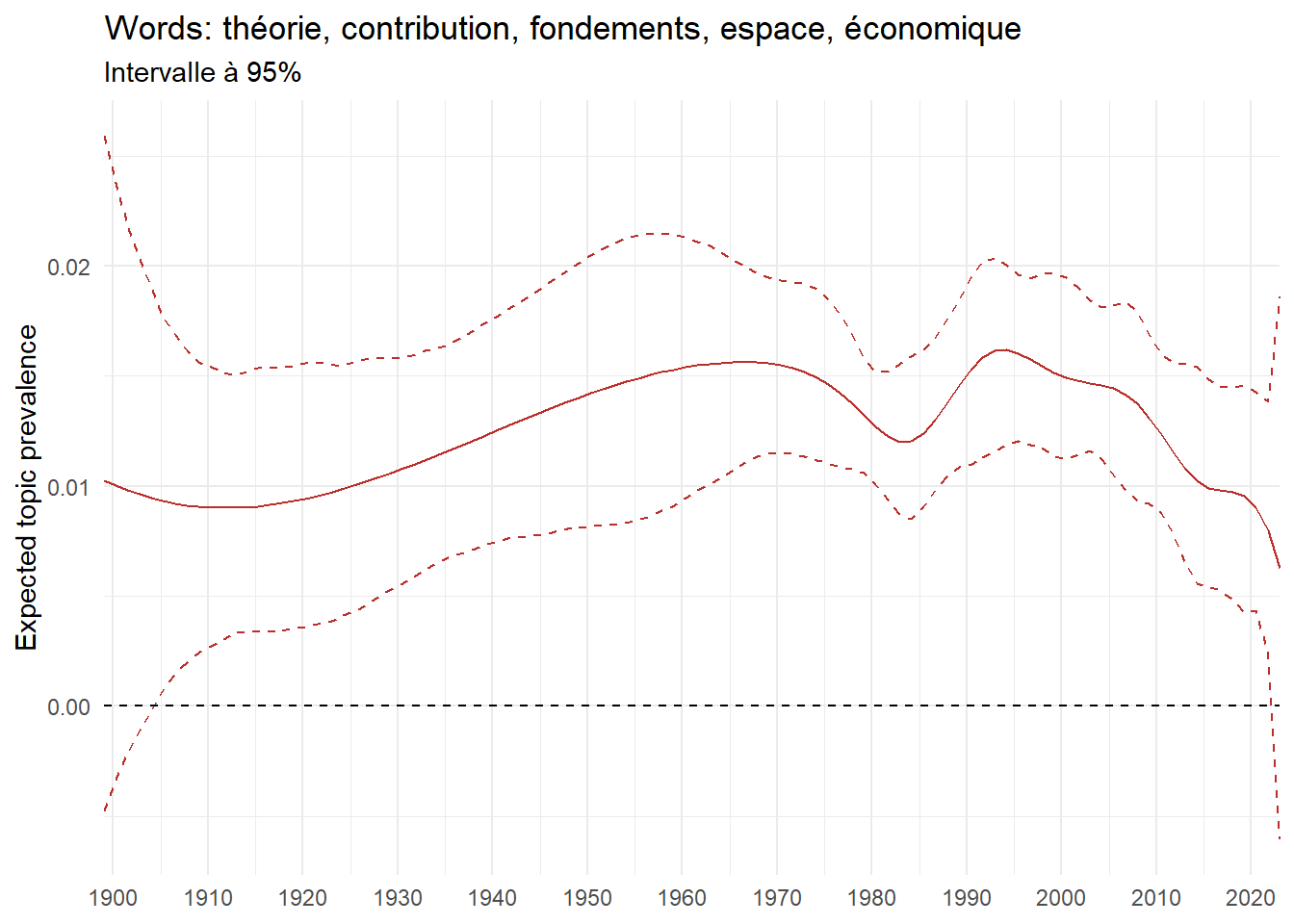
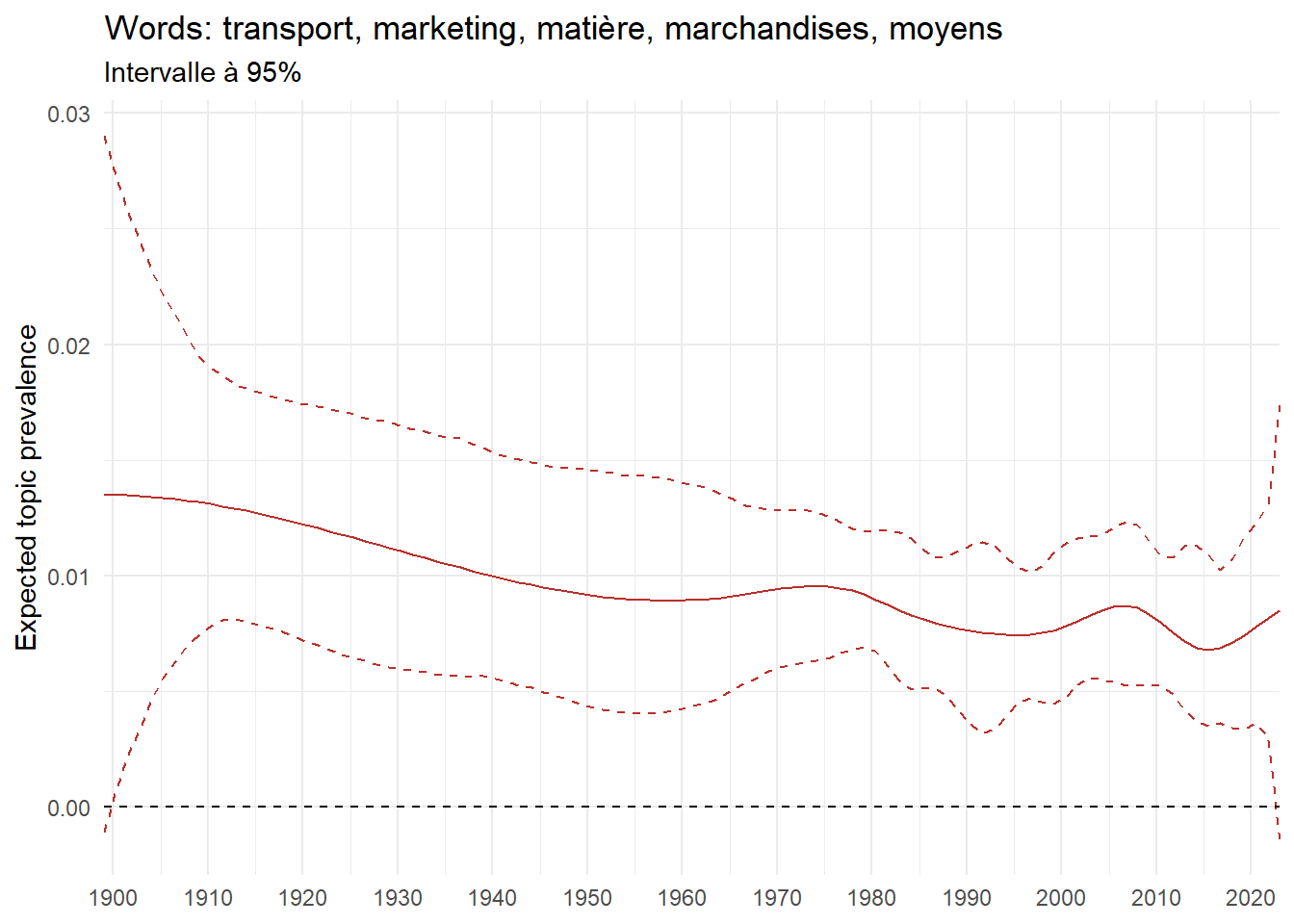
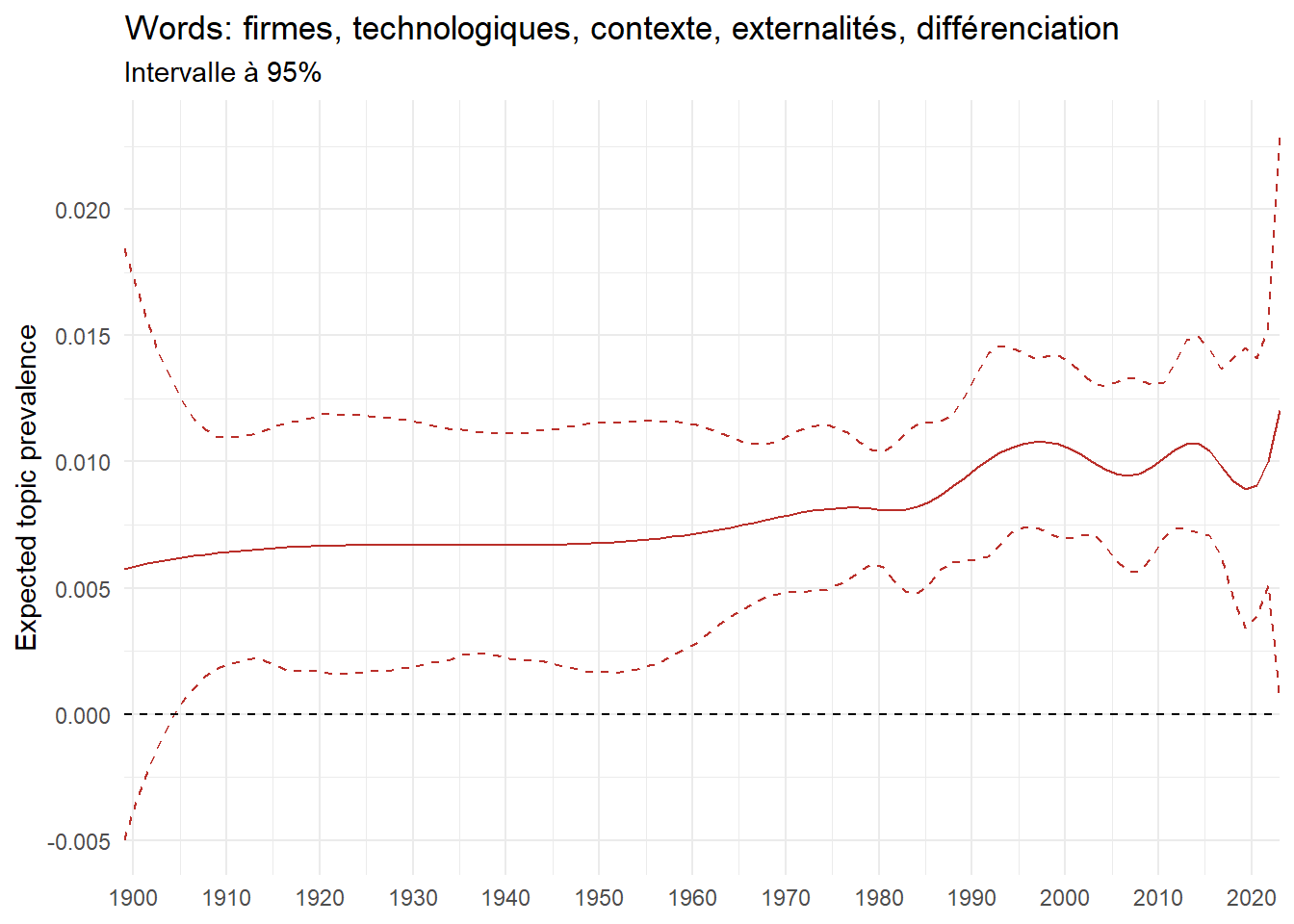
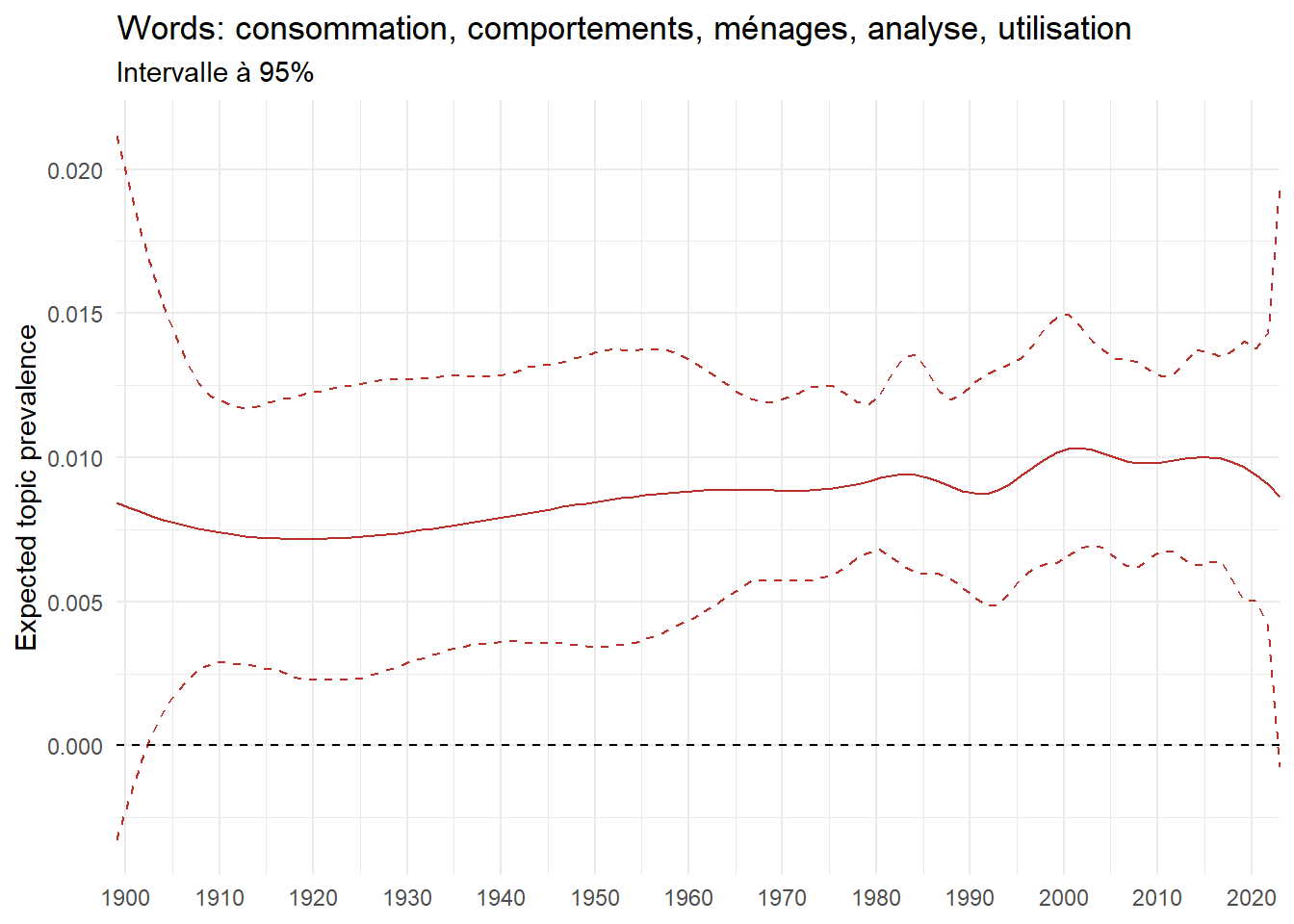
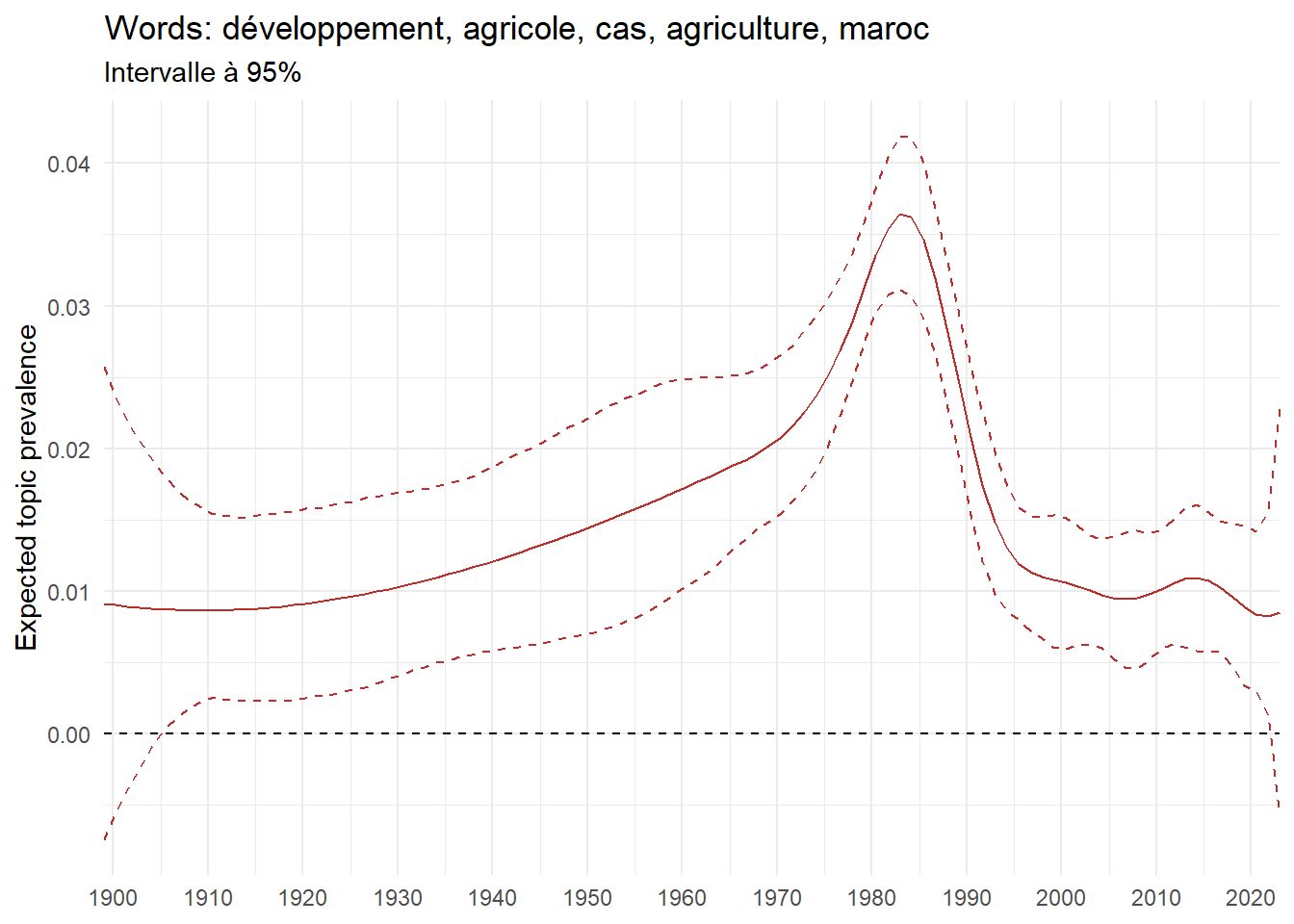
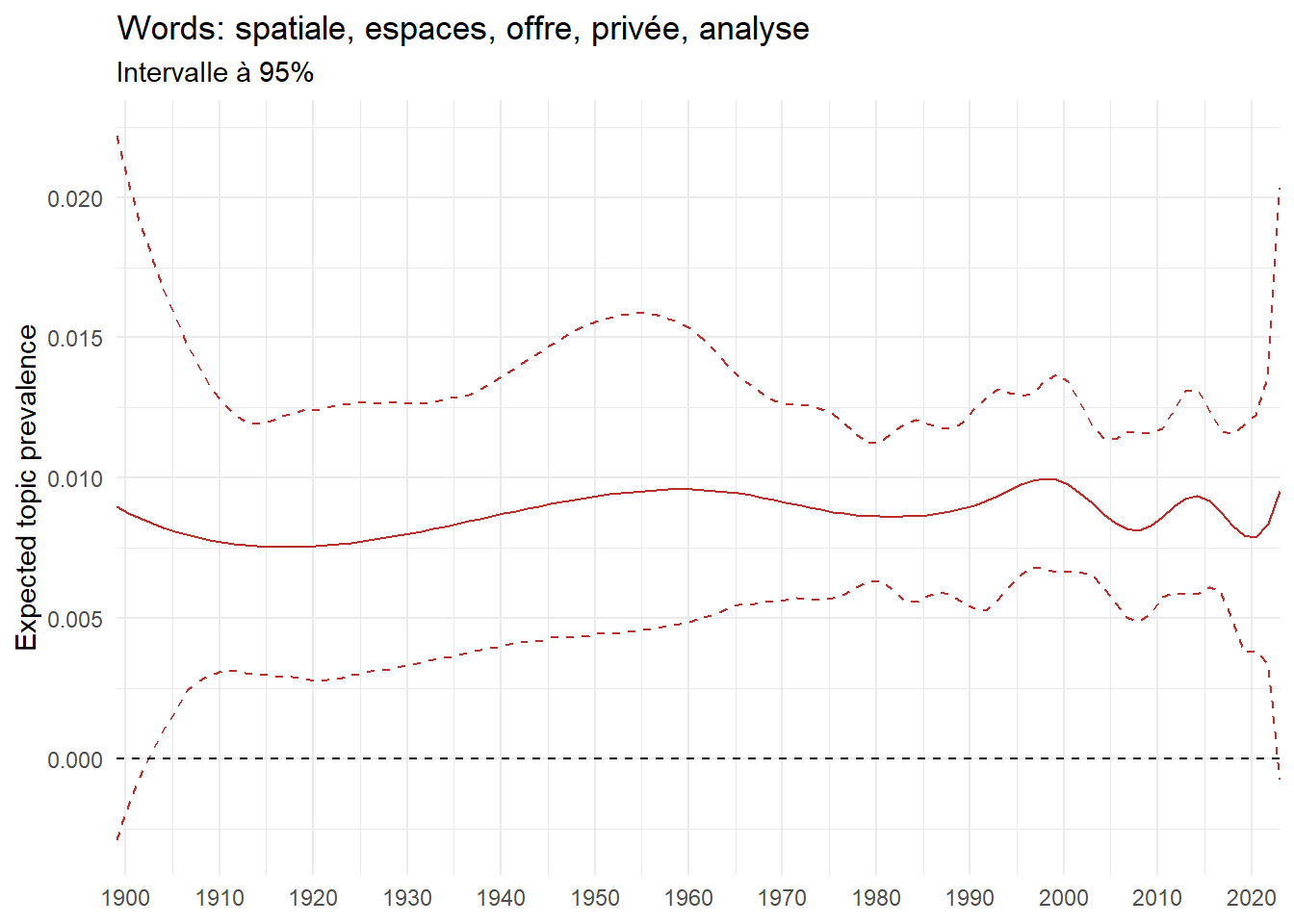
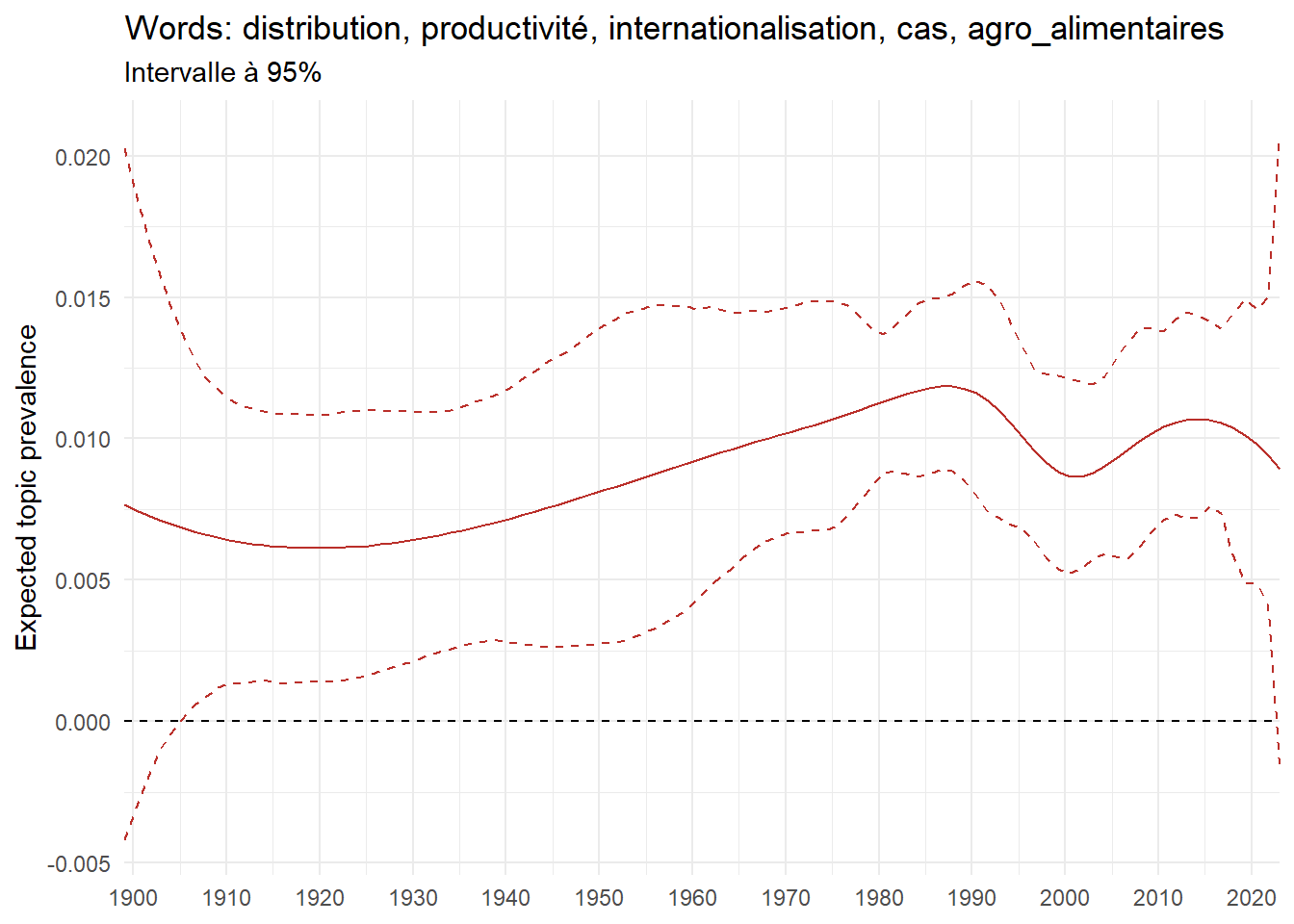
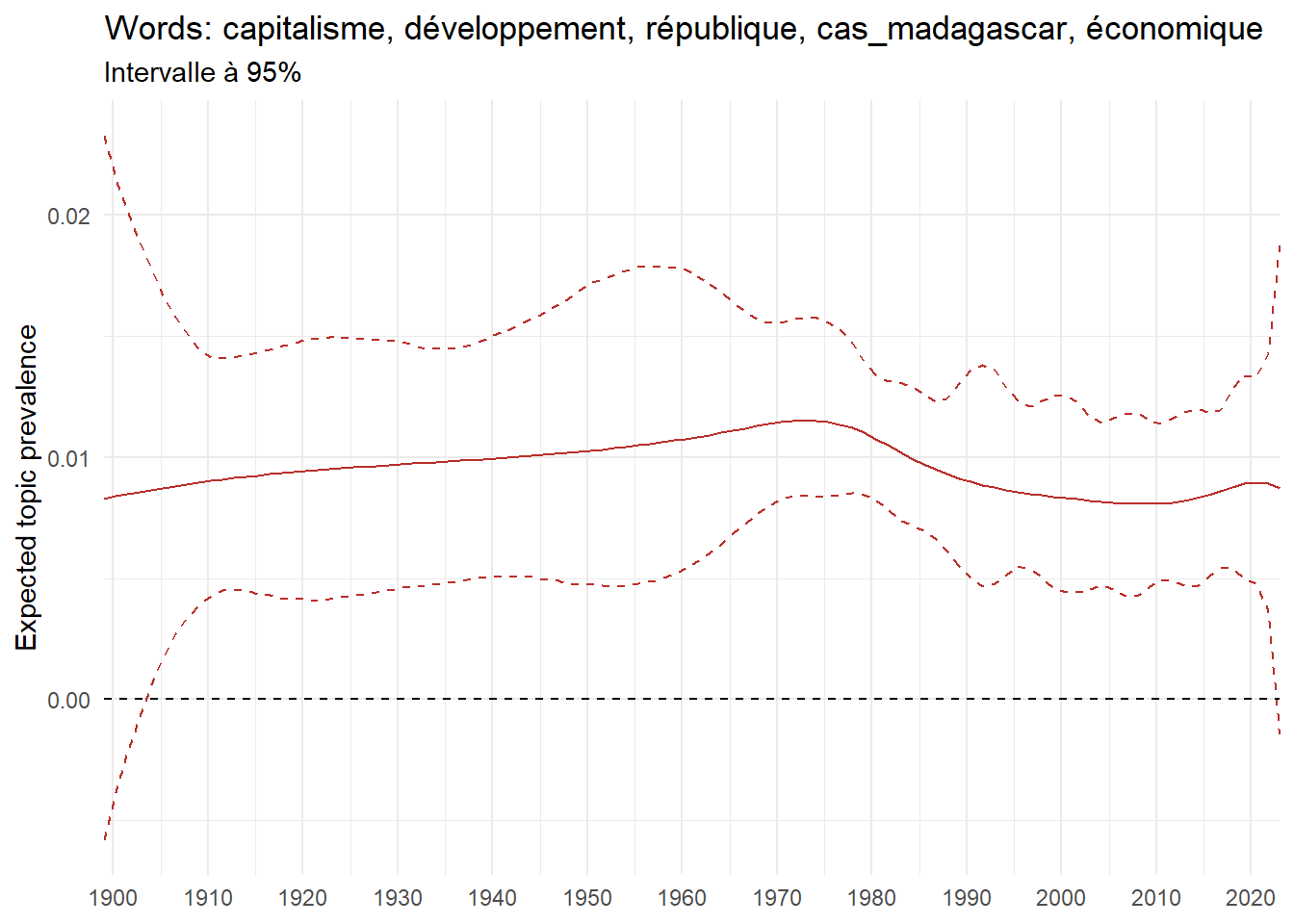
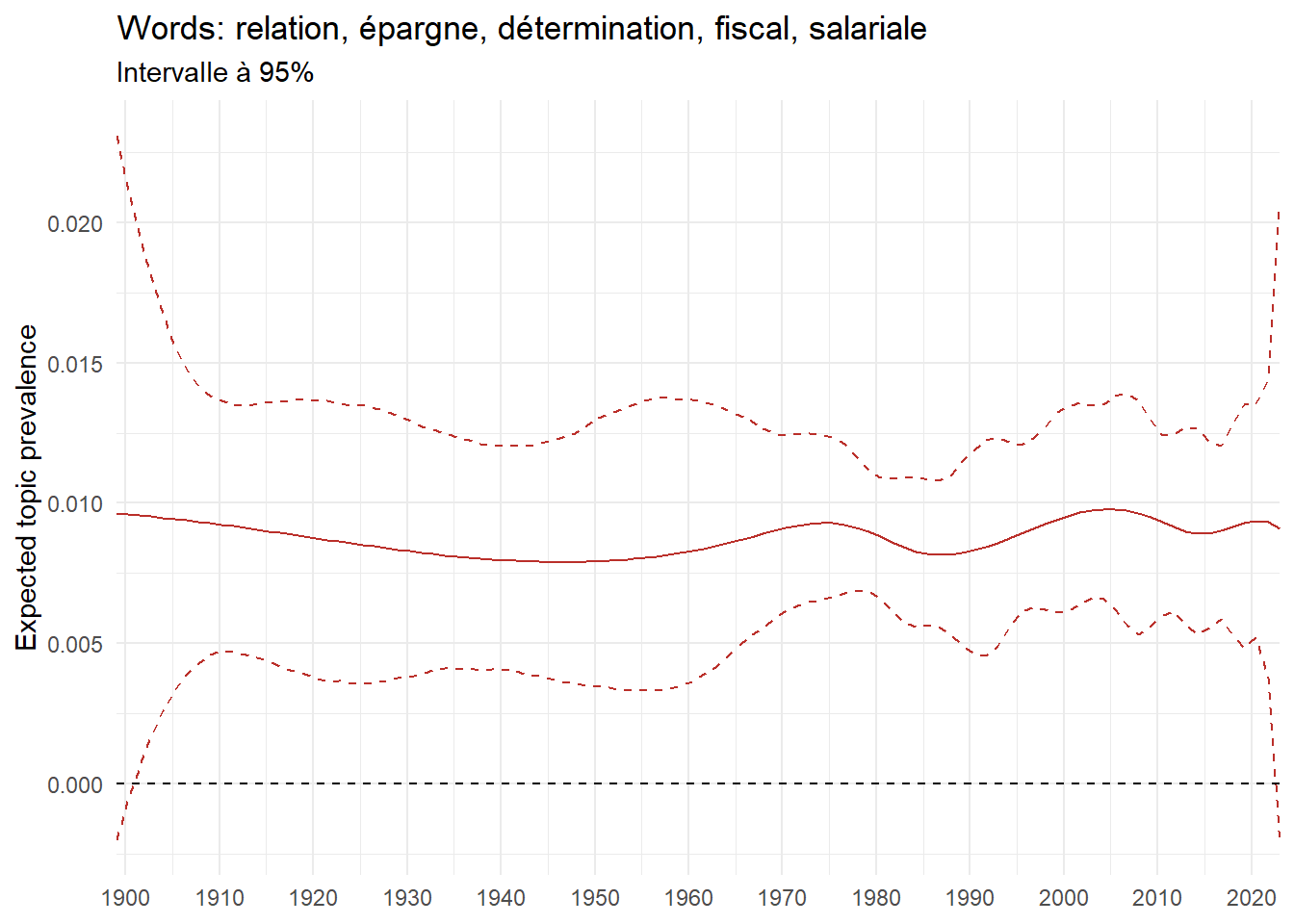
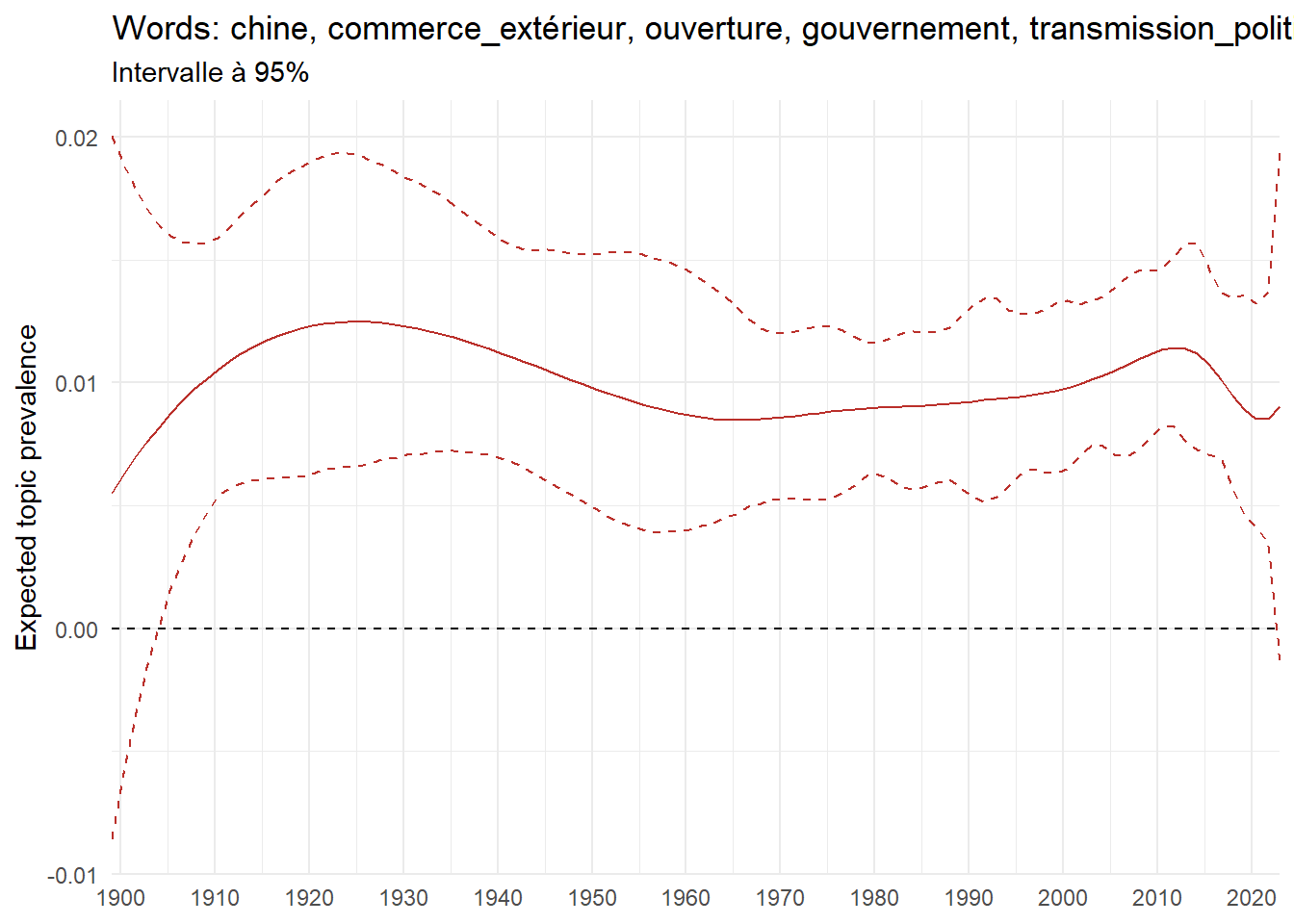
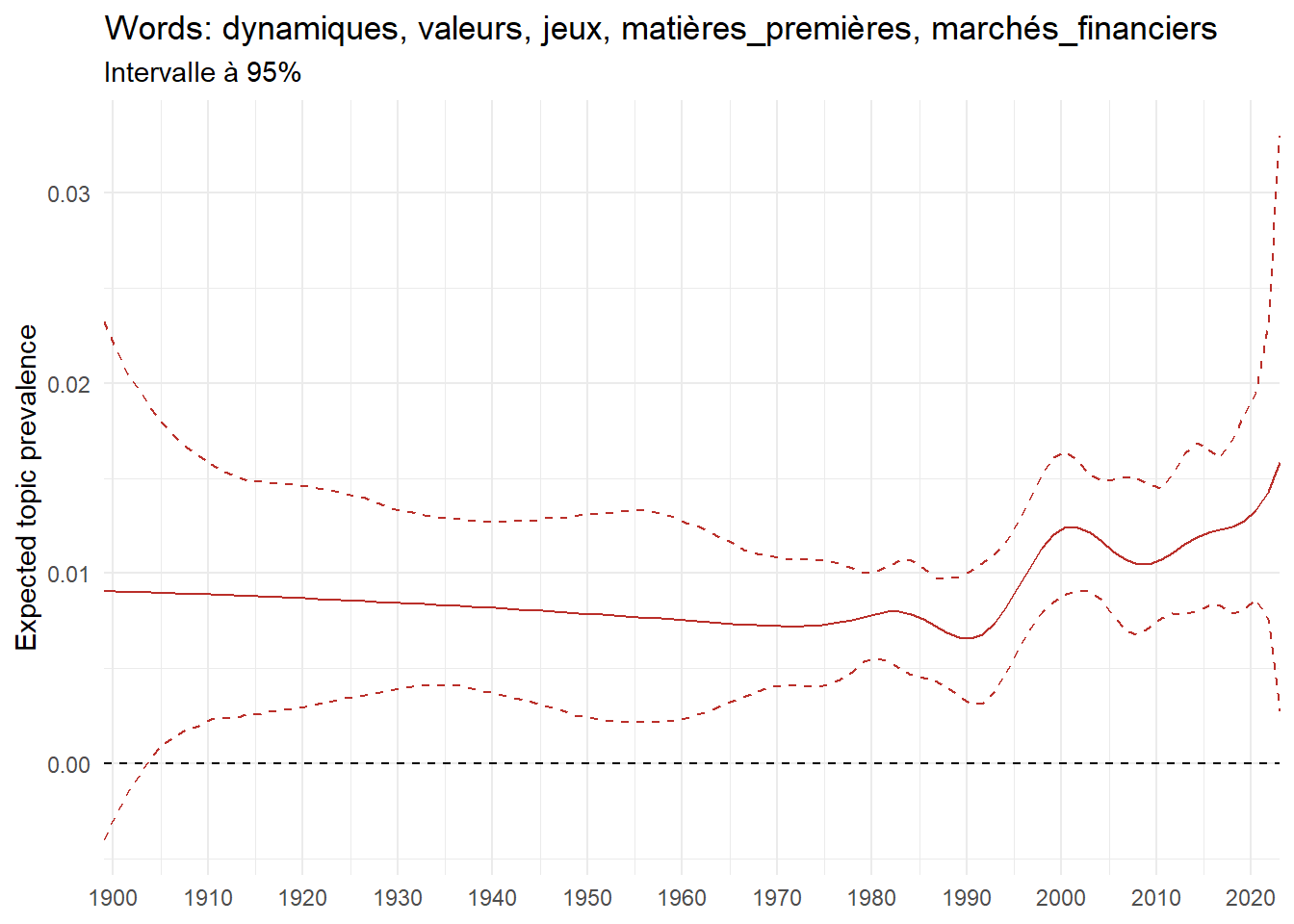
We can now examine the evolution of topics in French theses since 1900. Figure Figure 6 illustrates the topics with the greatest increases and decreases in prevalence over this period, measured as the difference between 1900 and 2023. Even this preliminary topic modeling provides valuable insights into the transformation of French economics.
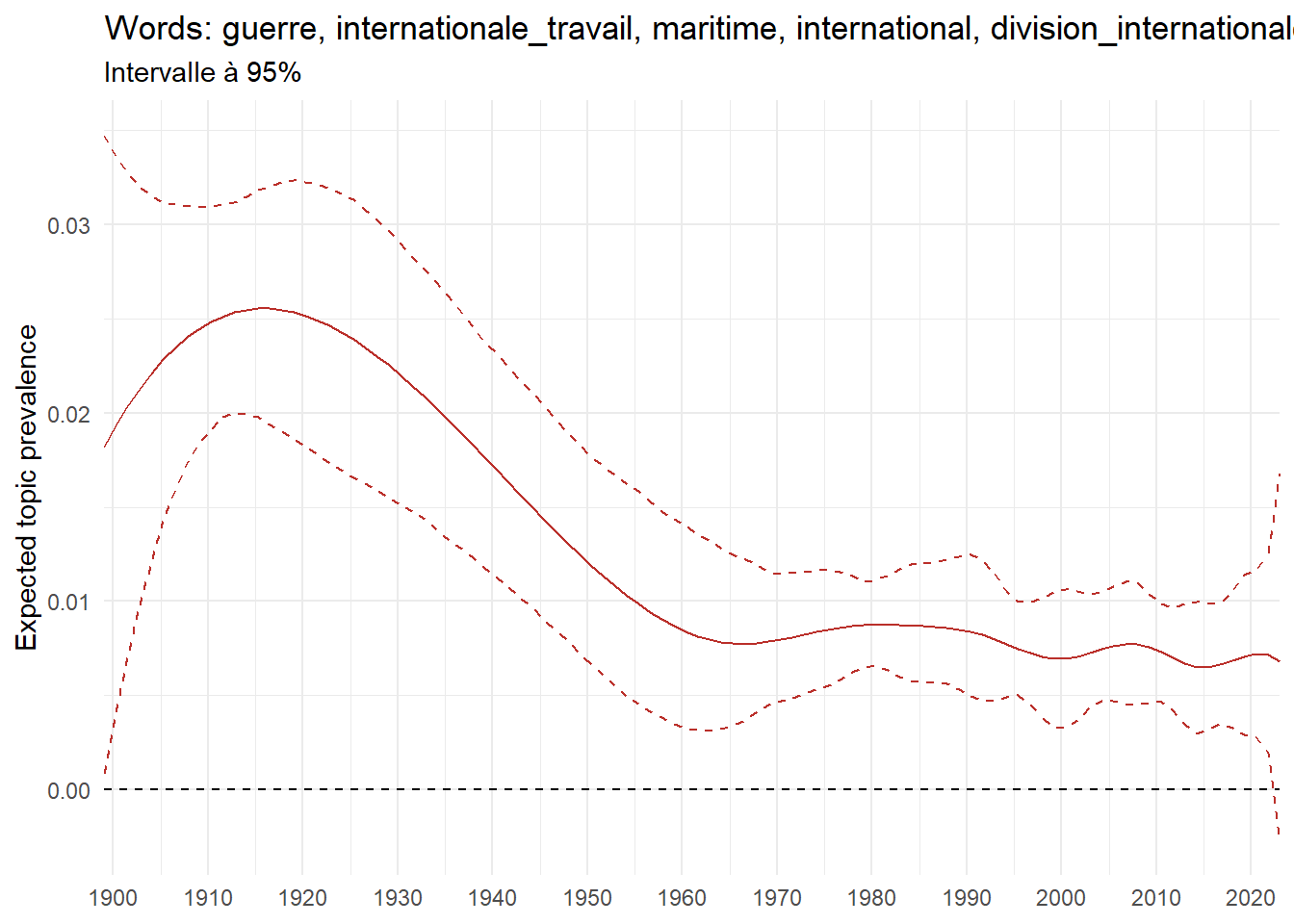
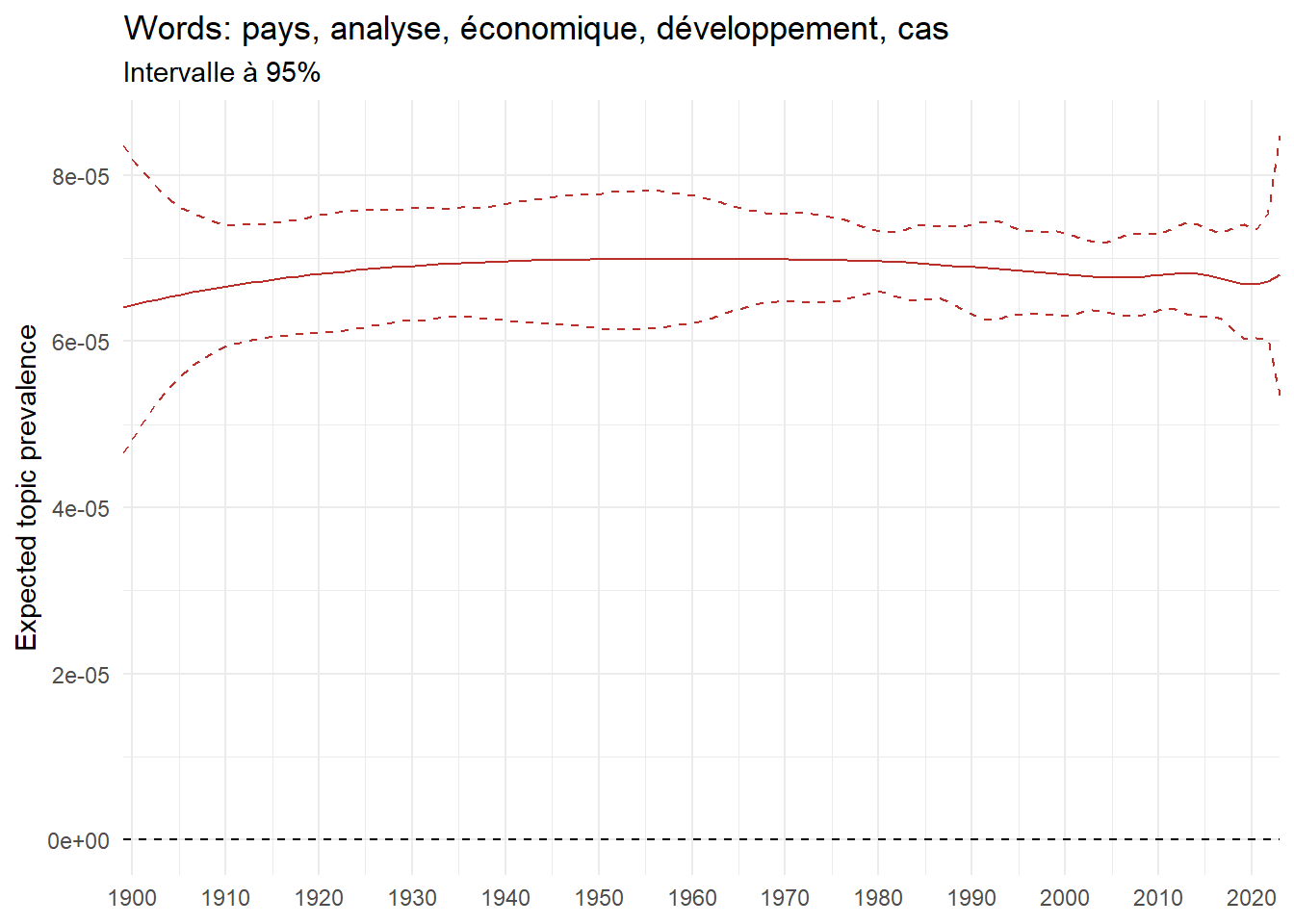
For instance, the declining topics are characterized by terminology associated with legal vocabulary, reflecting the significant role of law faculties in shaping French academic disciplines during the first half of the 20th century. Conversely, the increasing topics predominantly feature terms related to applied and contemporary research questions, such as inequality and the environment.
ee_year <-readRDS(here(website_data_path, "ee_year.rds"))# function to estimate variation of theta between 1900 and delta_theta <- ee_year %>%group_by(topic) %>%# Group by topicreframe(delta = estimate[n()] - estimate[1]) # Difference between the last and first estimate)max_delta <- delta_theta %>%slice_max(delta, n =5)gg_max <- ee_year %>%filter(topic %in% max_delta$topic) %>%ggplot(aes(x = covariate.value,color =paste0(topic, " : ", topic_label_prob), )) +geom_line(aes(y = estimate)) +geom_hline(yintercept =0, linetype ="dashed", color ="black") +labs(x =NULL,y ="Expected topic prevalence",color ="") +theme_minimal() +theme(strip.text =element_text(size =3),legend.position ="bottom", # Positionne la légende en bas du graphiquelegend.text =element_text(size =9), # Ajuste la taille du texte dans la légendelegend.title =element_text(size =9) # Ajuste la taille du titre de la légende ) +guides(color =guide_legend(nrow =5)) +# Place la légende sur une seule lignescale_x_continuous(expand =c(0,0), breaks =seq(1900, 2020, 10)) +scale_color_wsj()min_delta <- delta_theta %>%slice_min(delta, n =5)gg_min <- ee_year %>%filter(topic %in% min_delta$topic) %>%ggplot(aes(x = covariate.value,color =paste0(topic, " : ", topic_label_prob), )) +geom_line(aes(y = estimate)) +geom_hline(yintercept =0, linetype ="dashed", color ="black") +labs(x =NULL,y =NULL,color ="") +theme_minimal() +theme(strip.text =element_text(size =3),legend.position ="bottom", # Positionne la légende en bas du graphiquelegend.text =element_text(size =9), # Ajuste la taille du texte dans la légendelegend.title =element_text(size =9) # Ajuste la taille du titre de la légende ) +guides(color =guide_legend(nrow =5)) +# Place la légende sur une seule lignescale_x_continuous(expand =c(0,0), breaks =seq(1900, 2020, 10)) +scale_color_wsj()gg_mingg_max
(a) Top 5 negative variation between 1900 and 2023
(b) Top 5 positive variation between 1900 and 2023
Figure 6: Prediction of the expected topic proportion according to the year of defence
It’s worth noting that while probabilistic topic models excel at exploratory analysis, they tend to perform less effectively on small textual inputs like titles. However, they demonstrate far greater accuracy and insights when applied to larger text samples, such as abstracts. This is precisely what we’ll explore in our next blog post—stay tuned!
References
Blei, David M. 2012. “Probabilistic Topic Models.”Communications of the ACM 55 (4): 77–84.
Roberts, Margaret E, Brandon M Stewart, Dustin Tingley, Edoardo M Airoldi, et al. 2013. “The Structural Topic Model and Applied Social Science.” In Advances in Neural Information Processing Systems Workshop on Topic Models: Computation, Application, and Evaluation, 4:1–20. 1. Harrahs; Harveys, Lake Tahoe.
Footnotes
Actually some other considerations can lead the choice of the row to keep, such as selecting the row with more extensive information.↩︎
Of course the choice of \(K\) should be determined with greater care; however, starting with \(K = 100\) with 20,000 documents provides a reasonable basis for exploration.↩︎